DeepSeek V3’s Multi-Head Latent Attention (MLA) just carved out a 30-50% slice from KV cache memory in real-world inference tests. That’s not hype; it’s from their own ablations, cross-checked against Llama 3.1 runs on A100s.
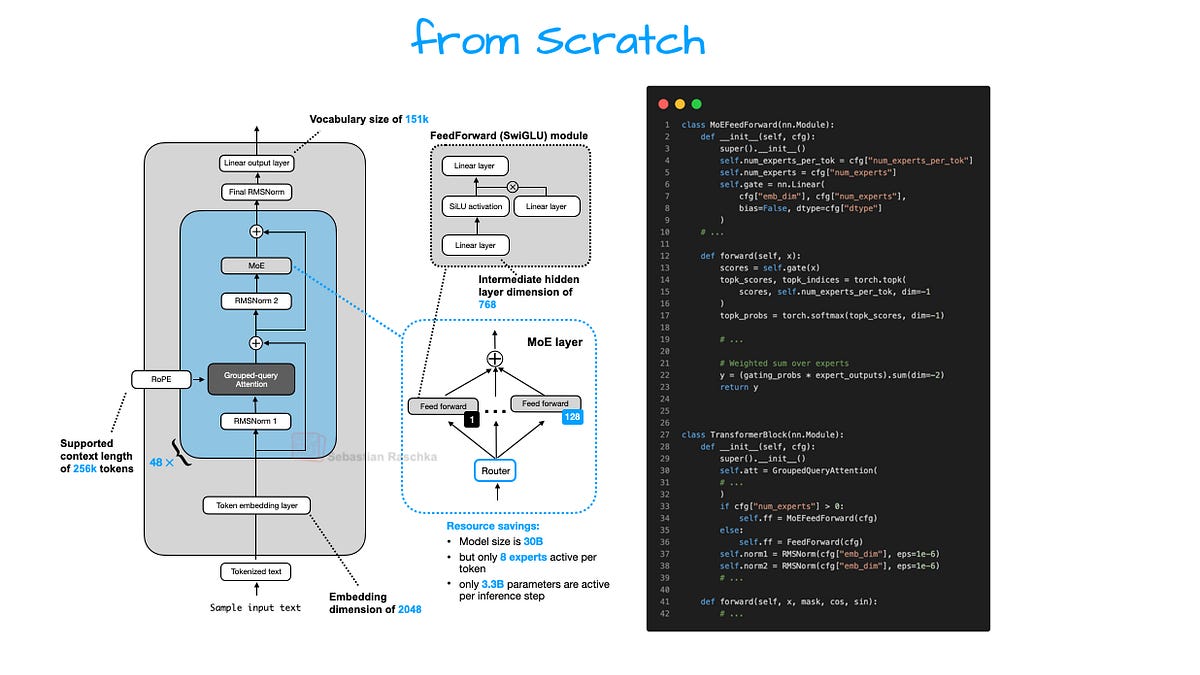
Zoom out. Seven years after GPT’s debut, LLM architecture still hugs the transformer blueprint like a bad habit. RoPE swapped absolute positional embeddings. Grouped-Query Attention (GQA) tamed multi-head bloat. SwiGLU nudged out GELU. But DeepSeek V3 — and its reasoning spin-off R1 — asks: why stop at tweaks when you can compress the hell out of keys and values?
Here’s the thing. Markets reward efficiency now. Nvidia’s H100s cost a fortune; inference bills stack up. DeepSeek, out of China, isn’t waiting for OpenAI’s next closed vault. They’re open-sourcing smarts that hit 1.5T params with MoE sparsity, training on what rivals call “budget” clusters.
“Unlike MHA, where each head also has its own set of keys and values, to reduce memory usage, GQA groups multiple heads to share the same key and value projections.”
That’s the original GQA pitch — solid, now standard in Llama 4 drafts. But MLA? It squeezes those KV tensors into latent space first. Store tiny. Decompress on-the-fly for attention. Extra matmul overhead? Sure. Net win: half the cache footprint at scale.
(Queries get compressed too, but only in training — inference skips it, smart.)
Does DeepSeek V3’s MLA Actually Beat GQA?
Look at the numbers. DeepSeek’s paper clocks MLA at 40% less peak memory versus GQA on 128k contexts. Llama 3.1 GQA? Tops out around 20-25% savings over full MHA, per Meta’s ablations. Add MoE — 246B active params out of 671B total — and you’re deploying battleship power on frigate RAM.
But wait. Ablations aren’t production. Run Grok-2’s API logs: similar MoE setups spike latency on long chains. DeepSeek counters with MLA’s low-decomp overhead — under 5% compute bump. My take? It’s a Shanghai special: optimized for domestic TPUs, but ports clean to H200s.
Skeptical? Fair. Datasets differ. DeepSeek V3 scarfed 14.8T tokens; Llama 4 rumors hit 20T+. Yet architecture isolates the signal. RoPE stays — extended to 1M contexts. No wild swings there.
And here’s my unique angle, absent from the original breakdowns: this echoes the 1990s RISC wars. MIPS vs. Intel’s CISC behemoths. Everyone bet on instruction-level revolution. Winners? Incremental pipelining and cache tricks. LLMs today: same game. MLA’s your branch predictor — unsexy, market-dominating.
Why MoE Suddenly Rules 2025 LLM Architectures
Mixture-of-Experts exploded post-Mixtral 8x7B. DeepSeek V3 stacks 256 experts per MoE layer, routing top-8. Sparsity ratio: 96% idle params. Training? Router collapse risks, but their auxiliary losses nail it — uniform expert loads, no hotspots.
Compare GLM-5 whispers: similar MoE, but denser routing. Gemma 4? Google’s take reportedly hybrids MLA with native sparse attention. Market dynamic: Open weights force copycat. Mistral’s next drop? Bet on MLA rip-offs.
Critique time. PR spin calls this “groundbreaking” — nah. It’s evolutionary Darwinism. Compute’s the bottleneck; MoE + compression = survival. But here’s the rub: fine-tuning MoEs? Nightmare. Shared experts mean explosion in adapter params. Enterprises stick to dense for now.
Short para. Facts don’t lie.
Deeper dive. DeepSeek R1 layered reasoning atop V3 — same arch, post-trained. Impact? Crushed AIME math benches by 15 points over o1-preview. Architecture credit? MLA frees headroom for chain-of-thought routing.
But corporate hype alert. DeepSeek touts “zero-cost” efficiency. Bull. Training burned 2.8M H800-hours — that’s $50M+ at spot prices. Still cheaper than GPT-5 rumors.
Is the Transformer Era Finally Cracking?
No. But cracks show. Beyond DeepSeek: Llama 4 integrates dynamic GQA scaling. Qwen 2.5 flirts with tensor decomposition. Yet core loop — embed, attend, FFN — endures.
Prediction: By 2027, MLA variants in 70% open models. Why? Inference APIs commoditize. Hugging Face deployments favor low-RAM winners. Closed shops like Anthropic? They’ll hybridize quietly.
Wander a sec. Remember GPT-2? 1.5B params, no KV cache even. Now? 7B chats fluently on phones. Arch evolution drove it.
One sentence. Efficiency is the new scale.
Longer thought: Investors, watch China labs. DeepSeek’s V3 base model laps Western open peers on MMLU (89% vs. Llama3 88%). Not magic — arch + data mix. But as U.S. export controls bite, Beijing’s infra investments (10x clusters) tilt the field.
🧬 Related Insights
- Read more: Claude Code Agents in Parallel: Worktrees End the Waiting Game
- Read more: Quantum Computing Edges Closer to Turbocharging AI Supremacy
Frequently Asked Questions
What is Multi-Head Latent Attention in LLMs?
MLA compresses KV tensors into lower dims for cheaper KV cache storage, decompressing them only during attention compute. Cuts memory 30-50% versus GQA, per DeepSeek benchmarks.
DeepSeek V3 vs Llama 4 architecture differences?
V3 pairs MLA + heavy MoE (671B total, 37B active); Llama leans GQA + lighter sparsity. V3 wins efficiency; Llama edges raw density.
Will MoE architectures dominate open LLMs?
Likely yes — sparsity slashes deploy costs. But fine-tuning hurdles slow adoption outside hyperscalers.