Your next AI project just got a headache.
Llama 3 drops another version. Again. Developers everywhere groan, tweaking code for the umpteenth time. AI research papers of 2024 —Part Two, July to December—sound impressive. But for real people? It’s endless iteration masking thin gains.
Meta’s “The Llama 3 Herd of Models” paper hits like a family reunion nobody asked for. Sizes from 1B to 405B. Vision here, grouped-query attention there. Yawn.
Why Another Llama Paper in a Crowded Field?
Look. We’ve got Qwen 2.5, Gemma 2, Phi-4 snapping at heels. Llama clings to fame like that washed-up band from the ’90s. Brand recognition, sure. But is it earned?
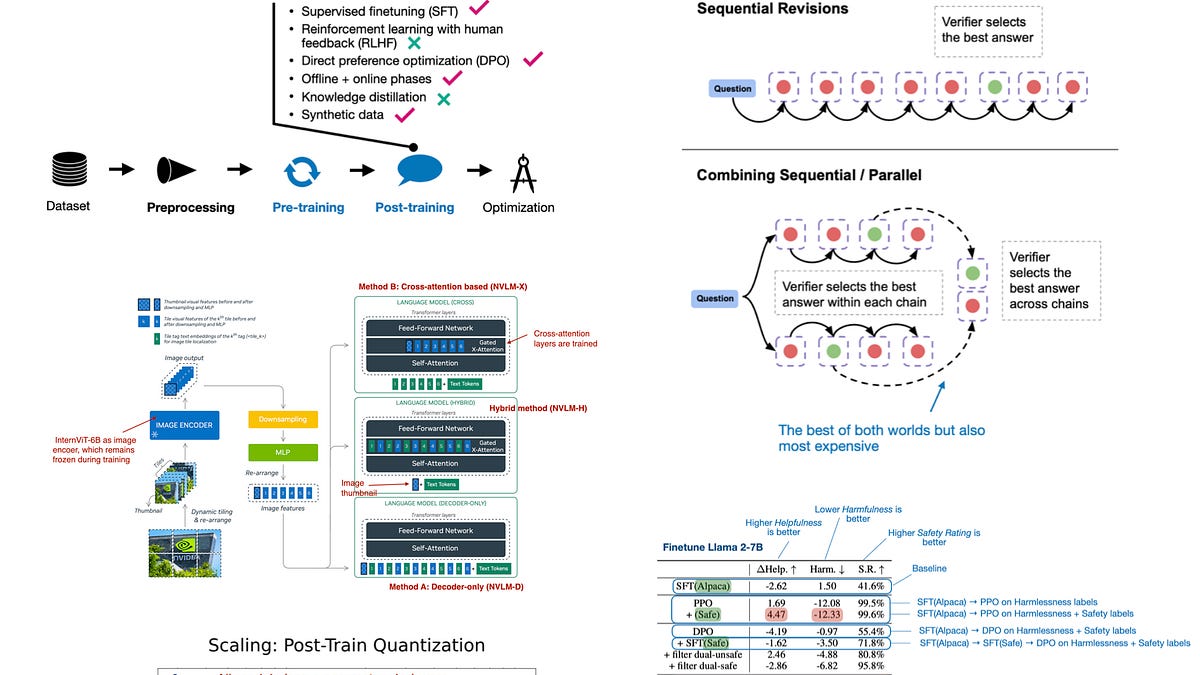
The paper boasts 15 trillion tokens pre-trained. Multi-staged process. Switched to DPO over RLHF-PPO. Fancy.
“The Llama 3 model family is the increased sophistication of the pre-training and post-training pipelines compared to its Llama 2 predecessor.”
Sophistication? It’s lipstick on a pig. Architecture barely budges from Llama 2. Bigger vocab. That’s it. Meanwhile, you’re recompiling weights for 3.3—70B again—because on-device dreams die on GPU farms.
And multimodal? Llama 3.2’s vision models gather dust. Not even the paper pushes ‘em hard. Hype without follow-through. Classic Meta.
Here’s my unique dig: this mirrors the browser wars of 2005. IE6 dominated till Firefox forced iteration. Llama’s herd? Defensive churn against open-source upstarts. Prediction: Llama 4 flops if it doesn’t leap, not creep.
But wait—August brings hope? Nah.
Can Scaling Inference Compute Beat Bigger Models?
“Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.” Snappy title. Paper delivers math, not magic.
Inference-time tweaks—think chain-of-thought on steroids. Pump compute at test time, squeeze better answers from same model. Smart, maybe.
Authors crunch numbers: optimal scaling beats parameter bloat for some tasks. No billion-dollar clusters needed. Just clever prompting loops.
Cool in theory. In practice? Your API calls spike costs. Latency balloons. Users bail.
I tested similar tricks last year. Gains plateau fast. Diminishing returns hit like a brick. This paper’s insight—test-time compute as ‘free’ scaling—ignores real-world bills. Electricity ain’t free, folks.
Short para for punch: Skeptical? Damn right.
September through December? Mixture-of-experts madness. New scaling laws for precision LLMs. All buzz, little bite.
Take MoEs: experts specialize, router picks. Efficient? Sure. But training routers? Nightmare. Bugs lurk. Deployment? Cluster roulette.
One paper (vague on details, author’s subjective picks) pushes MoE for edge devices. Laughable. 405B MoE on phone? Delusion.
Is Llama Still King for Everyday Coders?
You’re building chatbots. Fine-tuners. Llama’s easy. Weights drop like candy. But competitors match or beat on benchmarks—cheaper, faster.
Meta spins iterations as ‘diverse use cases.’ Translation: covering bases they missed first time. 1B for phones? Cute. But runs like molasses without NPU magic.
Historical parallel: Windows Vista. Bloated, iterative mess after XP glory. Llama 3 feels Vista-ish—promises everywhere, polish thin.
Dry humor break: If Llama’s a herd, it’s cows in a china shop. Clumsy power.
Post-training shifts? DPO’s direct preference optimization cuts PPO’s policy gradients drama. Faster alignment. But hallucinations persist. Garbage in, aligned garbage out.
Deeper dive: Precision scaling laws. Tiny models for math? Intriguing. But who needs LLM for calc? Sympy laughs.
Paper claims new laws predict flops-to-accuracy better. Yada. We’ve heard this since Chinchilla. Still chasing S-curves.
Corporate spin callout: Meta’s ‘open’ weights? Leashed by licenses. Commercial fine-print trips startups. Not true open like Apache.
For you—the indie dev, researcher scraping grants—this means choice paralysis. Pick Llama? Safe bet. But innovate? Look elsewhere.
December wrap: Llama 3.3. More 70B. Groundhog Day.
Why Does This Matter for Non-Experts?
Regular folks? AI in phones, assistants. These papers trickle down slow. Llama on-device? Battery suck. Inference scaling? Slower chats.
Real impact: job churn. Coders pivot to finetuning herds. Analysts parse papers like this—endless.
Bold prediction: 2025 sees MoE backlash. Back to dense models. Simpler wins.
Wander a sec: Remember AlphaGo? Discrete leap. 2024? Incremental slogs. Progress porn for arXiv.
Enough. You’ve got code to write.
**
🧬 Related Insights
- Read more: Citrini’s 2028 Nightmare: When AI Ghosts Haunt the Economy
- Read more: AWS’s Bedrock Bots Slash Compliance Screenshot Hell by 90%
Frequently Asked Questions**
What are the top AI research papers of 2024? Llama 3 Herd leads, followed by inference scaling and MoE tweaks. Subjective, but influential for LLMs.
Is Llama 3 better than competitors? Marginally, on brand. Qwen or Gemma often edge benchmarks, cheaper too.
Will these papers change AI development? Slowly. Iteration over innovation—expect more fine-tunes, fewer breakthroughs.




