Imagine you’re that indie game dev, laptop humming late at night, birthing an AI sidekick smarter than your boss’s ChatGPT subscription. No vendor lock-in. No monthly bills skyrocketing to the moon. Just pure, tweakable code.
That’s Qwen3 in your hands — right now.
Why Real People Are Obsessed with Qwen3
Qwen3 isn’t some lab toy. It’s the open-source beast tying proprietary giants on leaderboards, and here’s the kicker: you can fork it, Frankenstein it, make it yours. Dropped by Alibaba’s Tongyi crew in May, juiced up in July, it’s exploding because — drumroll — Apache 2.0 license. No sneaky clauses. Download the 235B Instruct model, and bam, you’re number 8 on LMSYS Arena, neck-and-neck with Claude Opus 4.
But wait. Alibaba just unleashed a 1T-param monster on September 5th, smoking everyone — yet it’s closed for now. Tease? Absolutely. Still, the open versions? From 0.6B dense sprinters to 480B MoE behemoths. Pick your poison based on your GPU prayers.
Folks like us — devs, tinkerers, dreamers — get it. This is the Linux of LLMs. Back in ‘91, Torvalds coded his kernel; suddenly, the web bloomed. Qwen3? Same vibe. My bold call: Expect a Cambrian explosion of niche AIs by 2026, all mutated from this DNA. Not hype — history repeating.
The performance is really good; for example, as of this writing, the open-weight 235B-Instruct variant is ranked 8 on the LMArena leaderboard, tied with the proprietary Claude Opus 4.
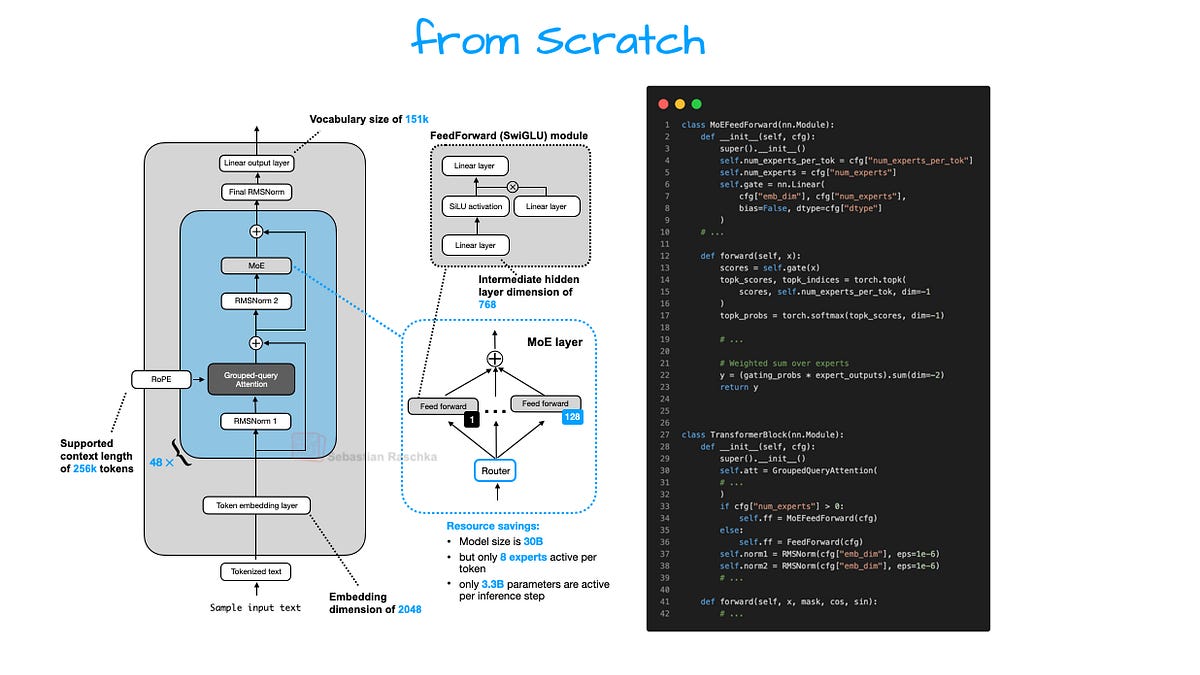
How Does Qwen3 Actually Work? The Magic Sauce
Think of Qwen3 as a bustling city brain — not one mega-processor grinding away, but a swarm of expert neighborhoods lighting up as needed. That’s Mixture-of-Experts (MoE) at play, Qwen3’s secret weapon. In dense models like GPT, every token guzzles the full parameter buffet. Wasteful! MoE? Route smartly: math query to the calculator district, poetry to the bard block. Boom — efficiency skyrockets, scaling to absurd sizes without melting your rig.
But don’t just nod. Let’s crack it open.
Qwen3 builds on tried-true transformers — ya know, attention layers stacking like cosmic pancakes. Embeddings first: turn words into vectors, dense and juicy. Then, rotary positional encodings (RoPE) twist those vectors to scream “this word’s first, dummy!” No more vanilla sins; RoPE scales like a dream.
Here’s the thing. SwiGLU activations? They’re the spicy kick — smoother gradients than plain ReLU, helping massive models train without tantrums. And grouped-query attention? Slashes KV cache bloat, so inference flies even on consumer cards.
Analogy time: It’s like upgrading from a bicycle chain (old attention) to a hyperloop pod (GQA). Zippy. Scalable. Future-proof.
Implementing Qwen3 From Scratch: Your PyTorch Playground
Ready to code? Grab PyTorch, a coffee, and let’s architect this monster. No hand-holding libraries — pure, from-scratch glory. (Pro tip: Fire up Colab if your home setup wheezes.)
Start simple. Embeddings module:
import torch
import torch.nn as nn
class QwenEmbedding(nn.Module):
def __init__(self, vocab_size, embed_dim):
super().__init__()
self.embed_tokens = nn.Embedding(vocab_size, embed_dim)
def forward(self, input_ids):
return self.embed_tokens(input_ids)
Boring? Nah — foundation. Now, RoPE. Twist positions into complex planes. Libraries exist, but roll your own:
def apply_rotary_emb(xq, xk, freqs):
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
xq_out = torch.view_as_real(xq_ * freqs).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
Feel that power? You’re embedding the universe’s geometry.
Stack attention. Qwen3 uses GQA: multi-head for queries, fewer for keys/values. Cuts memory like a hot knife.
Full transformer block? RMSNorm pre-attention (stable as a rock), then self-attn, then FFN with SwiGLU. MoE twist: Instead of fat FFN, gate to 8-32 experts. Router learns on-the-fly: “Yo, token 42, hit expert #7.”
Coding the router — top fun. Noisy top-k gating: Sample experts softly, train end-to-end. Here’s skeleton:
class MoERouter(nn.Module):
def __init__(self, num_experts, num_experts_per_tok):
super().__init__()
self.gate = nn.Linear(in_features, num_experts)
self.num_experts_per_tok = num_experts_per_tok
def forward(self, hidden_states):
logits = self.gate(hidden_states)
weights = F.softmax(logits, dim=-1)
topk_weights, topk_ids = torch.topk(weights, self.num_experts_per_tok)
return topk_weights, topk_ids
Whew. Wire 60+ blocks, final LM head (tied embeddings for param thrift), and train on The Pile or your data. Pretrained weights? Hugging Face has ‘em — Qwen/Qwen3-0.5B or scale up.
But why bother? Insight: This ain’t toy code. It’s your exoskeleton. Tweak MoE count for edge deploys. Fuse experts for speed. Birth Qwen3-Jr for your IoT dreams.
Is Qwen3 Really Better Than Closed-Source Rivals?
Benchmarks scream yes — for open weights. Arena Elo? Crushing. MMLU? Neck-and-neck. But real talk: hallucinations lurk, like all LLMs. Instruction-tuning shines in chat, code gen. Edge over Llama? MoE efficiency; runs leaner at scale.
Critique time. Alibaba’s PR spins the 1T close-source as “max,” but that’s gatekeeping whack-a-mole. Open the floodgates fully, folks!
Why Developers Can’t Ignore This
You’re not just cloning. You’re learning AI’s guts. Debug attention drift. Profile router balance (hint: load imbalance kills perf). Experiment: Add vision mixer? Qwen-VL vibes.
Prediction: By Q4 2025, Qwen3 forks dominate custom agents. Like Android crushed Symbian.
Short para. Boom.
This from-scratch path? Demystifies the black box. AI shifts to platforms — platforms you command.
🧬 Related Insights
- Read more: SageMaker Serverlessly Crushes Agent Tool Hallucinations
- Read more: Amazon Nova Act: Agents That See Like Humans, Not Code—But Do They Deliver?
Frequently Asked Questions
What is Qwen3 and why is it popular?
Qwen3 is Alibaba’s open-source LLM family, from 0.6B to 480B params, topping charts with MoE smarts and Apache license freedom.
How do I implement Qwen3 from scratch in PyTorch?
Start with embeddings, RoPE, GQA attention, SwiGLU FFN, then MoE layers. Full code blocks above; load HF weights to finetune.
Does Qwen3 beat GPT-4 or Claude?
Open versions tie/rival on benchmarks; 235B matches Claude Opus 4. New 1T closed model crushes all — watch for open release.


