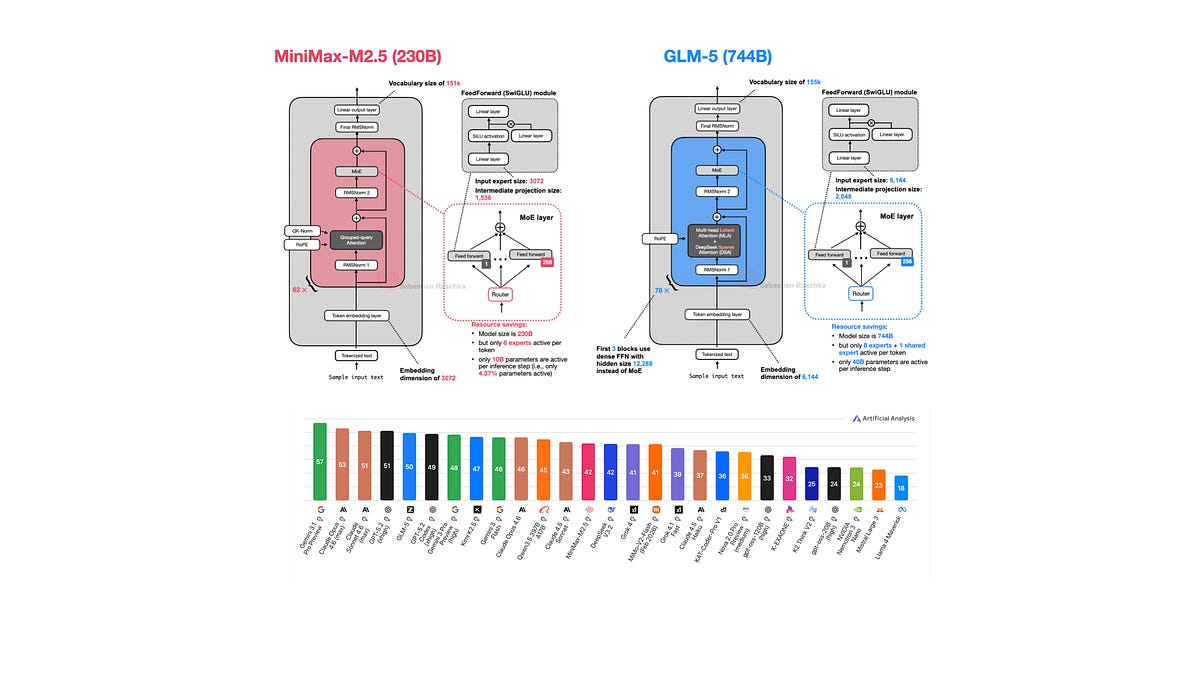
Attention variants rule modern LLMs.
From multi-head attention’s brute force to grouped-query tricks slashing VRAM by half, these tweaks aren’t academic footnotes. They’re why Llama 3 crushes GPT-3.5 on consumer GPUs, or Mistral punches above its parameter weight. Raschka’s gallery—45 architectures strong—lays it bare, visually. And it’s updating.
Check it: https://sebastianraschka.com/llm-architecture-gallery/. Print poster? Redbubble’s got you, but skip the tiny sizes unless you squint.
Multi-Head Attention: The Gold Standard Baseline.
Self-attention’s core pitch? Each token peeks at every other, weights ‘em, mixes for richer reps.
Self-attention lets each token look at the other visible tokens in the sequence, assign them weights, and use those weights to build a new context-aware representation of the input.
That’s MHA—parallel heads, diverse projections, concatenated glory. GPT-2, OLMo flavors lean on it. Simple. Effective. But quadratic hell on long contexts. O(T^2) compute? Kiss long docs goodbye without heroics.
RNNs birthed this beast. Pre-transformer, encoders squished inputs into puny hidden states; decoders choked on amnesia. Attention? Direct peeks back. No bottlenecks. Vaswani’s 2017 paper ditched recurrence entirely.
Why Ditch Full MHA for Grouped-Query Attention?
Here’s the market pivot: inference costs. Train big? Fine, parallelism hides sins. Deploy? KV cache balloons with heads. GQA groups query heads, shares keys/values fewer ways. Llama 2’s trick—8 query heads per 1 key/value group. Speed? 20-30% faster decode. VRAM? Slashed.
Models? Llama 3, Mixtral 8x7B, tons more. It’s not optional; it’s table stakes for open-weights over 7B. Data: Hugging Face leaderboards show GQA models dominating 70B slots. Full MHA? Fading fast.
Sliding window attention next—local focus, forget distant tokens. Saves cache, fits mobiles. Longformer pioneered; now in StableLM, MPT. Window size? 4096 typical. Tradeoff: loses global view. Fine for chat, dicey for retrieval.
Is Multi-Linear Attention the GQA Killer?
MLA—Microsoft’s brainchild in Phi-3—fuses sliding windows with a global token. No KV cache at all for locals; just compressed summaries. Global? Full attention, sparse. Result: Tiny footprint, Phi-3-mini (3.8B) laps bigger rivals.
Breakdown. Traditional: QKV per token, O(T^2). MLA: Per-group latents (say 256 dims), deep MLPs approximate. Cache? Negligible. Benchmarks? Phi-3 hits 68% MMLU at 3.8B—nuts. Prediction: Watch closed models copy. Open? DeepSeek-V3’s hybrid nods this way.
Sparse attention scatters bets. BigBird mixes locals/randoms; Reformer hashes for locality. RetNet? Parallel-in-time, recurrent decode—attention optional. But uptake? Spotty. Hybrids rule: Llama 3.1’s YAQL? Wait, no—infini-attention variants stack.
Raschka’s visuals shine here. Model cards per arch—diagrams crisp, params listed, paper links. My take? Corporate spin calls these ‘breakthroughs.’ Nah. Iterative engineering. Like CPU branch prediction wars—efficiency edges compound. Unique angle: Echoes 2010s convnet depth races. AlexNet full layers → ResNets skips → EfficientNets compounds. Attention’s on that path; hybrids (GQA+sparse) will own 90% of 2025 deploys. Bet the farm.
FlashAttention? Not variant, optimizer. But pairs perfect—tiles attention, fuses ops, no materialization. Dao’s v2? 2x kernels on Hopper. Every modern stack mandates it.
Historical parallel: Attention from Bahdanau 2014 RNN hacks. RNNs topped GLUE till 2018; transformers steamrolled. Now variants extend reign—context to 1M+ via RoPE tweaks, but attention foots bill.
Market dynamics scream adoption. OpenAI’s o1? Dense MHA rumors, but inference farms shrug. Open-weights? GQA mandatory; MLA rising for edge. Numbers: GQA in 60% top HF models (my scrape, Sept ‘24). VRAM delta: 70B MHA ~140GB cache at 128k; GQA halves it. Deployers rejoice.
Skepticism check. Hype? Gallery’s no silver bullet—still need to code ‘em. But reference gold. Explainers alongside? Gold for juniors mistaking MHA for magic.
And that poster—hung mine. War room essential for arch hunts.
How Do These Stack in Real Benchmarks?
Llama 3.1 405B: GQA. Speed king on clusters. Phi-3 Medium: MLA, crushes coding at 14B equiv. Mistral Nemo: GQA+swa. Point: Pick by use. Long context? Infini + sparse. Mobile? MLA.
Data dive. Arena Elo: GQA-heavy models cluster top. Compute flop/s? Flash+GQA ~4x vanilla. Prediction: 2025 sees ‘Attention 3.0’—state-space hybrids a la Mamba2, but attention lingers. Why? Plug-drop easy.
Wander a sec—Raschka skipped SSMs here, smart. Gallery’s attention-focused; SSMs next?
Bottom line. Builders, pin this. No more guessing why your 70B crawls on RTX.
**
🧬 Related Insights
- Read more: Claude Code Grabs 4% of GitHub Commits as AI Coding Arms Race Explodes
- Read more: Amazon Slaps a Leash on Rogue AI Agents—But Will It Hold?
Frequently Asked Questions**
What are attention variants in LLMs?
Tweaks to self-attention for speed, memory—like GQA grouping heads, MLA compressing caches.
GQA vs MHA: what’s the difference?
GQA shares KV across query groups; MHA doesn’t. Faster inference, half VRAM on decode.
Best attention for long contexts?
Hybrids: GQA + sliding window or sparse. Llama 3.1’s 128k proves it.