Real people—indie devs scraping by in garages, small teams dodging OpenAI bills—finally get a fighting chance against the trillion-dollar labs. These 10 open-weight LLMs from Jan-Feb 2026 aren’t locked behind APIs; download ‘em, tweak ‘em, run ‘em on your cluster. But here’s the cynical truth after 20 years watching this circus: most’ll gather dust because your home rig can’t touch a 400B beast without melting.
Look, if you’re not swimming in H100s, this ‘dream of spring’ feels more like a hardware sales pitch. Big winners? Nvidia. Everyone else chases shadows.
Who’s Flooding the Zone with Open Weights?
Ten drops in six weeks. Arcee AI kicks it off Jan 27 with Trinity Large, a 400B MoE monster. Same day, Moonshot AI’s Kimi K2.5 scales DeepSeek vibes to 1T params. StepFun’s Step 3.5 Flash zips in Feb 1. Qwen3-Coder-Next for code nerds on Feb 3. z.AI’s GLM-5 and MiniMax M2.5 twin on Feb 12. Nanbeige’s tiny 4.1 3B Feb 13. Qwen 3.5 Feb 15. Ant Group’s Ling and Ring 2.5 1T duo Feb 16. Cohere’s Tiny Aya caps it Feb 17. Sarvam’s giants sneak in March.
It’s a stampede. Chinese labs dominate—Qwen, Moonshot, Ant—pumping out behemoths like it’s a parameter arms race. US upstarts like Arcee play catch-up. But who foots the training bill? Not you or me.
And yet.
This frenzy echoes 1995’s browser wars—Netscape drops first, Microsoft copies, everyone fragments on tiny tweaks. By 1998? IE crushes all. Today’s MoE tweaks feel just as futile; DeepSeek’s blueprint rules, others just gild the lily.
Arcee AI’s Trinity Large: US Grit or MoE Clone?
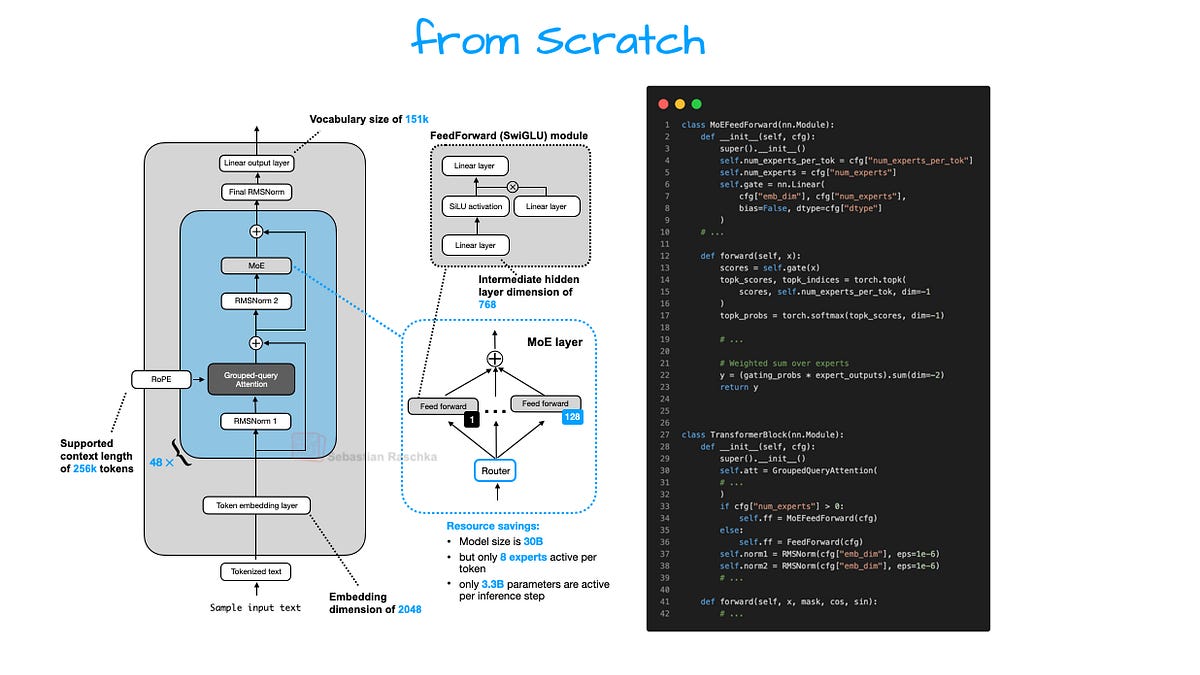
Arcee, some San Francisco newbie I missed till now, unleashes Trinity Large: 400B params, 13B active in MoE mode. Smaller siblings: 26B Mini, 6B Nano. They drop a GitHub report (arxiv soon after) spilling guts—nice touch, rare these days.
Their flagship large model is a 400B param Mixture-of-Experts (MoE) with 13B active parameters.
That’s the hook. But peek inside: sliding window attention (SWA) alternating local-global, 3:1 ratio like Olmo 3, 4096-token windows. QK-Norm for stable keys/queries. NoPE in globals. Gated attention a la Qwen3-Next. Four RMSNorms per block, depth-scaled gains—Gemma 3 vibes with a twist.
MoE? DeepSeek-style, coarsened for speed, Mistral 3 echoes. Matches GLM-4.5 base perf, they claim. Bold, since fine-tunes rule benchmarks now.
Impressed? Nah. It’s a Frankenstein of 2025 hits. Solid engineering, sure—but revolutionary? Please. Arcee’s betting open weights lure enterprise escapees from Claude. Smart. But they’ll need inference magic to compete.
Here’s the thing—training tweaks like MuOpt optimizer scream ‘we barely made it.’ Load-balancing hacks? Been there since Mixtral.
## Will Chinese MoEs Bury Western Open Models?
Moonshot’s Kimi K2.5: 1T scale, DeepSeek clone. StepFun’s Flash: speed demon. Qwen3-Coder-Next: dev-focused, naturally.
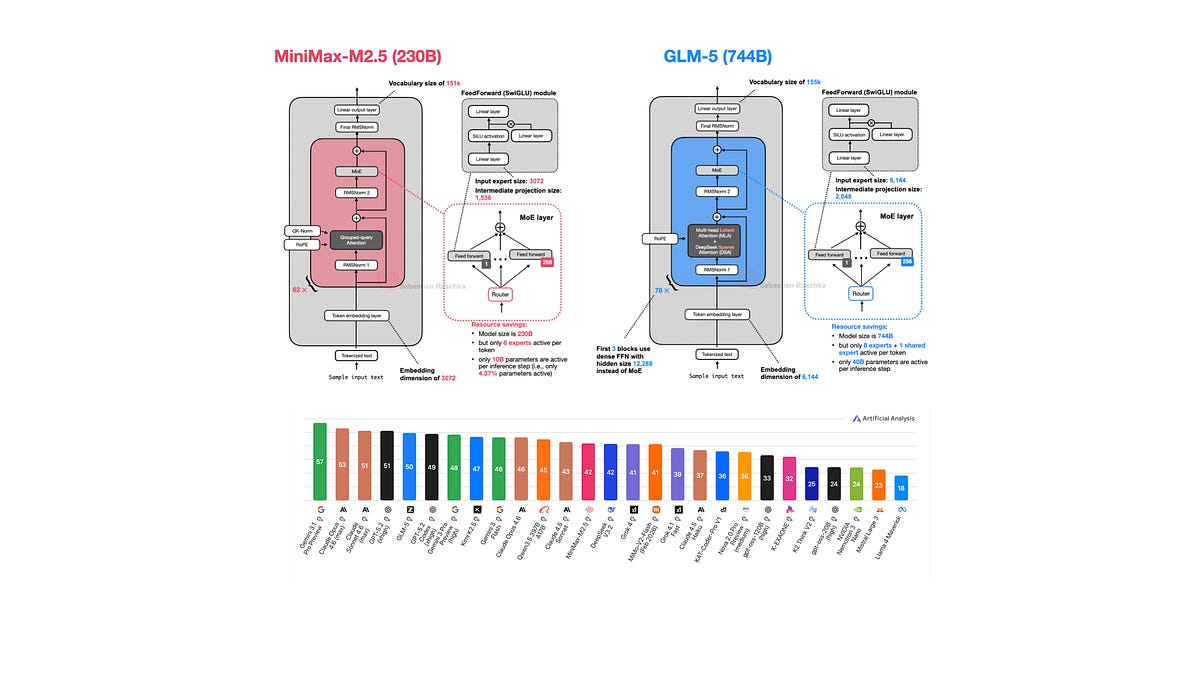
z.AI’s GLM-5, MiniMax M2.5—Feb 12 twins, both massive MoEs with long-context wizardry. Nanbeige 4.1 3B: proof small can punch (if quantized right). Qwen 3.5 refines the family recipe. Ant’s Ling/Ring 2.5 1T: multimodal? Wait, no—pure scale plays.
Cohere’s Tiny Aya: lightweight champ, 17 languages baked in. Sarvam’s 30B/105B: Indian muscle, post-cutoff but fitting the wave.
China’s churning these like EVs—cheap compute, state-backed? Converging on SWA, QK-Norm, gated attns, DeepSeek MoEs. It’s not innovation; it’s iteration at warp speed.
Bold prediction I won’t find elsewhere: by 2027, this fragments into ‘MoE standards’—like HTTP for browsers. Winners standardize first. Losers? Fork hell.
The Money Trail: Follow the GPUs
You’re thinking, ‘Great, free models!’ Wrong question. Who’s cashing in?
Cloud giants—AWS, Azure—host your fine-tunes. Nvidia sells the picks. Labs like Qwen recoup via APIs or enterprise deals (open weights as loss-leaders).
Real people win tiny: tinkerers quantize Nano/Trinity Mini for laptops. Run local RAG? Possible now. But 400B? Rent it. Monthly.
Skeptical vet take: this ‘spring’ thaws nothing fundamental. Hardware walls persist. Power bills spike. And when DeepSeek V4 lands? Reset.
But damn, the reports are gold—Arcee’s especially. Study ‘em. Build on ‘em. That’s the play.
Why Does Open-Weight Momentum Matter for Indie Devs?
Indies, listen. Closed LLMs charge per token—your chatbot scales to bankruptcy. Open weights? One-time download, infinite inference (hardware permitting).
Qwen3-Coder-Next? Paste your repo, iterate offline. Tiny Aya? Multilingual apps sans latency tax.
Catch: eval ‘em yourself. Benchmarks lie—corporate fine-tunes juice leaderboards. Raw bases? Trinity ties GLM-4.5, they say. Test on your data.
Wander a bit: remember Llama 1? Hype tsunami, then crickets for most. Don’t sleep—quant tools evolved. GGUF these bad boys.
🧬 Related Insights
- Read more: AWS Frontier Agents: Autonomous Saviors or Expensive Hype?
- Read more: AI Anxiety in 2026: Blame Policy, Not the Bots
Frequently Asked Questions
What are the top open-weight LLMs from early 2026?
Arcee Trinity Large (400B MoE), Moonshot Kimi K2.5 (1T), Qwen 3.5 lead pack. Pick by size/use: coders grab Qwen3-Coder-Next; lightweights, Tiny Aya or Nanbeige 3B.
Can I run 2026 open LLMs on consumer hardware?
Small ones (3B-26B quantized)? Yes, on RTX 4090. 400B+? No—need clusters or cloud. Start with Trinity Nano.
Which 2026 LLM architecture should developers adopt?
DeepSeek-like MoE with SWA/QK-Norm. Trinity or Qwen 3.5 bases. Fine-tune, don’t chase param counts.