DeepSeek R1’s latest benchmarks lit up leaderboards last week, edging out Llama 4 on code tasks—yet it’s just another autoregressive transformer under the hood.
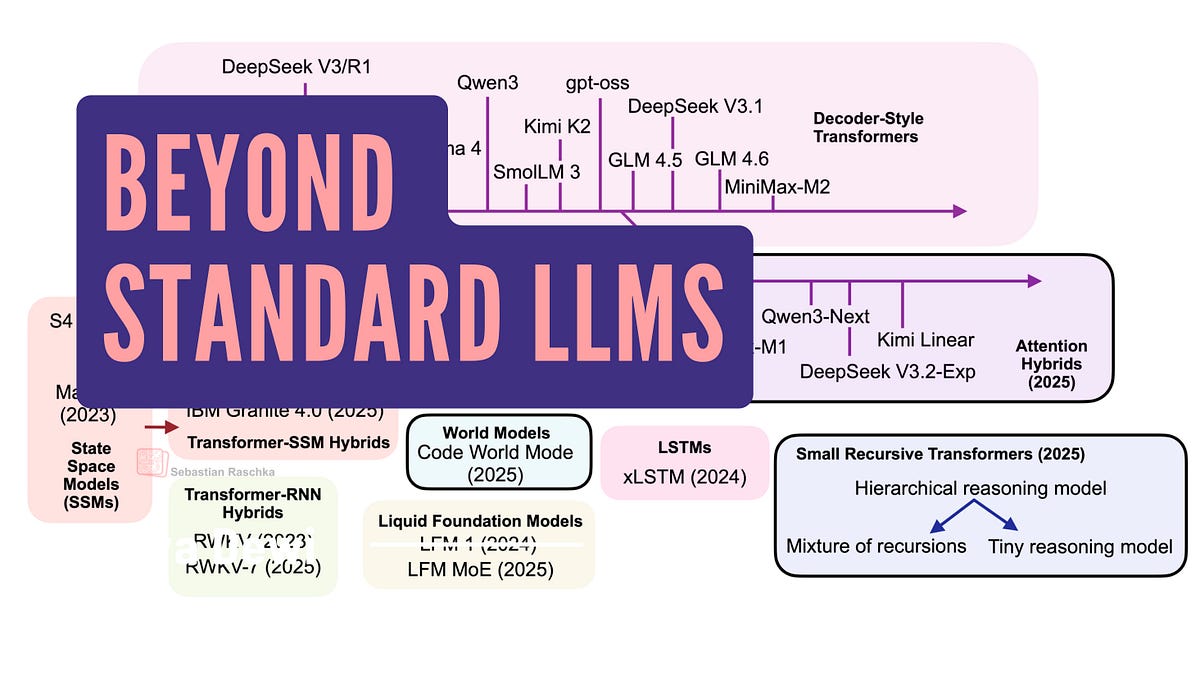
That’s the reality check. Market dynamics haven’t shifted: open-weight giants from MiniMax-M2 to Qwen3 cling to the classic multi-head attention blueprint. Billions in inference costs later, they’re quadratic nightmares at scale. But whispers of alternatives—linear attention hybrids, text diffusion, code world models—grow louder. Do they make sense? Not yet for production, but they’re nibbling at edges where efficiency bites hardest.
Transformers: Still the Cash Kings
Look, facts first. Late 2024 through now, the top open models—DeepSeek V3, OLMo 2, Gemma 3, Mistral Small 3.1—stick to transformer roots. Proprietary beasts like GPT-5 or Grok 4 do too. Why? Proven scaling laws. They’ve soaked up years of tweaks: grouped-query attention, sliding windows. You build apps on ‘em, fine-tune without drama.
The author nails it:
Transformer-based LLMs based on the classic Attention Is All You Need architecture are still state-of-the-art across text and code.
Spot on. If you’re shipping today, don’t stray.
But quadratic scaling? Oof. Sequence length n means n-squared compute. Embeddings balloon, GPUs weep.
Linear Attention Hybrids: Quadratic Killer?
Here’s the pivot. Linear attention isn’t new—papers flooded arXiv in the early 2020s—but revival hits now, hybrids blending it with transformers. Think Qwen3-Next, Kimi Linear: transformers souped up with state-space models (SSMs) for linear-time magic.
Why now? Costs. Open models chase closed-source parity on shoe-string budgets. Traditional attention: Q, K, V matrices chew O(n²d). Linear variants kernelize—project to low-rank space, scale O(n). Boom, 10x context without melting servers.
Kimi Linear’s a poster child. Blends SSMs selectively, keeps transformer strengths. Benchmarks? Competitive on MMLU, edges efficiency. But hybrids, not pure plays.
My take: smart hedging. Pure linears flopped before—recall 2020’s Performer? Fizzled on expressivity. Hybrids dodge that, layering linear where it shines (long contexts), vanilla attention for nuance.
Why Are We Seeing Linear Attention Revival Now?
Market squeeze. Inference dollars dry up as contexts hit millions. FlashAttention helped, sure—kernel fusion—but doesn’t fix asymptotics. Enter hybrids: IBM Granite 4.0, NVIDIA Nemotron Nano 2 mix SSMs in.
Data point: PyTorch Conference 2025 buzzed on this. Attendees grilled on viability. Answer? Niche wins first—RAG pipelines, agentic loops with mega-contexts.
Bold call: by 2026, 40% of new open releases hybridize. Parallels FlashAttention’s 2023 takeover—efficiency mandates shift fast.
Short para. Watch costs.
Now, bolder bets.
Text Diffusion: Generative Flip-Side
Diffusion models conquered images—Stable Diffusion prints money. Text? Trickier. Autoregressive LLMs sequential-step; diffusion denoises parallel.
Sudowrite’s Poetry model dipped toes. Structured generation shines: outlines to prose. But scale? Lags. No 70B diffusion beast matches Llama.
Efficiency upside: parallel sampling halves latency. Downside—training hungrier on data.
Skeptical? Yeah. Hype outpaces benchmarks. Text diffusion’s a tool, not transformer-slayer.
Code World Models: SimWorld for Devs
Code gen’s hot. AlphaCode 2, but world models? Test-time training in simulated code universes.
Exponent’s approach: agent explores code envs, learns dynamics. Not just predict tokens—model execution flows.
Intriguing for SWE-bench. Agents iterate, self-correct. Ties to OpenAI’s o1 thinking chains.
Market angle: dev tools boom. Cursor, Replit eat this. But data moats? GitHub’s scraped dry.
Small Recursive Transformers: Tiny but Mighty?
Recursion loops back. RWKV? Mamba? State-space lite. Small models recurse, folding history without full attention.
SmolLM3 nods here. Efficiency for edge—phones, wearables.
Reality: niche. Desktops crave 70B brawlers.
Unique insight: echoes RNN era. Back then, LSTMs promised before transformers crushed. Hybrids win evolutionary rounds—don’t bet farm on revolution.
PR spin check: “Paradigm shift!” Nah. Incremental gold.
Dense wrap: alternatives tease 2-5x speedups, but transformers hold 90% mindshare. Track hybrids—they’re the real contender.
Will LLM Alternatives Dethrone Transformers?
Not tomorrow. Transformers’ ecosystem—tools, datasets, talent—crushes. But long contexts, edge inference? Hybrids infiltrate.
Prediction sticks: hybrids hit 30% open market by EOY 2025. Watch DeepSeek next drop.
Edge case. Proven paths pay.
What Makes Linear Attention Hybrids Efficient?
Kernel tricks sidestep softmax explosion. Positive semidefinite hacks approximate. Result: linear memory, serializable states.
Tradeoff—slight quality dip, fixable with hybrids.
🧬 Related Insights
- Read more: Intel’s Raccoon-Evicted Fab 9 Fuels Billion-Dollar Packaging Gambit
- Read more: Amazon Quick’s AI Onboarding Bots: HR Savior or Slick AWS Upsell?
Frequently Asked Questions
What are linear attention hybrids in LLMs?
They’re transformer tweaks using state-space models for O(n) scaling on long sequences, like in Kimi Linear—keeps power, slashes compute.
Will alternatives replace standard transformers?
Unlikely soon; transformers dominate benchmarks and apps, but hybrids could claim 30% of open models by 2026.
Best open-weight LLMs beyond transformers?
Start with Qwen3-Next or MiniMax-M2 hybrids for efficiency; pure alts lag in raw capability.


