Back in the day, when GPT-3 dropped, folks gawked at those endless replies like it was wizardry. Smooth prose, zero lag—or so the demos sold. But hit a long chat? Stutters. Costs skyrocket. Now, dig into prefill, decode, and the KV cache in LLMs, the gritty pipeline everyone’s glossing over. This isn’t fluff; it’s why your API bills explode on long convos.
Expectations? Magic. Reality? Two-phase grind: prefill chugs the whole prompt parallel-fast, decode spits tokens serially, KV cache pretends recompute’s optional. Changes everything—scales chats, tanks latency for shorties, murders VRAM for novels.
What the Hell Is Prefill, Anyway?
Picture typing ‘Today’s weather is so…’ Model doesn’t dawdle token-by-token like a drunk typist. Nope. Prefill? Parallel blitz. Every token peers back at priors via attention, all at once. GPU feasts on matrix math, spits contextual gold for the first reply token.
Original tutorial nails it:
During prefill, the model processes the entire prompt in a single forward pass. Every token attends to itself and all tokens before it, building up a contextual representation that captures relationships across the full sequence.
That’s your prompt—100k tokens? Causal mask blocks peeks ahead, tensor ops fly. No step-wise slog.
But here’s the cynicism: Silicon Valley peddles ‘infinite context’ dreams, yet prefill’s parallel bliss shines short. Long prompts? Memory balloons before token one.
Short answer? Prefill’s the sprinter. Sets the stage.
And decode? The marathon.
Decode Phase: Why It’s a Serial Snooze
First token pops. Great. Now? Repeat—for every next word. Each new guy attends to prompt plus all prior generations. Without smarts, you’d re-prefill the growing mess each time. Catastrophic. Latency stacks linear; a 1k-token reply? 1k passes.
Toy example from the piece: ‘Today’ (10), ‘weather’ (20), ‘is’ (1), ‘so’ (5). Attention heads—simplified rules like ‘even positions’ or ‘last token’—blend values. Real heads? Learned chaos, but parallel in prefill, serial here.
Causal mask again: lower triangle true, blocks futures.
tensor([[ True, False, False, False],
[ True, True, False, False],
[ True, True, True, False],
[ True, True, True, True]])
Decode leans on that mask, adds one column/row per token. Brutal without hacks.
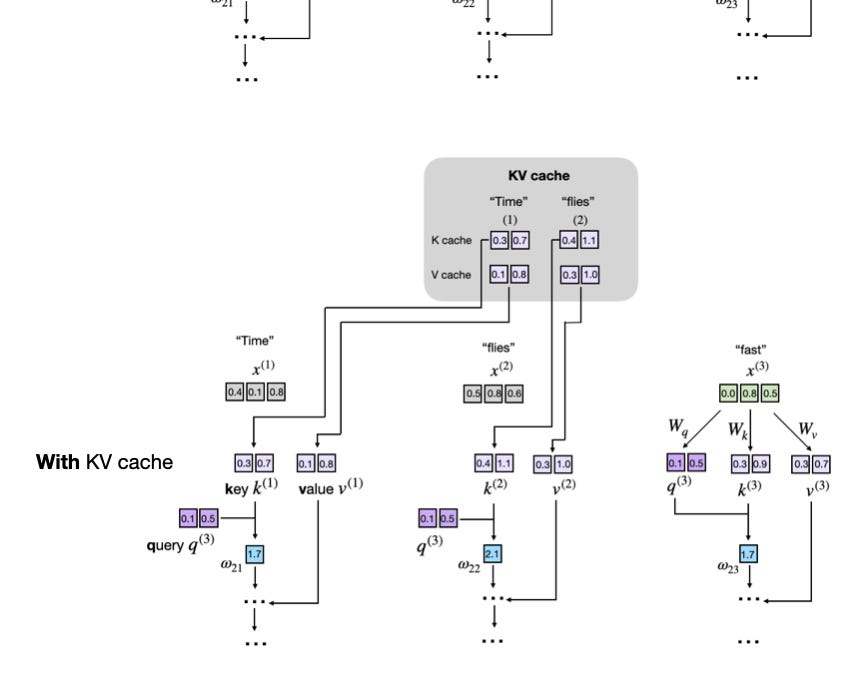
KV Cache: Efficiency Hack or VRAM Vampire?
Enter KV cache. Keys (K), Values (V) from attention? Stash ‘em. New token queries the cache—no recompute full history. Append only. Boom: decode’s O(1) per token-ish, not quadratic hell.
How the KV cache eliminates redundant computation to make decoding efficient.
Essential for ‘long responses at scale,’ sure. But my hot take—the one headlines miss: this mirrors 90s database woes. Remember query caches bloating RAM? Same trap. LLMs hoard KV per layer/head/sequence. 1M context? Petabytes potential. NVIDIA laughs to the bank; H100s guzzle like teens at prom.
Historical parallel: seq2seq RNNs pre-Transformer crawled serial everything. No cache needed—tiny contexts. Transformers scaled via parallelism + cache, birthed ChatGPT. Prediction? FlashAttention variants chop KV bloat 50%, but until then, enterprises rent server farms. Who’s paid? Not you, free-tier sucker.
Parallel prefill? KV starts empty, fills once. Decode appends. Simple. Genius? Debatable—it’s bandaiding attention’s O(n^2) soul.
Why Does KV Cache Matter for Your Wallet?
Inference costs? 90% decode for chats. Prefill’s one-shot; rest’s cached grind. Long threads? Cache swells, eviction policies kick in (truncate oldies), quality dips.
Skeptical vet view: OpenAI won’t admit, but Grok/xAI hype ‘long context’ while dodging cache costs. Real money? Hyperscalers. AWS, Azure—bill per token and GPU-hour. KV cache lets ‘em serve billions, pocket trillions.
Toy numbers: Llama 70B, 80 layers, 64 heads, d_k=128. KV per token: ~2 * 70B * 128 / 1e9 GB? Wait, per seq. Scales linear. 100k ctx? Dozens GBs. Multi-user? Sharding hell.
Is Prefill-Decode Split a Flaw or Feature?
Flaw, mostly. Ideal? Full parallel gen. Causal forces serial. Research chases speculative decode—guess ahead, verify. But errors cascade.
Changes things? Devs optimize now: quantize KV (4-bit), evict heads. Tools like vLLM swap caches smart. Users? Shorter prompts, baby.
Cynical truth: Buzzword ‘autoregressive’ hides the grind. Marketers spin ‘instant AI’; engineers sweat caches.
Look, 20 years watching Valley: Hardware eats software dreams. KV cache buys time—till quantum or sparse moats it.
Who’s Actually Cashing In Here?
NVIDIA, duh. H100s optimized for exactly this: fat HBM for KV hoards. Inference clusters? Their moat. Startups? Lease or die.
Bold call: By 2026, cache-compression ASICs flip tables. Cerebras/Graphcore analogs win inference wars. Open-source? Hugging Face et al democratize, but clouds skim 70%.
PR spin? ‘Scaling laws forever!’ Nah. Cache is the chokehold.
🧬 Related Insights
- Read more: Perplexity Computer: Your Second Brain or Just Clever Note-Taking?
- Read more: Meta’s $14 Billion AI Launch: 200 Jobs Axed, Savings a Meager 2.5% – The Real Math Behind the Madness
Frequently Asked Questions
What is prefill vs decode in LLMs?
Prefill processes full prompt parallel for context. Decode generates one token at a time, using cache.
How does KV cache work in LLM inference?
Stores past Keys/Values. New tokens query without recomputing history—cuts time, spikes memory.
Why is KV cache a bottleneck for long LLM contexts?
Linear memory growth per token/layer. Hits GPU limits fast; needs tricks like paging or quantization.