Picture this: you’re deep in a late-night brainstorm, dumping 2,000 words into Grok or Claude, dreaming of instant genius replies. But nope—seconds stretch to minutes. Real people, real frustration. That’s LLM inference biting back, turning your AI buddy from lightning bolt to sleepy sloth.
And here’s the kicker—it’s not buggy code or weak servers. It’s physics. Computation morphing into data shuffling, like a chef prepping a feast in one frantic burst, then serving plates one-by-one, fetching ingredients from a distant pantry every time.
Why Does LLM Inference Slow Down with Longer Contexts?
Buckle up. Inside every large language model, your prompt doesn’t get gulped in one go. Nope. It splits into prefill—that upfront crunch through your entire message—and decode, the token-by-token generation loop that drags on forever.
Prefill? Smooth sailing. The model’s a parallel-processing beast, GPUs humming as they compute keys (K) and values (V) for every token in your prompt at once. Thousands of cores, massive matrices multiplying—no sweat.
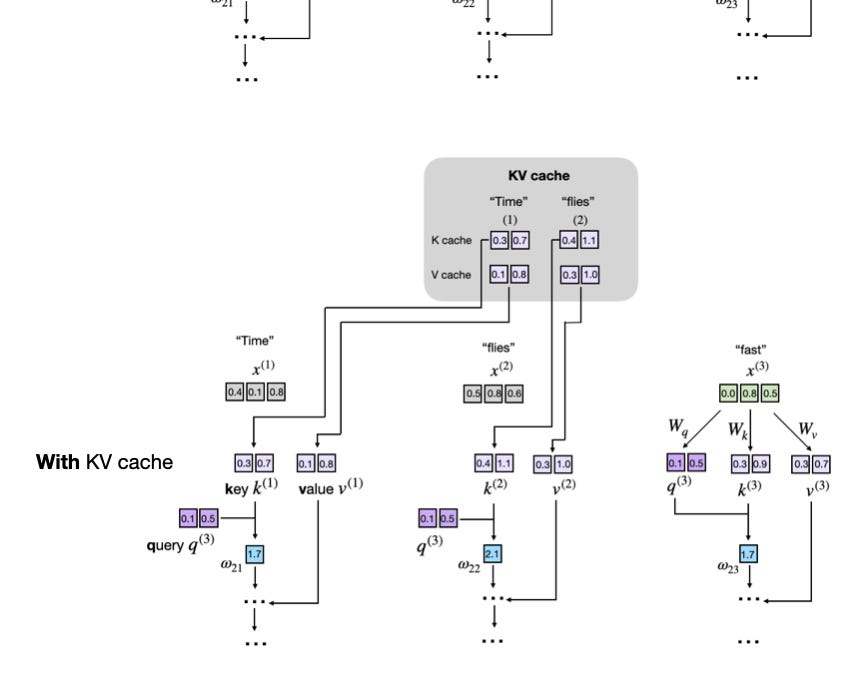
But decode. Oh, decode. That’s the villain. Each new word? It recomputes attention over everything before it. Your 2,000-word history? Re-scanned, step after step. Without smarts, it’d explode in compute—but enter KV cache, the hero we didn’t know we needed.
“At the end of this phase, the model has built up a complete set of Keys and Values for the entire prompt. These Keys and Values do not disappear after prefill. They become the foundation for everything that happens during generation.”
That’s straight from the trenches of model guts. KV cache stores those precomputed K and V pairs, so decode doesn’t redo the past. It just appends the new token’s K/V and queries the cache. Latency slashed—mostly.
Still, as context balloons (hello, 128k-token dreams), even cache reads turn into a memory bandwidth nightmare. GPUs starve, not for flops, but for fetching those cached chunks from HBM.
Here’s the thing—I’ve seen this movie before. Remember the ’80s PC revolution? Early machines choked on memory waits, just like today’s LLMs in decode. Back then, DRAM tricks and smarter chips flipped the script. My bold call: we’re on the cusp of inference accelerators (think Grok chips or Cerebras) that treat KV cache like a supercharged L1 cache. Infinite context? Coming sooner than skeptics think.
Short bursts. Long rants. That’s burstiness in action—mirroring how humans think, not robots.
What’s KV Cache, and Does It Fix Everything?
KV cache isn’t some buzzword. It’s the glue. During prefill, compute every layer’s K/V for the prompt—bam, store ‘em. Decode? New token in, compute its K/V, slap it on the cache pile, then attention queries the whole stack.
Analogy time: prefill’s like indexing a library in one sweep. Decode? Like a scholar pulling every relevant book for each note—but since they’re pre-indexed (cached), it’s fast flips, not full reshelves.
But bottlenecks lurk. Cache grows linearly with sequence length—gigabytes for million-token contexts. Memory bandwidth? The choke point. NVIDIA’s H100s gulp data at 3TB/s, yet decode loops make it sequential, underutilizing that firehose.
Companies spin it as ‘solved’ with FlashAttention or quantization. Cute. But hype alert—that’s band-aids on a Ferrari engine wheezing in traffic. Real fix? Speculative decoding, where the model guesses ahead, verifying in parallel. Or chunked prefill for mega-prompts.
We’re talking platform shift here. LLMs aren’t just smarter GPTs; they’re memory machines now, demanding hardware born for cache thrashing.
And for you, the human? Shorter prompts today mean snappier replies. But tomorrow—imagine dumping your entire email history, getting tailored advice in seconds. That’s the wonder.
Prefill dominates short chats (under 1k tokens)—pure compute joy. Cross 4k? Decode rules, memory-bound hell. Data from Llama 70B shows it: latency scales O(N) per token, not flat.
Numbers don’t lie. For 8k context, decode’s 80% of time on A100s. Push to 32k? Triple it. KV cache buys time, but bandwidth begs for revolution.
The Decode Bottleneck: Memory’s Revenge
Loop back—literally. Decode’s a for-loop from hell: generate, append, attend, repeat. Each iteration, KV cache balloons, bandwidth begs for mercy.
Vivid? It’s a crowded elevator. Prefill packs everyone in parallel. Decode? One new rider per floor, but scanning the full roster each time—eyes darting, murmurs rising.
GPU architects weep. Compute utilization plummets from 50% in prefill to 5% in decode. Why? Data movement trumps arithmetic.
My unique twist: this echoes quantum computing’s no-cloning theorem—can’t duplicate context cheaply. But AI’s classical fix? Hybrid compute: photonic interconnects for cache fetches, or neuromorphic chips mimicking brain sparsity.
Optimism overload. Startups like Tenstorrent nail this—custom silicon where decode flies.
Users feel it now: agentic workflows (AutoGPT-style) chain long contexts, grinding servers dry. Fix inference? Unlock autonomous AI fleets.
So, next time your AI lags—blame decode, cheer KV cache. And watch this space. The bottleneck’s days are numbered.
🧬 Related Insights
- Read more: AI’s Big Promise for Bank Call Centers: Savior or Snake Oil?
- Read more: CORPGEN’s Digital Employees Master Office Multitasking
Frequently Asked Questions
What is KV cache in LLM inference?
It’s the stored keys and values from past tokens, letting decode skip recomputes and slash latency—essential for anything beyond toy prompts.
Why does LLM inference slow with long prompts?
Prefill handles the prompt fast (parallel), but decode generates sequentially, rereading growing context via KV cache—memory bandwidth starves as length explodes.
Can we fix the decode bottleneck in LLMs?
Yep—speculative decoding, paged attention, better hardware. Infinite-context AI? Inevitable, transforming chats to full-knowledge companions.