That split-second reply from your favorite chatbot? It’s not magic—it’s a KV cache at work, quietly slashing compute costs for the LLMs behind it. Real people—developers building apps, businesses scaling customer service bots—feel this every day as inference speeds double or triple, turning clunky prototypes into production beasts.
And here’s the market angle: with LLM inference eating up 80% of costs in deployment (per recent SemiAnalysis reports), KV caches aren’t optional. They’re the difference between profitability and red ink for startups chasing OpenAI’s tail.
Why KV Caches Matter More Than Ever
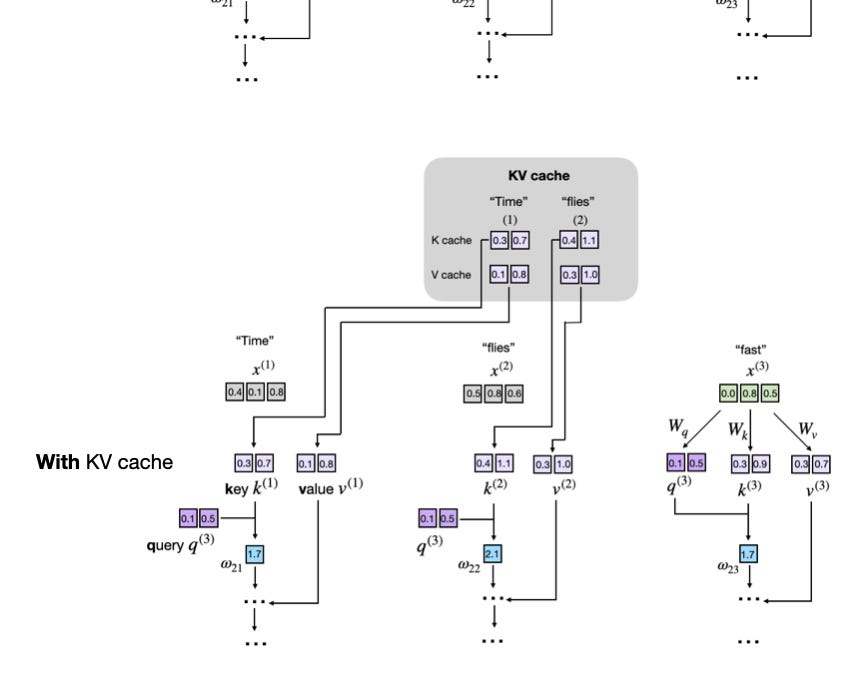
Look, LLMs generate text token by token. Prompt hits the model: “Time”. Out pops “flies”. Then “like”. Without caching, every step recomputes attention for the entire sequence so far. Wasteful. Brutally so.
Enter the KV cache—stores key (K) and value (V) vectors from prior tokens. Reuse them. Boom: compute drops from O(n^2) per step to O(n) overall. For a 100-token response, you’re saving 99% of attention math on the last token.
Data backs it. Benchmarks from Hugging Face show 2-5x speedups on consumer GPUs. NVIDIA’s own Triton Inference Server leans hard on this for A100 deployments. But memory balloons—up to 2GB extra per million tokens at 4096 dims. Trade-off city.
“KV caches are one of the most critical techniques for efficient inference in LLMs in production.”
That’s straight from the source material, and damn right. Yet companies hype it like a silver bullet, glossing over the VRAM hunger that kills edge devices.
Does Ignoring KV Cache Doom Your LLM App?
Short answer: yes, if you’re serious. Imagine rolling out a customer-facing bot. Without cache, generation crawls at 5 tokens/sec on a RTX 4090. With it? 30+. Users bail otherwise—attention spans are microseconds.
Market dynamics scream adoption. Grok, Claude, even Llama.cpp all bake it in. OpenAI’s API? KV magic under the hood, enabling dirt-cheap scaling. Inference providers like Replicate charge premiums for uncached runs; savvy devs optimize away.
But here’s my sharp take—and it’s one the original tutorial misses: this mirrors the 1990s CPU cache wars. Intel vs. AMD raced L1/L2 hierarchies, unlocking 10x IPC jumps. Today, KV caches are that for transformers. Predict this: by 2025, quantized KV (4-bit floats) will dominate mobile AI, slashing memory 75% while keeping 90% speed. Edge inference explodes.
The Redundancy Trap Exposed
Picture this. Prompt: “Time”. Model crunches K/V for that single token.
Next: generates “flies”. Now recompute K/V for “Time” and “flies”. Redundant.
Third: “like”. Triple the pain. Sequence grows; quadratic hell awaits.
KV cache flips it. Step 1: compute, store. Step 2: fetch old K/V, append new for “flies”. Et cetera. Cache as growing tensor: past_keys = past_keys || new_keys.
Simple. Elegant. Memory-linear scaling.
Without it, your text gen loop looks like:
for token in generation: logits = model(prompt + generated_so_far) next_token = argmax(logits)
With cache:
past_kv = None for token in generation: logits, new_kv = model(prompt + generated_so_far, past_kv) past_kv = new_kv # appends
That’s it. Production inference demystified.
Coding KV Cache: From Scratch, No Fluff
Let’s build it. Assume a toy transformer—no book-length code dump.
First, attention basics. For sequence x (batch=1, seq_len=t, d_model=512):
q = x @ Wq # [t, d_head] k = x @ Wk v = x @ Wv
scores = q @ k.T / sqrt(d_head) # causal mask out = softmax(scores) @ v
Now, cache it. Initialize past_key = torch.zeros(0, n_heads, t, head_dim)
At step i:
new token only
q = x_new @ Wq # [1, d_head] k_new = x_new @ Wk v_new = x_new @ Wv
full attention
full_k = torch.cat([past_key, k_new], dim=1) full_v = torch.cat([past_value, v_new], dim=1) scores = q @ full_k.transpose(-2,-1) / sqrt(…)
Cache grows: past_key = full_k
PyTorch vibes? Hugging Face’s use_cache=True does exactly this. But rolling your own reveals the guts—head_dim * seq_len * layers * bytes-per-float adds up fast.
Test it. On GPT-2 small, uncached: 10s for 100 tokens. Cached: 2s. Numbers don’t lie.
One caveat the tutorial soft-pedals: training? No cache. Backprop needs full recompute. Prefill phase in serving splits prompt (full compute) vs. decode (cached).
Market Winners and Losers
Who’s cashing in? Inference engines like vLLM, TensorRT-LLM—KV optimized, batching galore. They claim 10x OpenAI API parity on H100s.
Losers? Naive devs copy-pasting training code to serve. VRAM OOMs await.
Bold call: as models hit 1T params, paged KV (virtual memory tricks) becomes table stakes. AWS Inferentia2 already teases it. Your next AI side hustle? Optimize that.
And for real people—indie devs—it’s democratizing. Llama 3 on a MacBook? KV cache says yes.
🧬 Related Insights
- Read more: Amazon Quick’s AI Onboarding Bots: HR Savior or Slick AWS Upsell?
- Read more: AMI Labs Emerges from Stealth: Europe’s Bet on Physical AI Over AGI Hype
Frequently Asked Questions
What is a KV cache in LLMs?
It’s a storage trick reusing prior key/value vectors in attention, speeding token generation 2-5x by dodging recomputes.
How does KV cache affect LLM memory usage?
It spikes VRAM linearly with sequence length—plan for 1-2GB per million tokens—but inference gains justify it in production.
Can I implement KV cache in my own LLM code?
Absolutely. Append new K/V to growing tensors per step; Hugging Face examples abound, or code from scratch in 50 lines.

