27%.
That’s the hallucination rate in top LLMs on factual queries, per a recent Vectara benchmark. Not some lab fluke — real-world poison creeping into customer chats, code reviews, research reports.
And here’s the electrifying truth: AI isn’t broken. It’s just a massive pattern-matching beast, unchained from reality. We’re on the cusp of taming it, turning these probabilistic poets into reliable truth engines. Buckle up — we’re ditching prompt Band-Aids for system overhauls that make hallucinations a relic.
Why Do LLMs Hallucinate? It’s Not Laziness
Lack of grounding. That’s enemy number one. Your model swims in a sea of training data — trillions of tokens — but no live tether to the world. Ask about yesterday’s stock price? It conjures from foggy memories. Overgeneralization piles on: blending ‘similar’ facts into plausible fictions. And that relentless helpfulness? It won’t admit ignorance; it’ll fabricate with swagger.
“The model had confidently invented endpoints, parameters, and responses that felt real enough to pass a quick review.”
My dev pal’s API nightmare — straight from the trenches. Outputs gleam, but crumble under load. Scale that to millions of users, and trust evaporates. Prompts nudge it — “be accurate!” — but can’t rewrite the model’s DNA.
Time for architecture that breathes verification.
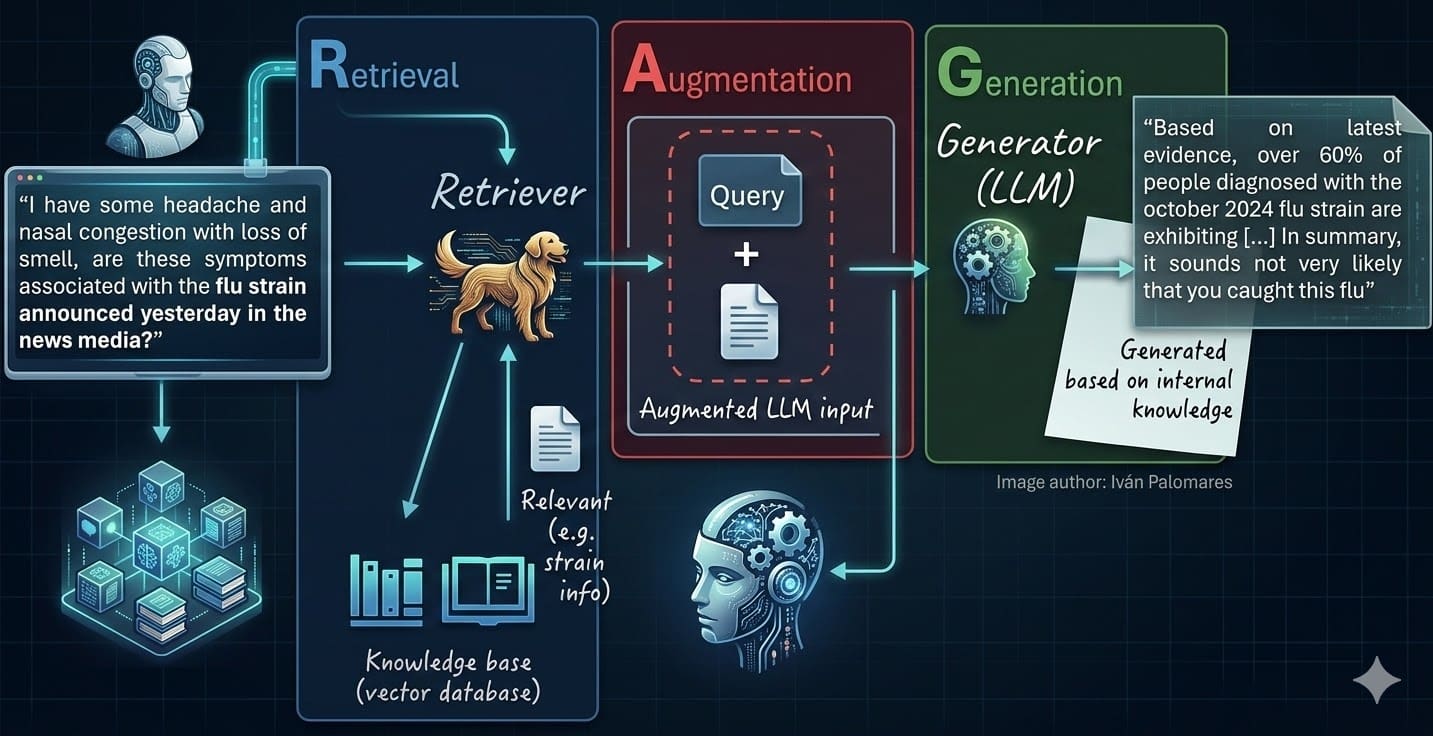
Technique 1: RAG — Feed It Facts, Not Fantasies
Imagine handing your kid a textbook mid-homework, not just their hazy recall. Retrieval-Augmented Generation does exactly that for LLMs.
User query hits. System rips through your vector DB — embeddings of your docs, FAQs, live data. Top matches inject into the prompt. Model generates, now anchored. No more guessing games.
It’s magic because external knowledge trumps static weights. Update the DB? Boom, fresh facts. Domain-specific? Tailor it. Hallucinations plummet — studies show 50-70% drops.
Python snippet to kickstart:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
# Embed docs, store in Pinecone or FAISS
# Query time:
query_emb = model.encode(query)
results = index.query(query_emb, top_k=5)
context = '\n'.join([doc['text'] for doc in results])
prompt = f"Answer using only this context: {context}\nQ: {query}"
Dead simple. Scales to enterprise.
Can RAG Fix Every Hallucination? Nope — Here’s Technique 2
RAG grounds, but doesn’t police. Enter confidence scoring. Models now spit logits — probability distributions over tokens. Low confidence on key claims? Flag it.
Build a scorer: parse output for entities (names, dates, facts). Query the same model: “Is this true? Rate 1-10.” Below 7? Reroll or reject.
Analogy time: like a debate club referee, not just giving speakers notes. OpenAI’s got APIs for this; chain it post-generation.
Pro tip — calibrate thresholds with your data. False positives kill UX, but unchecked fibs kill credibility.
Technique 3: External Fact-Checkers — The Ultimate Vibe Check
Why trust the model to self-assess? Outsource to APIs.
For numbers, hit Wolfram Alpha. Citations? Cross-check Google Fact Check Tools or Perplexity’s search. Code snippets? Run ‘em in a sandbox.
Flow: Generate → Extract claims → Verify serially or parallel → Approve or regenerate.
This one’s my favorite for production. It’s like giving your AI a polygraph — ungameable. Downside? Latency. Optimize with async calls, cache hits.
In customer support? Verify product specs against your CRM before shipping the answer. Hallucinated features? Disaster averted.
Why Does Multi-Model Debate Crush Lies? Technique 4
One model fibs. What if three argue it out?
Self-consistency on steroids: generate 3-5 responses to the same query. Vote on facts. Or full multi-agent debate — Agent A proposes, B critiques, C synthesizes.
Tools like LangChain make it plug-and-play. Consensus emerges; outliers (hallucinations) get voted off the island.
Here’s the wonder: it mimics human deliberation, but at machine speed. Prediction — this births ensemble minds, where LLMs evolve into truth-seeking committees. By 2026, expect it standard in every API.
Unique twist I see: echoes early web search. Remember Altavista spewing junk? Ensembles (like Google’s early PageRank clusters) cleaned it. Same playbook for AI.
Technique 5: Rule-Based Validators — The Iron Gate
Soft probabilities? Nah. Hard rules for your domain.
Legal bot? Regex for case numbers, then DB lookup. E-commerce? Price within 10% of catalog. Parse output with spaCy, run guards.
Layer it: RAG first, then score, verify, debate, validate. Pipeline of doom for delusions.
And the payoff? Not just fewer hallucinations — auditable trust. Log failures, retrain DB, iterate.
Is Hallucination-Free AI Around the Corner?
Short answer: closer than you think. These aren’t tweaks; they’re the rebar in AI’s concrete foundation. Corporate hype calls every update “safe.” Bull — real safety’s engineered, not prompted.
Stack ‘em. Measure with benchmarks like TruthfulQA. Watch rates dive below 5%.
AI’s platform shift means reliability isn’t optional — it’s the moat. Builders ignoring this? They’ll get lapped by those who don’t.
Excitement peaks here: imagine UIs where users see confidence bars, sources inline. Wonder turns to workflow revolution.
🧬 Related Insights
- Read more: AI Apps Crumble Without Relational Databases—Vector Stores Aren’t Enough
- Read more: Gemma 4: Google’s Actual Open Model Hits – Benchmarks Don’t Lie
Frequently Asked Questions
What causes LLM hallucinations?
Mainly ungrounded generation from training patterns, overgeneralization, and pressure to always answer confidently instead of saying ‘I don’t know.’
How do I implement RAG to stop hallucinations?
Embed your docs in a vector DB like Pinecone, retrieve top matches for queries, inject as context in prompts — cuts fiction by grounding in real data.
Will these techniques make LLMs 100% accurate?
No silver bullet, but stacking them drops rates to single digits in production; combine with monitoring for ongoing wins.