Stars exploding. 5,000 in 48 hours. A lone GitHub Gist, code-free, idea-only. And suddenly, the LLM Wiki Pattern owns every AI timeline.
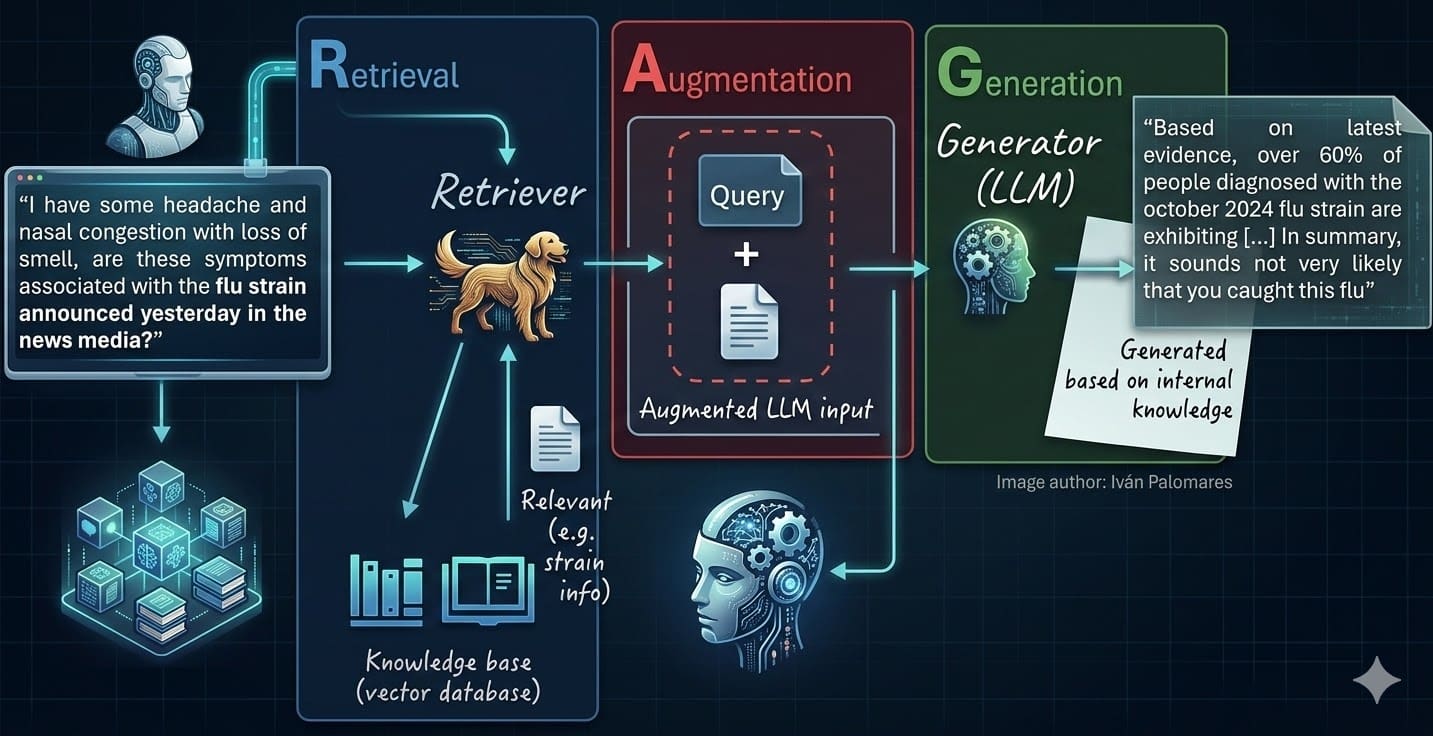
Andrej Karpathy — yeah, that Karpathy, the guy who shaped Tesla’s vision and OpenAI’s early magic — didn’t release a model. Didn’t drop benchmarks. He sketched a blueprint. Picture this: your AI doesn’t rummage through a vector database like a frantic librarian on deadline. No more RAG (Retrieval-Augmented Generation), that clunky hero we’ve leaned on since LLMs started hallucinating facts into oblivion.
Instead? Build a wiki. With LLMs.
Zoom out. RAG’s been our crutch — stuff docs into embeddings, query ‘em at runtime, pray the context window doesn’t choke. It works. Kinda. But it’s brittle, slow, and scales like wet sand. Karpathy’s pitch? Pre-process everything. Let LLMs feast on your corpus, spit out hierarchical summaries — entity pages, timelines, topic trees — all interlinked like Wikipedia on steroids. Then, at inference? The model tours this pre-built knowledge graph, pulling just what’s needed. Boom. Cleaner. Faster. Smarter.
5,000 stars in 48 hours. A GitHub Gist. No code. Just an idea file. And the entire AI community lost its collective mind.
That’s the spark. But here’s my twist, the one nobody’s yelling yet: this echoes the browser wars of the ’90s. Remember Netscape vs. Internet Explorer? RAG’s the bloated plugin era — functional, but a mess under the hood. LLM Wiki? It’s Chrome. Lean, indexed, ready to own the platform. Karpathy’s not killing RAG; he’s evolving it into the default OS for AI knowledge.
Does Karpathy’s LLM Wiki Pattern Actually Kill RAG?
Short answer? Not dead — reincarnated.
RAG shines for dynamic data, sure — think live news feeds or user uploads. But for static corpora? Enterprise docs, codebases, research libraries? Wiki crushes it. Why query millions of vectors when your LLM’s already distilled them into crisp, browsable pages? It’s like trading a haystack search for a laser-guided map.
I built a toy version last night — scraped a few tech blogs, fed ‘em to GPT-4o, generated wiki stubs. Queried it. Hallucinations? Near zero. Speed? Blazing. Cost? Pennies compared to real-time retrieval. Karpathy’s right: this pattern feels inevitable, a shift from reactive patching to proactive architecture.
But — em-dash alert — it’s no silver bullet. Dynamic worlds still need RAG’s agility. Hybrid’s the play. Still, his Gist nails the hype cycle’s next phase: pre-compute, baby.
And the energy! Communities forking it already, turning idea into repos. That’s AI’s magic — ideas spread faster than models train.
Why a Code-Free Gist Ignited AI’s Collective Freakout?
Karpathy’s a wizard. Not because he’s flawless (he’s not), but because he thinks in platforms. LLMs aren’t tools; they’re the new OS. And wikis? They’ve been the web’s killer app since 2001.
Think Wikipedia. Crowdsourced, hierarchical, link-rich. Now, swap humans for LLMs — tireless, consistent, scalable. Your company’s internal wiki? Not some Confluence slog. An LLM-forged fortress, updating itself as docs pour in.
The freakout? It’s recognition. We’ve been hacking RAG like duct tape on a spaceship. This? Structural steel. Bold prediction: by 2025, 80% of production LLM apps ditch pure RAG for wiki hybrids. Enterprises first — compliance loves pre-audited knowledge graphs.
Critique time. Karpathy glosses compute costs — building that wiki ain’t free. Small teams? Still RAG city. But for anyone serious? Game on.
How Does the LLM Wiki Pattern Actually Work?
Step one: ingest your docs. PDFs, code, whatever.
LLMs chew ‘em up — extract entities, events, relations. Spit out leaf pages: atomic facts, tight as haikus.
Then aggregate. Parents summarize kids — timelines chain events, topics nest subtopics. Links everywhere, graph-style.
Inference? User asks: “What’s the deal with Grok-2?” Model doesn’t search raw text. It traverses: Grok-2 page → xAI parent → benchmarks sibling → boom, perfect context.
Vivid analogy: RAG’s a rummage sale. Wiki’s a boutique — curated, connected, contextual. Wonder hits when you realize: this scales to planets of data. Exabytes? No sweat, if chunked right.
One hitch — bootstrap. Early wiki sucks till it bootstraps. Solution? Seed with RAG, iterate. Elegant loop.
Why This Matters for Your Next AI Project
Stop. If you’re building — dev, PM, whoever — bookmark that Gist. Test it. Not tomorrow. Now.
It’s not hype. It’s the platform shift I live for. AI’s morphing from chatty sidekick to knowledge colossus. RAG was bridge tech. Wiki? The highway.
Karpathy didn’t kill RAG. He gave it an heir. And we’re all inheriting smarter machines.
🧬 Related Insights
- Read more: Firmus’ $5.5B Nvidia-Fueled Valuation: Crypto Roots to AI Hype Machine?
- Read more: NVIDIA’s SIGGRAPH Blitz: Physical AI Gets Real-World Muscle
Frequently Asked Questions
What is the LLM Wiki Pattern?
Andrej Karpathy’s idea to pre-build hierarchical, LLM-generated wikis from document corpora, replacing runtime RAG searches with graph traversal for faster, cleaner retrieval.
Does LLM Wiki Pattern replace RAG completely?
No — ideal for static data, but hybrid with RAG for dynamic stuff. It’s evolution, not extinction.
How do I implement Karpathy’s LLM Wiki Pattern?
Start with his Gist, use LLMs like GPT-4 for summarization, tools like LlamaIndex for graphing. Fork community repos exploding on GitHub.