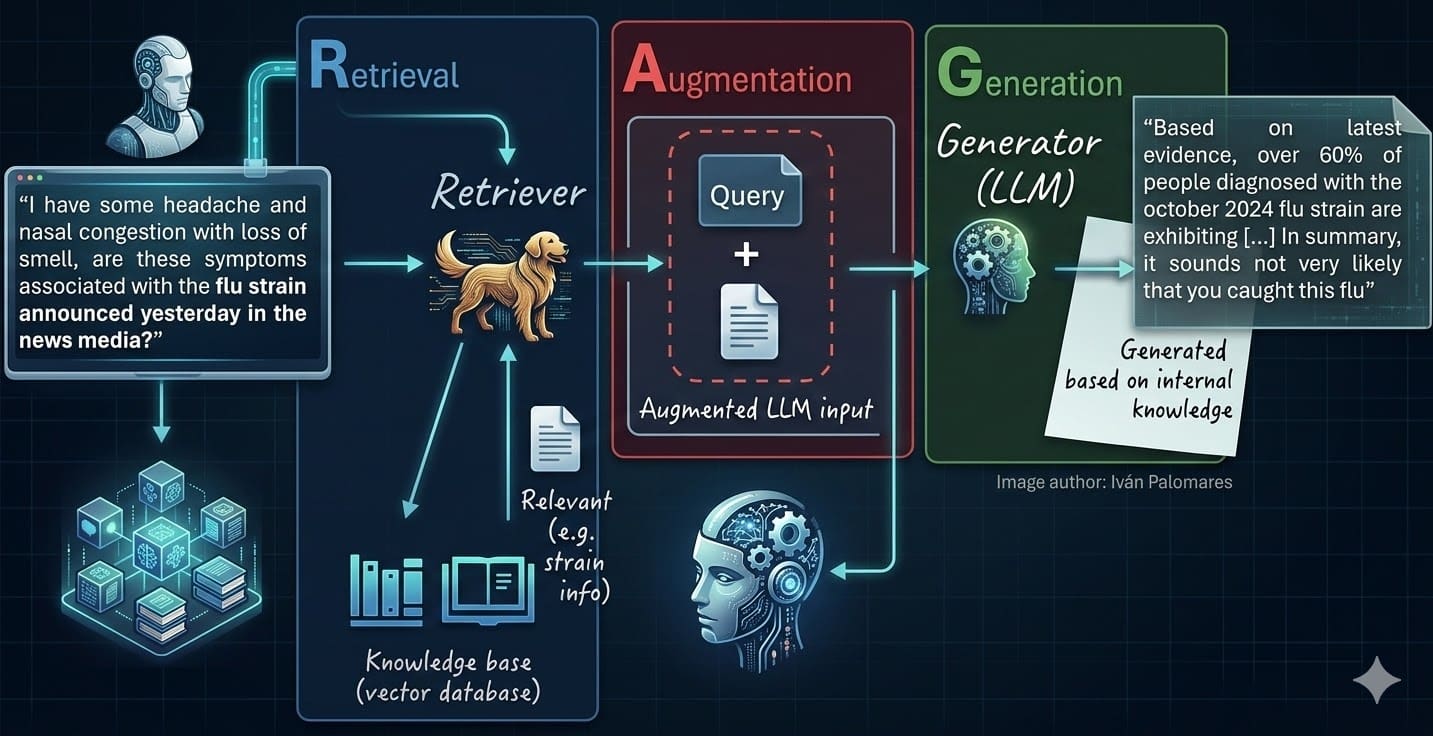
What if your smartest engineer can’t find the post-mortem from last week—while ChatGPT confidently lies about it?
That’s the dirty secret of enterprise AI. Retrieval-Augmented Generation—or RAG for enterprise knowledge bases—isn’t some buzzword fix. It’s the duct tape holding your LLM together when it faces real-world docs. But most teams botch it. Spectacularly.
And here’s the kicker: without RAG, you’re not just wasting hours. You’re brewing compliance nightmares. Picture this—HR policy from 2022, fed into a model blind to last month’s update. Boom. Lawsuit bait.
The original pitch nails it:
That moment is not a model failure. It is an architecture failure. And it is exactly the problem that Retrieval-Augmented Generation, or RAG, was designed to solve.
Spot on. But let’s cut the fluff. LLMs alone? Useless for your Confluence jungle.
Why Chase RAG When Fine-Tuning Sounds Sexier?
Fine-tuning. It’s the siren song. Tweak the model on your data, get that custom tone. Sounds great—until quarterly policy shifts hit. Retrain? Weeks. Dollars. Drama.
RAG? Query time magic. Pull fresh docs, stuff ‘em in context, generate. Traceable. Updatable in minutes. No data leaves your vault—perfect for regulated dinosaurs like banks or pharma.
But don’t kid yourself. Employees waste 2-3 hours weekly hunting ghosts in SharePoint. Newbies? Months to ramp. RAG threads that needle—if you build it right.
My hot take? RAG isn’t just better; it’s the death knell for fine-tuning in 90% of enterprises. Like how Google killed custom indexes with universal search. Predict that: by 2026, RAG stacks will own internal AI, fine-tuning relegated to niche style tweaks.
The Indexing Pipeline: Where Dreams Go to Die
Start here. Or fail.
Documents everywhere. Confluence. Notion. Dusty emails. LlamaIndex swoops in—hundred-plus loaders, hash tracking for increments. Smart.
Code snippet? Sure:
from llama_index.readers.confluence import ConfluenceReader
confluence_docs = ConfluenceReader(...).load_data(...)
Log failures. One skipped PDF? Hallucination hole later.
Chunking. Oh boy. This kills more RAGs than bad embeddings.
If you take one thing from this article, let it be this: the quality of your chunking has more impact on your system’s performance than your choice of LLM or even your embedding model.
Truth. Chunk too big? Context overload, irrelevant noise. Too small? Loses meaning, retrieval flops.
Teams grab semantic chunkers, call it done. Wrong. Test overlaps, metadata injection. For runbooks, chunk by section. Policies? By clause. One size? Fits none.
Embed. Pick sentence-transformers or OpenAI—doesn’t matter if chunks suck. Store in FAISS or Pinecone. Vector DBs shine here.
Incremental? Crucial. Evolving base means daily syncs.
Retrieval Pipeline: Search, Rank, Don’t Pray
User asks. Embed query. KNN search top-k chunks. Boom—prompt fodder.
But raw? Garbage in, garbage out. Re-rank with cross-encoders. ColBERT for speed. Hybrid: BM25 + vectors. Beats pure semantic every time on enterprise gunk.
Prompting. “Answer using only this context.” Add sources. Chain-of-thought if tricky.
Generation. Llama3. Mixtral. Open, on-prem. Scale matters less than relevance.
Is RAG Bulletproof? (Spoiler: Nope)
Nah. Edge cases lurk. Ambiguous queries? Multi-hop needs graph RAG. Long docs? Hierarchical indexing.
Evaluation. Not end-to-end hallucinations. Stage it: retrieval recall, faithfulness scores. RAGAS or TruLens. A/B test chunks.
Corporate spin alert: Vendors hype ‘plug-and-play.’ Bull. Your docs are messy. Test rigorously or flop.
Where RAG ends, fine-tune starts? Style. Rare domains. But mostly? RAG wins.
Build this open-source. LlamaIndex, Haystack. No lock-in.
The Chunking Catastrophe: A Historical Parallel
Remember early search engines? Keyword soup, no semantics. RAG’s chunking is that pivot— from bag-of-words to vectors.
Botch it, and you’re AltaVista in 2024. Relevant docs buried. My prediction: chunking tools with auto-optimization (via evals) will explode next year.
Teams ignore this, chase fancier LLMs. Fools.
Production tips. Async indexing. Rate limits. Monitoring—drift in embeddings kills recall.
Scale? Sharding vector stores. GPU for embeds.
Why Does RAG Matter for Your Dev Team?
Devs hate support tickets. RAG turns knowledge bases into oracles. Onboarding? Days, not months.
Skeptical? Run a pilot. Confluence dump, simple RAG. Measure time saved. Bet you’ll scale.
But here’s the acerbic truth: If you’re still prompting raw LLMs on internal docs, you’re not innovative. You’re lazy.
🧬 Related Insights
- Read more: OpenAI’s $852 Billion Empire Hits Turbulence: Top Execs Out on Medical Leave as IPO Looms
- Read more: The Stack Behind AI’s World Models: Compress, Predict, Plan
Frequently Asked Questions
What is RAG for enterprise knowledge bases?
RAG pulls relevant docs at query time, grounds LLM answers in your latest data—traceable, updatable, no retraining.
How do you build a RAG system step by step?
Index: load, chunk smart, embed, store. Retrieve: query, rank, prompt, generate. Eval every stage.
Does RAG replace fine-tuning?
For most enterprise info retrieval? Yes. Fine-tune only for tone or ultra-niche.