Vector databases have emerged as a critical piece of AI infrastructure, enabling the similarity search capabilities that power retrieval-augmented generation, recommendation engines, image search, and anomaly detection systems. As AI applications increasingly rely on embedding representations, understanding how vector databases work has become essential knowledge for engineers and architects.
What Are Vector Embeddings?
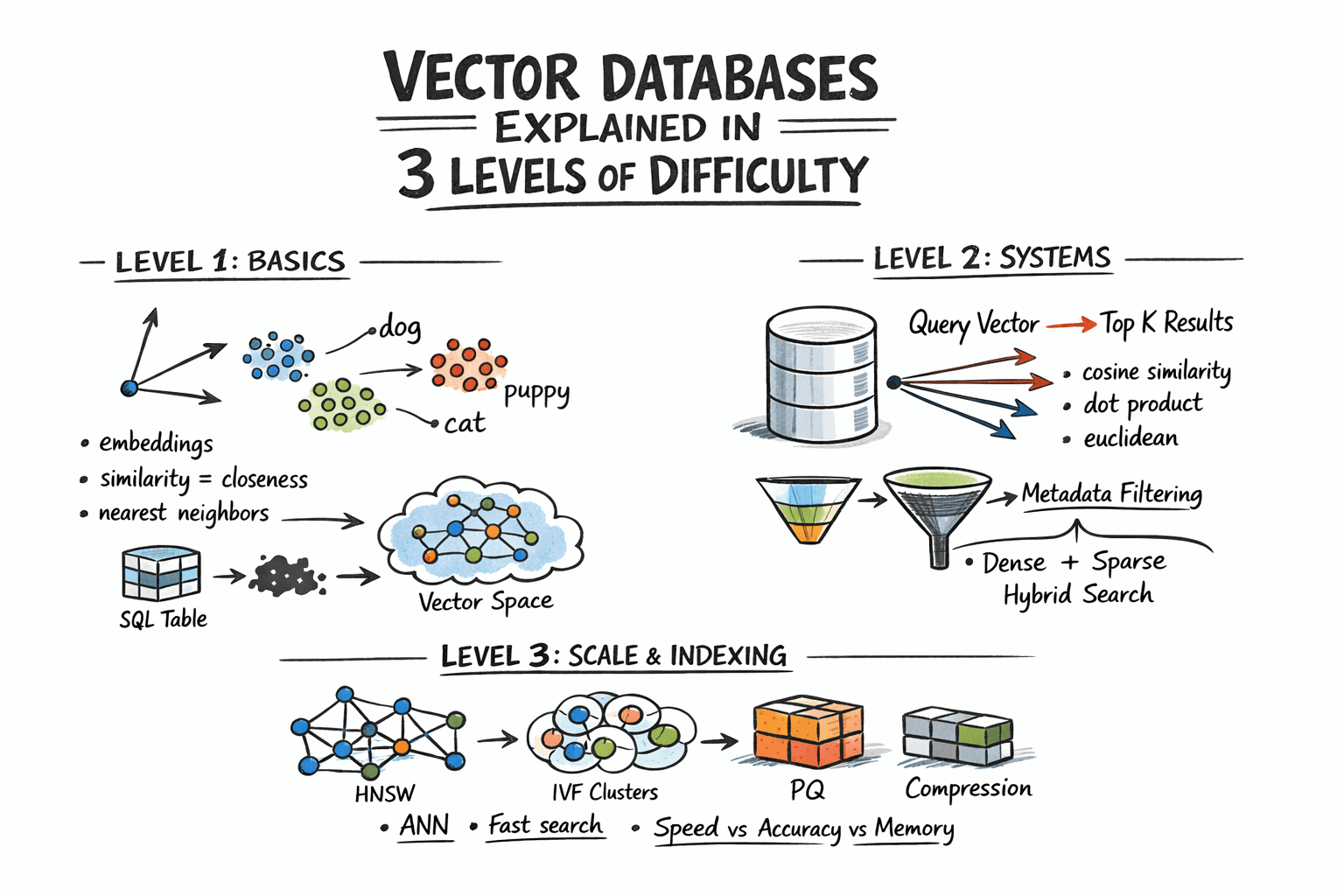
Before understanding vector databases, it is important to understand what they store. A vector embedding is a numerical representation of data, typically a list of floating-point numbers, where similar items are represented by similar vectors.
Embedding models convert various types of data into vectors:
- Text embeddings represent the semantic meaning of words, sentences, or documents. The sentence The cat sat on the mat might become a vector of 1,536 dimensions. Sentences with similar meanings produce vectors that are close together in this high-dimensional space.
- Image embeddings capture visual features. Photos of dogs produce vectors that cluster near each other and far from vectors representing photos of buildings.
- Audio embeddings represent acoustic features, enabling similarity search across sound recordings.
The power of embeddings lies in this geometric property: semantic similarity maps to spatial proximity. Finding similar items becomes a geometric problem of finding nearby points in high-dimensional space.
Why Traditional Databases Fall Short
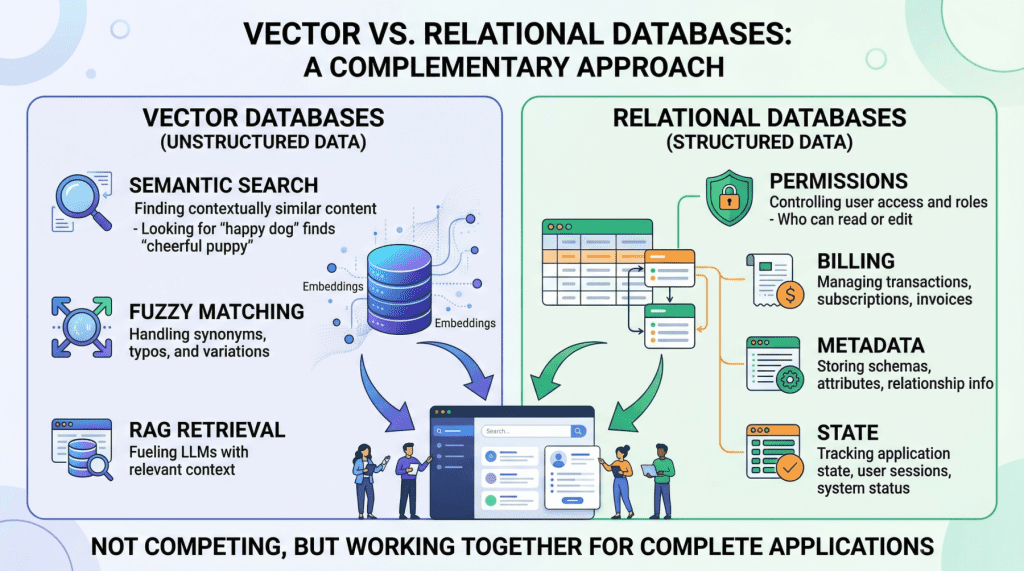
Traditional relational databases and document stores are optimized for exact match queries: find the row where id = 42 or filter documents where category = 'science'. They use index structures like B-trees and hash indexes that are designed for equality and range comparisons.
Vector similarity search is fundamentally different. Given a query vector, you need to find the k vectors in the database that are closest to it, where closeness is measured by distance metrics like cosine similarity or Euclidean distance. This requires comparing the query against potentially millions of stored vectors, a task that traditional indexes cannot accelerate.
While you can store vectors in PostgreSQL or MongoDB, performing similarity searches at scale without specialized indexing is prohibitively slow: a brute-force scan comparing a query against 10 million 1,536-dimensional vectors takes seconds to minutes, far too slow for real-time applications.
How Vector Databases Solve This
Vector databases use specialized indexing algorithms called approximate nearest neighbor (ANN) algorithms to make similarity search fast at scale, accepting a small reduction in accuracy in exchange for dramatic speed improvements.
Key Indexing Algorithms
- HNSW (Hierarchical Navigable Small World): Builds a multi-layer graph where each node connects to nearby vectors. Searching starts at the top layer (few nodes, long-range connections) and progressively moves to lower layers (more nodes, short-range connections), quickly narrowing down to the nearest neighbors. HNSW offers excellent query performance with high recall, making it the most popular choice for many applications.
- IVF (Inverted File Index): Partitions the vector space into clusters using k-means clustering. At query time, only the clusters closest to the query vector are searched, dramatically reducing the number of comparisons. IVF works well for large datasets and can be combined with product quantization for memory efficiency.
- Product Quantization (PQ): Compresses vectors by dividing them into subvectors and quantizing each independently. This reduces memory requirements by 4-8x with modest accuracy loss, enabling larger datasets to fit in memory.
Distance Metrics
Vector databases support multiple distance metrics for measuring similarity:
- Cosine similarity: Measures the angle between vectors, ignoring magnitude. Most commonly used for text embeddings where the direction of the vector matters more than its length.
- Euclidean distance (L2): Measures the straight-line distance between vectors. Used when magnitude is meaningful.
- Dot product: Combines direction and magnitude. Often used when vectors are normalized, in which case it is equivalent to cosine similarity.
Major Vector Database Options
Purpose-Built Vector Databases
- Pinecone: A fully managed cloud service that handles infrastructure, scaling, and maintenance. Offers a simple API and strong performance but locks you into a proprietary platform. Best for teams that want to avoid infrastructure management.
- Weaviate: An open-source vector database with built-in vectorization capabilities. It can generate embeddings on ingest, supports hybrid search combining vector and keyword queries, and offers both self-hosted and managed cloud options.
- Milvus: An open-source database designed for large-scale vector similarity search. Strong performance characteristics and support for multiple index types make it suitable for demanding production workloads.
- Qdrant: An open-source vector database written in Rust, offering strong performance and a rich filtering API. Its payload-based filtering allows combining vector similarity search with traditional attribute filtering efficiently.
- ChromaDB: A lightweight, developer-friendly option designed for rapid prototyping and smaller-scale applications. Easy to embed directly in Python applications without running a separate server.
Database Extensions
- pgvector: A PostgreSQL extension that adds vector storage and similarity search to existing PostgreSQL databases. For teams already running PostgreSQL, pgvector avoids introducing a new database into the stack. Performance is competitive for smaller datasets (under a few million vectors) but lags purpose-built solutions at larger scales.
- Redis Vector Similarity: Adds vector search capabilities to Redis. Useful for applications already using Redis that need vector search with very low latency requirements.
Vector Databases in RAG Pipelines
The most common use case driving vector database adoption is retrieval-augmented generation. In a RAG pipeline, the vector database serves as the knowledge store:
- Documents are chunked, embedded, and indexed in the vector database during ingestion.
- When a user submits a query, it is embedded and used to search the vector database for the most relevant document chunks.
- The retrieved chunks are injected into the LLM's prompt as context.
- The LLM generates a response grounded in the retrieved information.
The quality of the vector database's retrieval directly impacts the quality of the RAG system's responses. Poor retrieval leads to irrelevant context, which leads to incorrect or unhelpful answers.
Beyond RAG: Other Applications
Vector databases power several other AI-driven applications:
- Recommendation systems: Represent users and items as vectors, then find items whose vectors are closest to the user's preference vector.
- Image and video search: Embed visual content as vectors to enable search-by-similarity, allowing users to find visually similar images without text descriptions.
- Anomaly detection: Identify data points whose vectors are far from any cluster, indicating unusual or potentially fraudulent behavior.
- Deduplication: Find near-duplicate documents or records by identifying vector pairs with very high similarity scores.
Choosing the Right Solution
The right vector database depends on your specific requirements:
- Scale: For under 1 million vectors, pgvector or ChromaDB may be sufficient. For tens of millions to billions, purpose-built solutions like Milvus or Pinecone are necessary.
- Operational complexity: Managed services like Pinecone minimize operations burden. Self-hosted solutions like Milvus and Weaviate offer more control but require infrastructure management.
- Integration needs: If you already run PostgreSQL, pgvector keeps your stack simple. If you need built-in vectorization, Weaviate handles embedding generation natively.
- Query patterns: If you need hybrid search combining vector similarity with metadata filtering, ensure your chosen database supports efficient filtered search.
Vector databases are becoming as fundamental to AI infrastructure as relational databases are to traditional applications. As embedding-based approaches continue to expand across AI applications, the ability to efficiently store, index, and search vector data will remain a core infrastructure capability.