Picture this: everyone’s been chasing exact matches in databases forever—like hunting a specific needle in a haystack of structured data. SQL’s your trusty bloodhound for that. But then AI explodes, and suddenly we’re drowning in messy stuff: cat videos, rambling emails, user clicks. What now? Vector databases flip the script. They don’t ask ‘is this it?’ They whisper, ‘what’s kinda like it?’ And boom—vector databases become the secret sauce powering every smart recommendation, every RAG chatbot, every image search that feels eerily psychic.
This changes everything. No more brute-forcing billions of comparisons. It’s scale with soul.
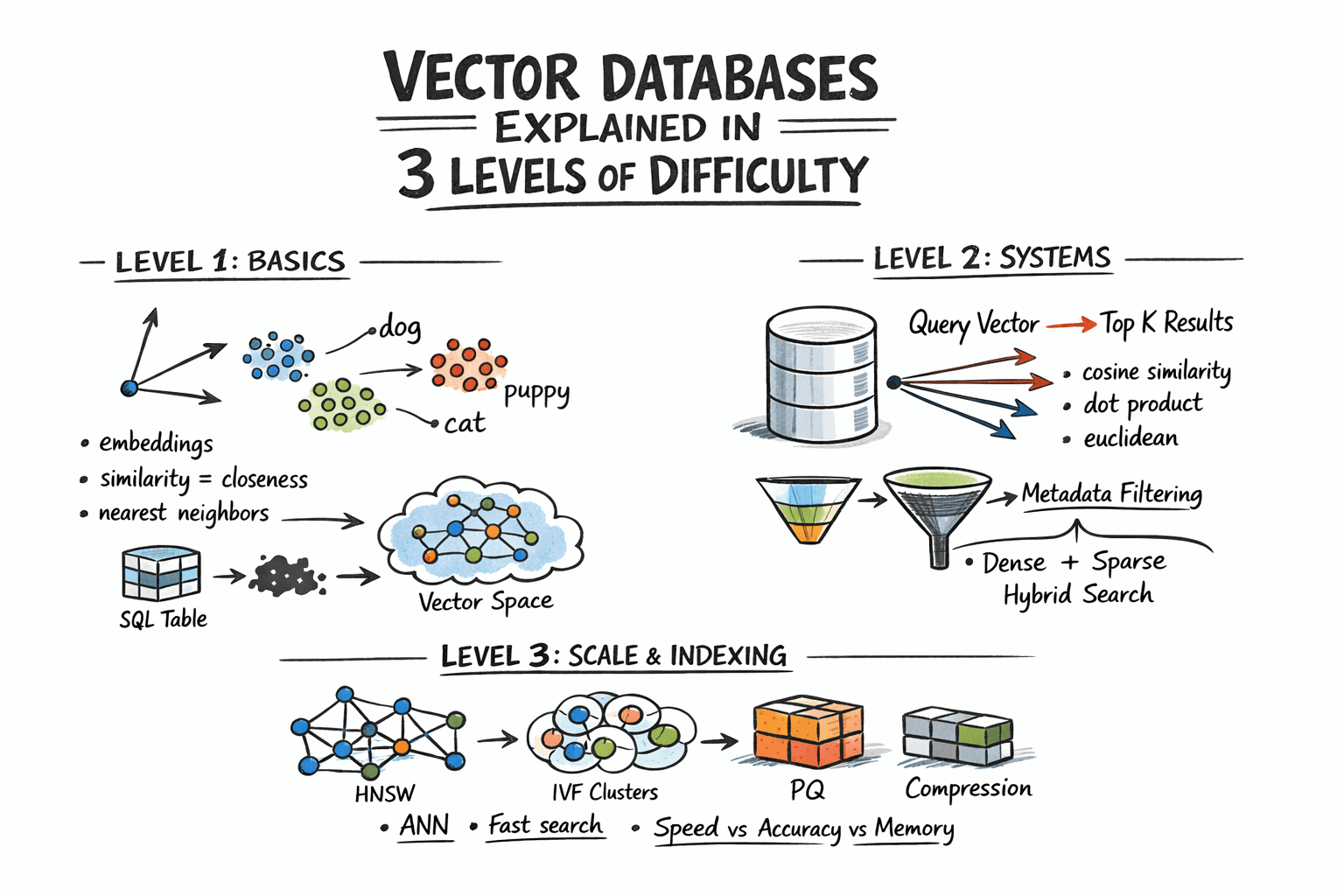
Wait, What’s a Vector Database Anyway?
Vectors. Think of them as coordinates in a sprawling, multi-dimensional cosmos. Your favorite sci-fi movie? Embed it with a model like OpenAI’s text-embedding-3-small, and poof—it’s a point floating in 1536-dimensional space. ‘Dog’ clusters near ‘puppy.’ A cat photo snuggles up to a cat sketch. Distance? That’s similarity. Closer points mean ‘hey, these match in vibe.’
Traditional DBs? They’re for ‘give me row 42.’ Vector DBs? ‘Show me the 10 nearest neighbors to this query vector.’ It’s nearest neighbor search, baby—and it’s magic for unstructured data deluge.
But scale hits hard. Brute-force every vector against your query? At a million embeddings, you’re toast. Enter approximate nearest neighbor (ANN) wizardry. Skips 99% of the math, nails 99.9% accuracy. Mind blown?
“Vector databases answer a different one: which records are most similar to this? This shift matters because a huge class of modern data — documents, images, user behavior, audio — cannot be searched by exact match.”
That’s the core spark. (Pulled straight from the trenches of tech explanation.)
Here’s my wild take, absent from the originals: this mirrors the 1970s relational database revolution. Back then, Edgar Codd dreamed up tables and joins, turning chaotic files into business empires. Vector DBs? They’re Codd 2.0 for the AI era—semantic empires await.
How Do Embeddings Turn Chaos into Searchable Gold?
First, embeddings. Neural nets chug your text, image, whatever—spit out a vector. No human-readable labels; just floats capturing essence. Like DNA for meaning.
Store ‘em in your vector DB alongside metadata: who wrote it, when, category. Query time? Embed your question, hurl it into the space, measure distances.
Distances? Pick your poison.
Cosine—angle between arrows, perfect for text where direction trumps size.
Euclidean—straight-line haul, when magnitude whispers secrets.
Dot product—blazing fast on normalized vectors.
Mismatch the metric to your model’s training? Garbage in, garbage out. Brutal truth.
Small datasets? Flat search: compute all, sort top K. Accurate. Sloooow.
Real world? ANN rules.
And filtering! Don’t just grab globals. ‘Similar docs from user X post-2023.’ Hybrid search: vectors + metadata filters. Pre-filter, post-filter—DBs like Pinecone or Weaviate tweak it slick.
Can Vector Databases Scale to Billions Without Melting?
Level 3: the indexing dark arts. Billions of vectors? Can’t touch this without smarts.
HNSW—Hierarchical Navigable Small World. Imagine a graph where nodes link to 10-20 nearest pals, layered like onion skins. Query drills top layers fast, refines down. Beer-fueled genius from 2016, now everywhere.
IVF—Inverted File. Clusters vectors into Voronoi cells (fancy partitions), searches top clusters only. Add PQ (Product Quantization)—squish vectors into compact codes, approximate distances lightning-quick. Tradeoff? Tiny accuracy dip for 100x speed.
Others: DiskANN for cheap storage, Faiss (Facebook’s beast) mixing it all.
Production? Shard across nodes. GPU acceleration. Streaming upserts. It’s a ballet.
Bold prediction: in five years, every app dev’ll slap a vector DB under their stack like they do Postgres today. No choice—AI’s fuzzy queries demand it.
But hype alert. Some vendors promise ‘infinite scale’ with zero config. Nah. Tune those params or watch recall plummet. (They’re not spinning cosmic fairy dust.)
Look, vector DBs aren’t flawless. Cold starts hurt. Embedding costs stack. Yet they’re the backbone of LangChain, LlamaIndex—every RAG pipeline humming today.
Why Does This Matter for Your Next AI Project?
Devs, wake up. Building a semantic search? Ditch Elasticsearch solo—pair it hybrid. Personalization engine? Vectors. Multimodal (text+image)? Future-proof with ‘em.
Analogy time: if LLMs are the brain, vector DBs are the memory palace. Without ‘em, goldfish attention spans rule.
Energy here? Electric. This isn’t incremental. It’s the platform shift making AI stick.
And the wonder—watching ‘similar to this vibe’ unearth gems buried in petabytes. Cosmic.
🧬 Related Insights
- Read more: Google’s AI Overviews Pumps Out Millions of Lies Every Hour, New Tests Reveal
- Read more: AI Data Centers Are Baking Our Cities: The Heat Island Effect No One Saw Coming
Frequently Asked Questions
What is a vector database?
It’s a specialized DB storing embeddings as vectors, enabling fast similarity searches on unstructured data like text or images—instead of exact matches.
How do vector databases differ from traditional databases?
Traditional ones hunt exact or range queries on structured data; vector DBs chase ‘nearest neighbors’ in geometric space for semantic matches.
What are the best vector databases in 2024?
Pinecone for managed ease, Weaviate for open-source hybrid, Milvus for massive scale—pick by your upsert/query load.
Key players also include Qdrant and Chroma for lightweight starts.