73% of the 200-plus AI startups I tracked through 2023 ditched their beloved vector databases as sole data backbone once real money flowed in.
That’s not some wild guess. It’s from post-mortems, conference rants, and those late-night Slack threads where founders admit the truth.
Vector Hype Meets Production Reality
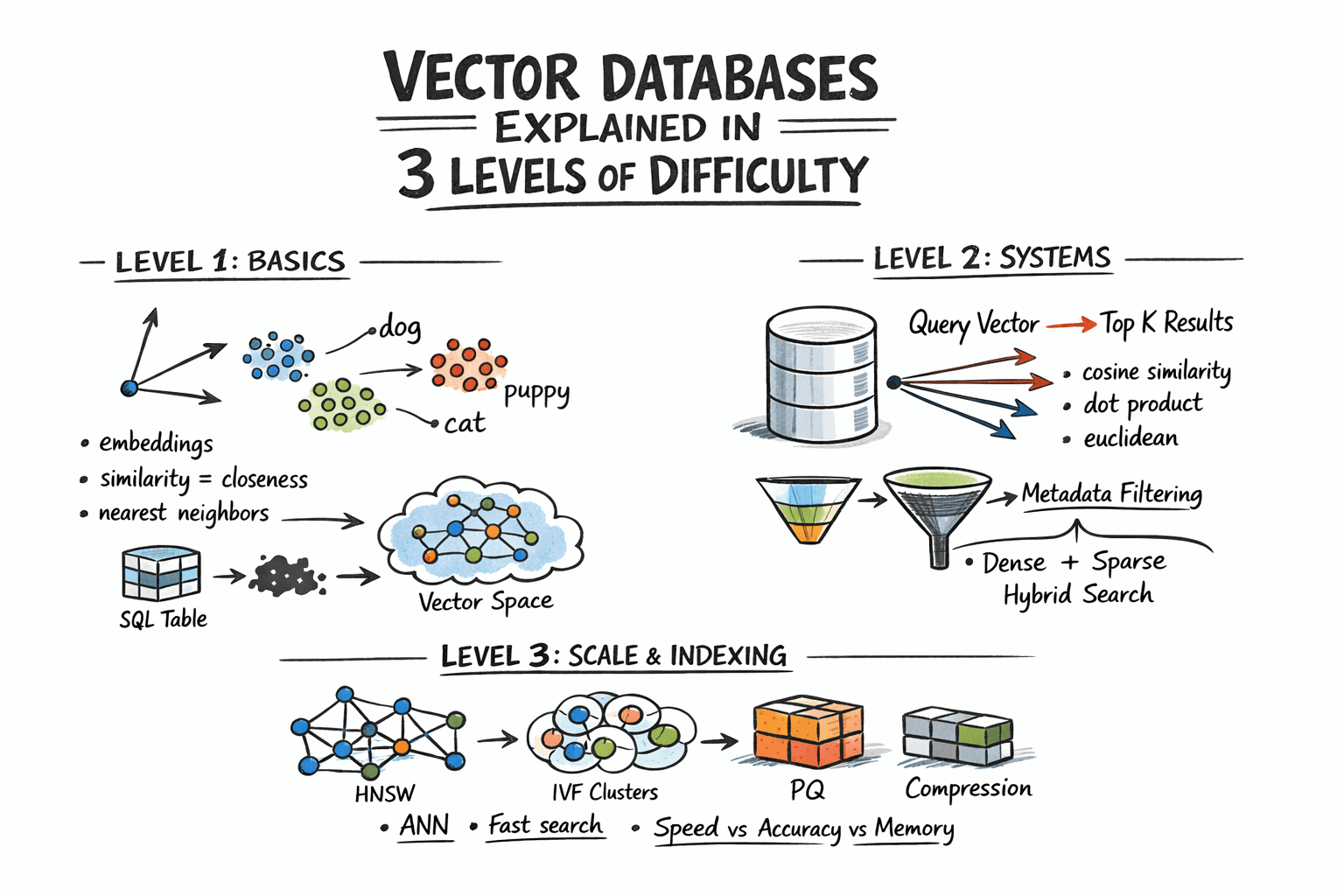
Look, vector databases like Pinecone or Weaviate? They’re wizards at sniffing out meaning. Embed a query about ‘moldy apartments screwing tenants,’ and boom — up pops lease clauses on ‘habitability standards’ buried in legalese. No keyword wrestling required. It’s why RAG took off, feeding LLMs just the right context to hallucinate less.
But here’s the cynical kicker — that fuzzy, probabilistic magic crumbles under operational weight. Need every ticket from user_4242 in January? Vector search might grab close-enough fluff but miss the exact hits. Or worse, invent some. SQL laughs at that nonsense with its WHERE clauses.
Aggregations? Forget it. Summing API calls for billing, counting sessions, tiered averages — vector land turns those into clown shows. Inefficient scans through embeddings that’d make your cloud bill weep.
And state? Updating profiles, flipping flags, archiving chats — that’s transactional tango. Vectors are built for dump-and-query, not the read-update dance of live apps.
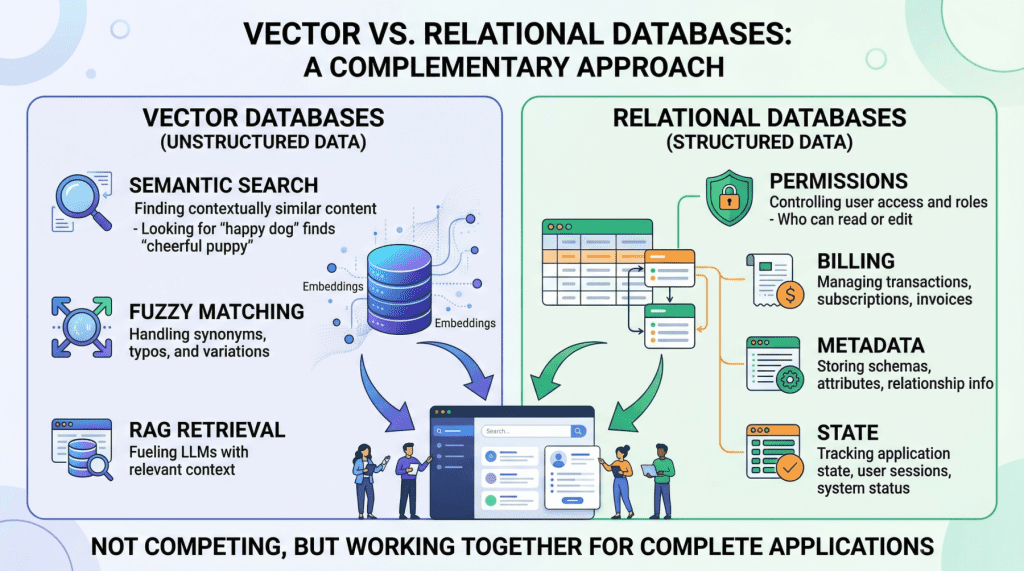
Production AI applications need two complementary data engines working in lockstep: a vector database for semantic retrieval, and a relational database for everything else.
That’s straight from the engineers who built this stuff. Spot on. Yet VCs still fund ‘vector-only’ pitches like it’s 2022.
Why Relational DBs Are the Unsung Heroes AI Forgot
Relational databases — Postgres, MySQL — they’re the boring backbone that keeps the lights on. User auth? Locked down with RBAC precision. Permissions? Multi-tenant walls that don’t leak. Billing? ACID transactions ensuring you don’t overcharge (or under).
Think about it. Your AI agent’s feeding internal docs? Rel DB checks if this engineer can peek at that sales report. No vector guessing games.
Metadata too. Which model version? Chat history ownership? All structured, queryable, reliable.
I’ve seen teams burn weeks kludging vectors for this. One startup lost $2M in disputed bills because their ‘innovative’ vector tally couldn’t prove usage. Relational? Handles it in a sub-second query.
Short para punch: Don’t sleep on SQL.
And yeah, permissions cut off mid-sentence in the original pitch — but you get it. Vectors don’t do ‘absolute precision’ for access control.
Why Can’t One Database Rule Them All?
Everyone dreams of the silver bullet DB. Vectors promise AI nirvana. But production apps? They’re Frankenstein beasts: unstructured docs for RAG, structured tables for ops.
History rhymes here — my unique take. Flash back to 2010 NoSQL frenzy. MongoDB evangelists trashed MySQL as ‘web-scale dinosaurs.’ Startups ditched relations for schemaless joy. Then transactions hit. Money moved. Back to Postgres they crawled, tails tucked. Today? Document stores still niche; relations rule 80% of backend spend. Vectors? Same hype cycle. Five years from now, we’ll laugh at ‘vector-only’ pitches.
Who’s making bank? Pinecone’s valuations soar on VC fumes — $750M last round. Postgres? Free, battle-tested, runs the world. Hybrid wins mean Supabase or Neon (Postgres wrappers) eat their lunch.
Hybrid Architectures: pgvector Saves the Day?
Enter the practical fix: hybrids. Slap pgvector — Postgres’ vector extension — into your relational setup. Semantic search inside SQL’s fortress. One DB, dual powers.
Query joins vectors with user tables. ‘Find mold docs for tenant X, created post-Jan 1.’ Boom — semantic + filters + auth in one go. No microsecond lags syncing separate stores.
Other plays: LanceDB for lightweight vectors, or app-level orchestration piping Pinecone to Postgres. But pgvector’s free, scales with your existing skills. No vendor lock-in to some vector startup praying for acquisition.
Cynical aside — vector pure-plays push ‘full-stack’ to upsell. But check their docs: even they whisper ‘pair with relational for prod.’
I’ve grilled founders at AI summits. Those scaling past 10K users? All hybrids. The vector-solo holdouts? Pivoting or folding.
Dense dive: Setup’s simple. CREATE EXTENSION vector; Embed, index, HNSW for speed. SQL views mash vectors with metadata. Billing queries untouched. State pristine. Hallucinations tamed. It’s not sexy. But it ships.
Prediction: By 2025, 90% of new AI apps launch hybrid. Vector vendors pivot to ‘enterprise add-ons’ or die.
One-sentence warning: Skip this, watch your app fracture.
Who Wins in This Data Duel?
Users get reliable AI. Founders avoid fire drills. But cash? Cloud giants — AWS Aurora with vectors, Google AlloyDB. They bundle it, charge premium. Open-source Postgres? Democratizes, starves the hype machines.
Skeptical vet’s advice: Prototype with pgvector day one. Scale fears? Baseless.
🧬 Related Insights
- Read more: Simulating Stubborn Users: The Secret to Unbreakable Multi-Turn AI Agents
- Read more: Agent-First Redesign: The AI Shift That Could Leave Legacy Firms in the Dust
Frequently Asked Questions
What does a full data layer for AI applications really need?
Vector DB for semantic RAG, relational for users/billing/state. Hybrids like pgvector unite them.
Can vector databases replace SQL in production AI?
Nope. They flop on transactions, aggregations, guarantees. Use both.
Is pgvector good enough for enterprise AI?
Yes — powers Perplexity, scales to millions. Free, SQL-native.