DeepSeek R1’s launch in January 2025: Intelligence Index 62, app downloads exploding past ChatGPT’s.
China just rewrote the open-weight playbook.
And here’s the kicker—Nvidia stock tumbled nearly 20% in days, as if Wall Street suddenly clocked the shift from US-centric AI dreams to a Beijing-powered reality. DeepSeek didn’t just release parameters; they dropped a consumer chatbot flaunting its full chain-of-thought reasoning, raw and unfiltered. Electric, right? That move sparked a frenzy—Chinese firms piled on, turning open models into their secret sauce.
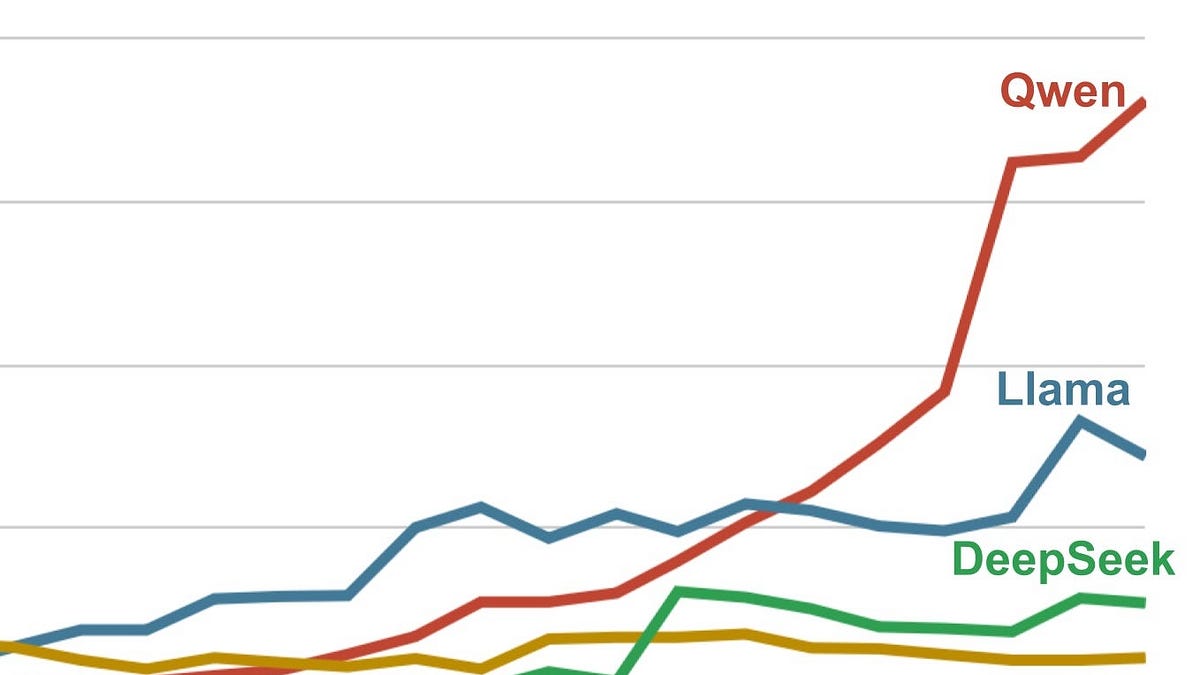
Before R1, Meta’s Llamas ruled the roost. Now? Alibaba’s Qwen family dominates downloads on Hugging Face, per ATOM Project stats. Moonshot’s Kimi, DeepSeek again, Z.AI—they’re all duking it out, mostly from China. US players? OpenAI trickled out weights in August, IBM’s Granite in October, Google and pals chiming in. None crack the top tier.
Look, this isn’t hype. It’s architectural: Chinese teams nail dense, efficient scaling across sizes, from 4B to 235B params, runnable on potato hardware. US efforts feel scattered, chasing closed-model glory while open stagnates.
Qwen: Alibaba’s Efficiency Machine
Alibaba’s Qwen3 lineup—picture this: a 4B thinker scoring 43 on Intelligence Index, up to 235B at 57. Released steadily through 2025, like clockwork.
Nathan Lambert nailed it at PyTorch conf:
“Qwen alone is roughly matching the entire American open model ecosystem today.”
Enterprises love ‘em for pipelines—simple tasks, chained up, on cheap rigs. Small models shine here, no GPU Armageddon needed. But at the massive end? Stiffer fights, and Qwen3-Max stays closed. Community’s buzzing, though—world’s most downloaded family.
Airbnb’s Brian Chesky spilled to Bloomberg: they’re leaning hard on Qwen for speed and cost. Whispers elsewhere, too. Yet—branding walls. Compliance nightmares. Can’t touch Chinese weights, even on-prem.
Lambert again, prescient in May:
“People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.”
Fear of backdoors, sans training data audits. Probably safe, says Lambert. But paranoia pays in boardrooms.
Kimi K2: Benchmark Beast or Local Nightmare?
Moonshot AI—startup since ‘23—unleashes Kimi K2 Thinking, 1T params, Index 67. Tops charts, arguably world’s best open model.
But good luck running it locally. Inference demands beastly clusters. That’s the trade-off: frontier smarts, deployed via API mostly.
China’s edge? Relentless iteration. They’re not waiting for perfect data; synthetics, distillation—whatever scales reasoning chains fast. US? Still debating ethics of open releases while China ships.
One para wonder: US open models trail because they’re afterthoughts to closed cash cows.
And my take—the unique bit nobody’s yelling yet: this mirrors ’80s chip wars. Japan flooded DRAM with efficiency, crushed US incumbents. America pivoted to logic chips, high-margin designs. Prediction: US AI will abandon raw open LLMs for agentic orchestration layers, where closed APIs glue open weights. China gets the compute hogs; we architect the symphonies.
Why Are Chinese Open Models Crushing Benchmarks?
Architecture first. Qwen’s MoE sparsity—mixture-of-experts—activates subsets per token, slashing compute. DeepSeek R1? Test-time compute scaling, dynamically allocating flops to hard problems, echoing o1 but open.
US rivals like Granite or Mistral? Solid, but no 67 Index kings. IBM’s Granite 4B-70B cluster around 50 max. Google’s releases? Incremental, not seismic.
Data moats matter. China’s got bilingual corpora, e-commerce floods from Alibaba, synthetic reasoning ladders. They train on chains humans can’t touch—volume trumps purity.
But geopolitics bites back. Export controls starve Chinese hardware access, forcing ingenuity: smaller models, better algos. US abundance breeds bloat.
Deep dive: Qwen3 VL 32B at 52—vision-language, multimodal without the bloat. Z.AI’s entries? Sneaky strong in coding. Moonshot’s K2 0905 precursor hit 50 at 1T, but Thinking mode leaped.
Can US Rally Before It’s Too Late?
OpenAI’s August drop—good, not great. Allen Institute pushes, Lambert rallies. But momentum’s east.
Here’s the why: US firms bet on proprietary edges—o1’s reasoning stayed closed longest. China open-sourced to ecosystem-build, leapfrogging via community fine-tunes.
Shift underway? Nvidia’s panic hints yes. Expect US consortia—xAI? Meta doubling Llama? But China’s pace—monthly drops—feels unstoppable.
Skepticism check: Benchmarks lie sometimes. Real-world? Qwen powers Airbnb ops fine. Kimi chats smarter. Still, safety gaps linger.
Two sentences, dense: Corporate spin calls this ‘collaboration era.’ Nah—it’s a wake-up, US open AI’s been napping.
The Road Ahead for Open Weights
235B Qwen3 A22B—2507:1 ratio? Quantized wizardry, runs on consumer GPUs. That’s how.
US needs: synthetic data floods, MoE mastery, and ditching China-phobia for audits. Or pivot, like ’80s chips.
China wins efficiency wars. US? Innovation niches.
🧬 Related Insights
- Read more: RSAC 2026: AI’s Cyber Arms Race Accelerates — But Who’s Winning?
- Read more: Netcode Nightmares: One Dev’s Multiplayer Meltdown in a Wargame Sprint
Frequently Asked Questions
What are the top Chinese open-weight models?
Qwen3 series (4B to 235B), DeepSeek R1, Moonshot’s Kimi K2 Thinking—leading Intelligence Index scores, from Alibaba and startups.
Why can’t US companies use Qwen models?
Branding, compliance fears—backdoor worries despite weights being open; no training data transparency.
Will US open models catch up to China?
Possible via agentic shifts and data innovation, but China’s iteration speed sets a brutal pace—watch 2026 releases.



