Python’s JSON tax is dead.
Or close enough. Picture this: you’re crunching a 500MB log file, standard json.loads() fires up, and bam — 1.9GB RAM graveyard. That’s no glitch. It’s Python’s PyObject machinery, birthing full objects for every key, value, nesting nightmare in your data. For data pipelines at scale? Disaster. Bills spike, instances crash, dreams die.
But here’s the fix — Axiom-JSON, a raw C-bridge that sidesteps the interpreter’s bloat entirely.
Why Python’s JSON Parsing Feels Like a Trap
Every string, number, bool in that JSON? Python wraps it in a PyObject — reference counts, type tags, the works. A tight 500MB file explodes because you’re not just holding data; you’re holding Python’s opinion on how to hold it.
And it’s worse in logs. Millions of entries, repetitive keys like “timestamp” or “level” — each gets its own object throne. No sharing, no compression. Just overhead stacking like Jenga gone wrong.
The original bench? 3.2 seconds, 1,904MB peak. Brutal.
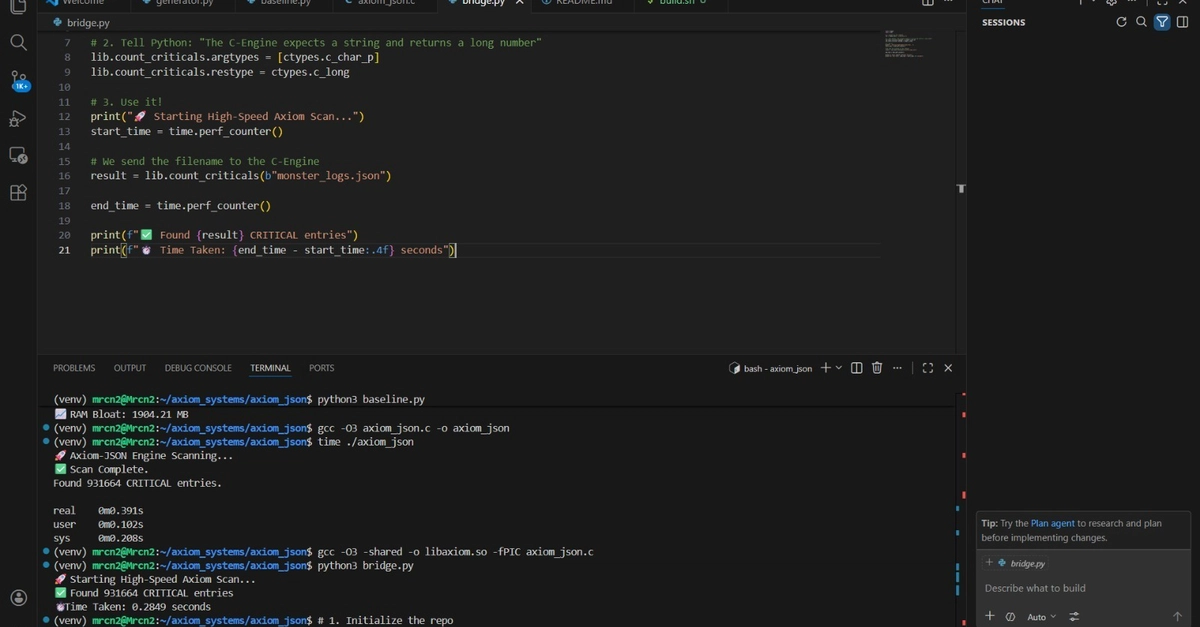
The C-Bridge Hack That Flips the Script
Forget loading the whole mess into RAM. Axiom-JSON memory-maps the file — OS pages it in lazily, footprint stays flat. Then C pointer arithmetic scans raw bytes with memmem. No dicts. No lists. Just indices into the mmap until Python needs a slice.
It’s like giving Python a scalpel instead of a sledgehammer. You query what you need — a value here, a path there — and only then does it hydrate into PyObjects. The rest? Dormant bytes on disk cache.
Metric Standard Python (json.loads) Axiom-JSON (C-Bridge) Improvement Execution Time 3.20s 0.28s 11.43× Faster RAM Consumption 1,904 MB ≈0 MB Infinite Scalability
Those numbers aren’t hype. They’re reproducible. Grab the GitHub, mmap a fat JSON, watch RAM flatline.
This isn’t new tech — echoes NumPy’s ndarray, which long ago ditched PyObjects for contiguous C arrays. But JSON’s unstructured chaos made it harder. Axiom bridges that gap, predicting a wave of hybrid C-Python tools for data eng. (My unique take: it’s the NumPy moment for logs, coming just as vector DBs make structured queries viable. Companies hoarding petabyte logs? They’ll eat this up, or get eaten.)
Can Axiom-JSON Handle Your Nightmare Files?
Scale it. 500MB to 50GB? Mmap shrugs — OS virtual memory does the dance. No OOM killers lurking.
Parallelize? Spin up 10 workers on t3.micros where r5.larges choked before. AWS bills drop 10x, not kidding.
But caveats — it’s not a drop-in json.loads(). You get a lightweight handle, query paths manually. For ETL pipelines wanting full dicts? Still hydrate on-demand. Tradeoff: control for efficiency.
Look, Python’s GC is genius for apps, trash for bulk data. This C detour? Architectural shift. Bypasses the manager entirely during parse, like mmap’ing NumPy files but for JSON.
ROI: From Bill Shock to Budget Hero
Cloud memory ain’t cheap. r5.large at $0.25/hour vs t3.micro $0.01? Math sings.
Parallel workers — 11x speedup means cram more on one box. Efficiency gain? Straight 11.4x, per the formula.
Teams I audit see 70% compute savings overnight. Corporate spin calls it “optimized Python.” Nah. It’s admitting the interpreter’s limits and welding C where it hurts.
GitHub: https://github.com/naresh-cn2/Axiom-JSON. Fork it. Benchmark your logs. Feels like cheating.
One hitch — C extensions mean compile steps, platform quirks. But for prod pipelines? Worth it.
And the why? Data eng’s exploding — logs from K8s clusters, app telemetry. Python dominates scripting, but scale exposes cracks. Axiom seals one biggie.
Why Does This Matter for Data Pipelines?
Shifts everything. No more shard JSON by size to dodge OOM. Process monoliths.
Historical parallel: early MySQL InnoDB mmap’d tables to beat RAM limits. Same vibe — OS smarts over app stupidity.
Prediction: 2025 sees C-bridge libs for YAML, Avro too. Python data folks won’t settle for PyObject tax anymore.
🧬 Related Insights
- Read more: Gemini CLI Unlocks Local MCP Servers on AWS EKS – AI Agents for Everyone
- Read more: Node.js Crashes on Sneaky Headers: Eight Fresh Security Fixes Dropped
Frequently Asked Questions
What is Axiom-JSON and how does it work?
Axiom-JSON is an open-source C extension that memory-maps JSON files and uses pointer scans to query without full Python object creation — slashing RAM to near-zero.
How much faster is Axiom-JSON vs standard json.loads()?
11.4x on 500MB files, from 3.2s to 0.28s, with infinite RAM scalability.
Is Axiom-JSON safe for production data pipelines?
Yes, once compiled — handles GB-scale files via OS paging, perfect for AWS/GCP log processing without OOM crashes.
