Performance on long-context benchmarks tanks 40% for top LLMs like GPT-4o beyond 50K tokens. That’s not a glitch. It’s baked in.
And here’s the kicker: companies keep bragging about million-token windows like it’s progress. Spoiler—it’s lipstick on a pig.
Recursive language models—RLMs for short—popped up to slap that pig awake. They’ve been buzzing on X and LinkedIn, the usual hype nurseries. But let’s cut the crap. These aren’t magic. They’re a hack born from desperation, forcing LLMs to chew massive inputs without barfing them back up half-digested.
Why Your Million-Token LLM Forgets Its Own Prompt
“They often miss details present in the provided information, contradict earlier statements, or produce shallow answers instead of doing careful reasoning. This issue is often referred to as ‘context rot’.”
Context rot. Love the name—sounds like a bad sci-fi plot. But it’s real. Transformers? Their attention dilutes over long hauls. Imagine scanning a 100K-token novel while hungover. Key plot points? Gone.
Mix in logs, code, chats—heterogeneous slop—and the model drowns. Retrieval? Lossy summaries that chop out gold. Agents? Fancy wrappers that still choke on scale.
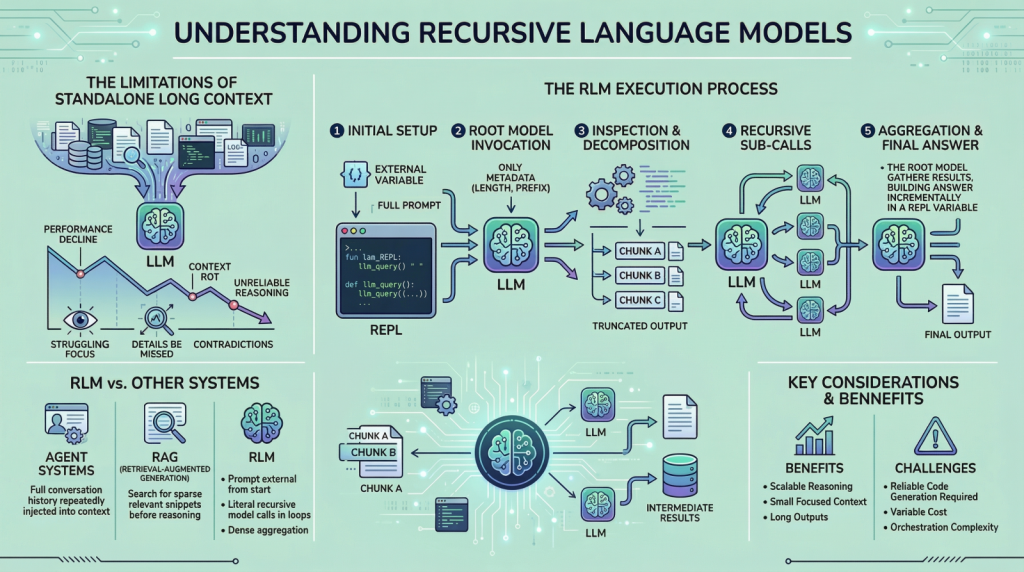
RLMs sidestep this. Treat the prompt as an external blob. Model gets metadata only. Needs a nibble? It calls a function. Keeps context tiny, focused. Smart? Sure. Revolutionary? Please.
How Recursive Language Models Work (No PhD Required)
Boot a Python REPL. Shove the mega-prompt in as a variable. Hand the root LLM a stub: ‘Hey, full text in prompt. Query it via sub_RLM(text). Go.’
Model spits commands. ‘Examine lines 500-600.’ Runtime slices, feeds a sub-call. That sub-model reasons, summarizes, returns. Rinse, recurse.
It’s like Russian dolls of reasoning—each layer peels just enough. Context stays lean, say 4K tokens max. No diffuse attention fog. But—and this is the acerbic part—it’s a compute bonfire. Each recurse? Fresh LLM inference. For 1M tokens? You’re burning cash like a VC at happy hour.
Step three: aggregate. Top-level model weaves sub-results. Output pops. Elegant on paper. Messy in prod.
Short version: recursion turns passive reading into active querying. Feels human—skimming a book, dog-earing pages. But LLMs aren’t humans. They’re expensive parrots.
Is Long Context Even Worth Saving?
People Google this: “Why do LLMs fail on long prompts?” Answer: because they’re not built for it. Transformers scale quadratically in attention—hello, KV cache hacks—but reasoning? Still linear slop.
RLMs echo old-school programming. Remember recursive descent parsers from compiler class? Worked great for toy grammars. Crashed on real code with stack overflows. History rhymes—RLMs risk infinite loops if safeguards suck. (Guardrails? Ha, that’s another subscription tier.)
My unique hot take: this mirrors the 90s LISP revival flop. Recursion lovers hyped it for AI. Reality? Tail-call optimization saved the day in theory; production stacks laughed. RLMs? Same vibe. Niche for PhDs, not your SaaS dashboard.
The Tradeoffs Big Labs Hide Behind NDAs
Pro: Handles arbitrary size. No window limits. Reasons deeply—aggregates across eons of text.
Con one: latency explodes. Single pass? Seconds. Recursive tree? Minutes, hours. Users hate waiting.
Con two: cost. OpenAI charges per token. Recurse 10x? 10x bill. Enterprises wince.
Con three: debugging hell. Sub-calls bury errors. ‘Why’d it miss that fact?’ Trace the call graph. Fun times.
And reliability? Sub-models inherit biases, hallucinations cascade. One bad recurse poisons the tree.
“Instead of forcing the model to absorb the entire prompt at once, they let the model actively explore and process the prompt.”
Active exploration sounds sexy. Reality: scripted queries in a REPL cage. Not true agency—just fancier prompting.
Real Use Cases: Beyond the Demo Reel
Forensic log analysis. Sift terabytes of server spew for the needle.
Legal doc review. Contracts stacked miles high—recurse to cross-reference clauses.
Codebase Q&A. ‘Find all deps in this monorepo.’ No RAG hallucinations.
But everyday? Nah. Chatbots don’t need this. Summarize a novel? Use a cheaper model.
Prediction: RLMs niche-ify fast. Like vector DBs post-RAG peak—essential for 1%, overkill for 99%.
Corporate spin screams ‘breakthrough.’ Yawn. It’s iterative engineering, not the singularity.
Look, props for tackling rot. But don’t drink the recursion Kool-Aid. Compute walls loom. Simpler fixes—like better training—might win.
Why Does Recursive LLM Matter for Developers?
Devs: tired of needle-in-haystack fails? Roll your own REPL. LangChain has primitives. But scale it—watch AWS bills spike.
Unique insight—here’s the parallel: SQL’s recursive CTEs (common table expressions) promised hierarchical queries in the 2000s. Hype train left the station when joins outperformed recursion 10:1 on cost. RLMs? Betting the same fate unless inference drops 100x.
Start small. Test on 100K docs. If latency kills UX, back to drawing board.
🧬 Related Insights
- Read more: Apple’s War on Slop: Cracks in the App Store Fortress
- Read more: Inference Scaling: Why It’s Silently Crushing LLM Training Limits
Frequently Asked Questions
What are recursive language models?
RLMs process huge inputs by recursing sub-model calls on chunks, keeping context small via an external REPL—fix for LLM ‘context rot’ on long prompts.
How do recursive language models differ from long-context LLMs?
Long-context stuffs everything in one pass (fails via diffuse attention); RLMs query externally, recurse for focused reasoning—but multiply compute costs.
Will recursive models replace RAG or agents?
Unlikely. They’re complementary for extreme scale, but pricier and slower—stick to RAG for most retrieval tasks.




