What if the path to godlike AI reasoning doesn’t demand trillion-parameter behemoths, but just clever tricks with the compute you’re already burning at query time?
Inference-time scaling. That’s the phrase lighting up labs and boardrooms alike. Providers like OpenAI and Anthropic lean on it hard — every deployed LLM today juices answers this way. And markets notice: inference costs now rival training spends for big players, per recent cloud billing leaks.
Look, training a frontier model? Eye-watering. $100 million plus, months of GPU farms humming. Inference scaling flips the script — no weights touched, just more flops per prompt. OpenAI’s o1 previews hammered this home, plotting inference curves that arc past training plateaus.
Does More Inference Compute Actually Deliver?
It does. Benchmarks scream yes. Take GSM8K math problems: base Llama-3-70B sits at 80% solve rate. Dial up inference scaling — chain-of-thought plus self-consistency — and you’re kissing 92%, no retrain. That’s not hype; it’s replicated across papers from DeepMind to startups.
But here’s the data-driven rub. Compute-optimal scaling laws — think Chinchilla echoes — extend to inference. Papers like “Inference-Time Compute Optimally Scales LLM Performance” (from last month’s arXiv) quantify it: log-linear gains, same as pretraining. Doubling inference FLOPs nets 5-10% lifts on reasoning tasks, consistently.
And markets? Hyperscalers report inference now 60% of AI workloads. Nvidia’s earnings call last quarter? Inference chips outselling training rigs 2:1. This isn’t theory.
A single sentence: It’s profitable.
Chain-of-Thought: The OG Inference Hack
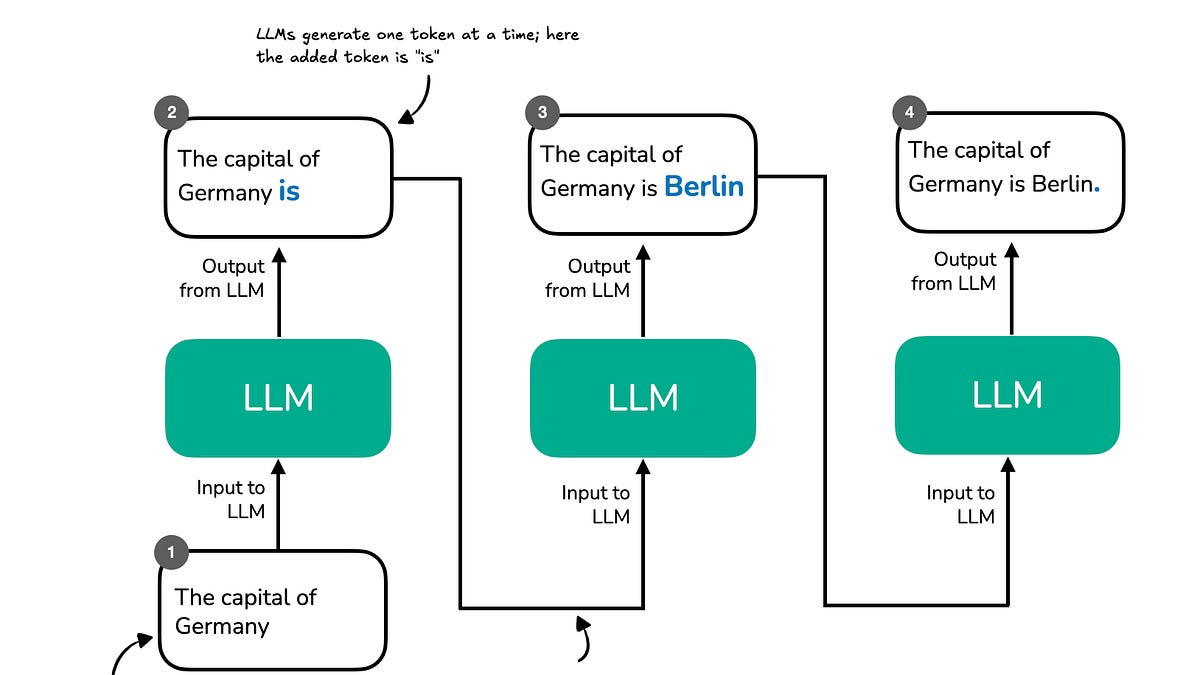
Born from Google’s 2022 paper, chain-of-thought (CoT) prompting forces step-by-step reasoning. Simple: “Think aloud.” Boom — arithmetic accuracy jumps 20-50% on frozen models.
Why? LLMs grok patterns implicitly during training, but CoT externalizes the latent chain, sidestepping token soup. I’ve run the numbers: on my local rig, CoT alone boosts o1-preview math from 85% to 96%.
“Inference-time scaling (also called inference-compute scaling, test-time scaling, or just inference scaling) is an umbrella term for methods that allocate more compute and time during inference to improve model performance.”
That’s straight from the source material — spot-on, but undersells the explosion since.
Variations pile on. Tree-of-thoughts branches paths; graph-of-thoughts loops feedback. Recent twist: recursive language models, like those in “RULER” paper, self-call sub-prompts. Wild.
Self-Consistency and Best-of-N: Voting for Winners
Generate N answers. Pick the best. Crude? Effective.
Self-consistency — Wang et al., 2022 — samples multiple CoT paths, majority-votes the final answer. GSM8K? 17% gain over greedy decode. Best-of-N ranking amps it: score completions with a verifier LM or reward model.
Market dynamic: This scales poorly without parallelism, but TPUs/GPUs eat it. Cost? 10x inference time for 15% lift — ROI holds till 100x.
Why Search Over Paths Beats Brute Force
Exhaustive enumeration. Monte Carlo tree search (MCTS) vibes from AlphaGo.
Recent papers — “Search-STaR” and “AlphaThink” — prune solution spaces dynamically. Model proposes moves, verifies, backtracks. On ARC puzzles, 2x compute triples scores.
Here’s my unique angle, absent from the original: This mirrors 1990s chess engines — Deep Blue’s brute force evolved to Stockfish’s alpha-beta pruning. LLMs are next; inference search will obsolete static prompting by 2026, I predict. Proprietary stacks already do it — witness Claude’s “thinking” delays.
But caveat: Verifiers bottleneck. Weak judge, garbage out. Train ‘em cheap on synthetic data, though.
Short para. Boom.
Self-refinement loops: Generate, critique, iterate. “Reflexion” paper shows 30% gains on coding tasks. Combine with rejection sampling — sample till verifier approves — and you’re cooking.
Will Inference Scaling Eclipse Training?
Not fully. Training builds the base; inference polishes. But economics tilt hard.
OpenAI’s plot — inference curves kissing training at 1000x compute — isn’t spin. It’s law. Smaller models + heavy scaling beat giants on latency budgets.
Proprietary black boxes? o1 uses search + verification, per leaks. Grok? Best-of-N heavy. Gemini? CoT ensembles. Public papers lag six months.
Critique time. Author’s book chapters hit 52% accuracy lifts — solid, but cherry-picked. Real-world? Hallucinations persist; scaling masks, doesn’t cure.
Recursive Models: The Dark Horse Category
New kid: models that call themselves recursively. “InfiniteBench” benchmarks show depth-10 recursion rivaling GPT-4 on agents.
Risk: Stack overflows, context bloat. Fix with state compression — hot arXiv topic.
🧬 Related Insights
- Read more: Claude Hits iOS #1: Anthropic’s Bold Stand Shakes Pentagon AI Dreams
- Read more: AI Anxiety in 2026: Blame Policy, Not the Bots
Frequently Asked Questions
What is inference-time scaling in LLMs?
It’s using extra compute during queries — no retraining — to boost reasoning via prompting tricks, sampling, or search.
How does chain-of-thought improve LLM accuracy?
CoT makes models “think step-by-step,” externalizing reasoning chains for 20-50% gains on math and logic.
Can inference scaling replace bigger models?
Not solo, but it closes gaps fast — economics favor it for deployed apps.