Your AI side hustle just got pricier.
If you’re renting H100s to train that agentic workflow or just crank out inferences at scale, expect to pay up—sometimes 50% more than six months ago. It’s not hype; it’s market reality hitting data center brokers and cloud providers alike, forcing everyone from indie devs to enterprise teams to rethink budgets in this reasoning-model frenzy.
Why H100 Prices Are Melting Up—Not Down
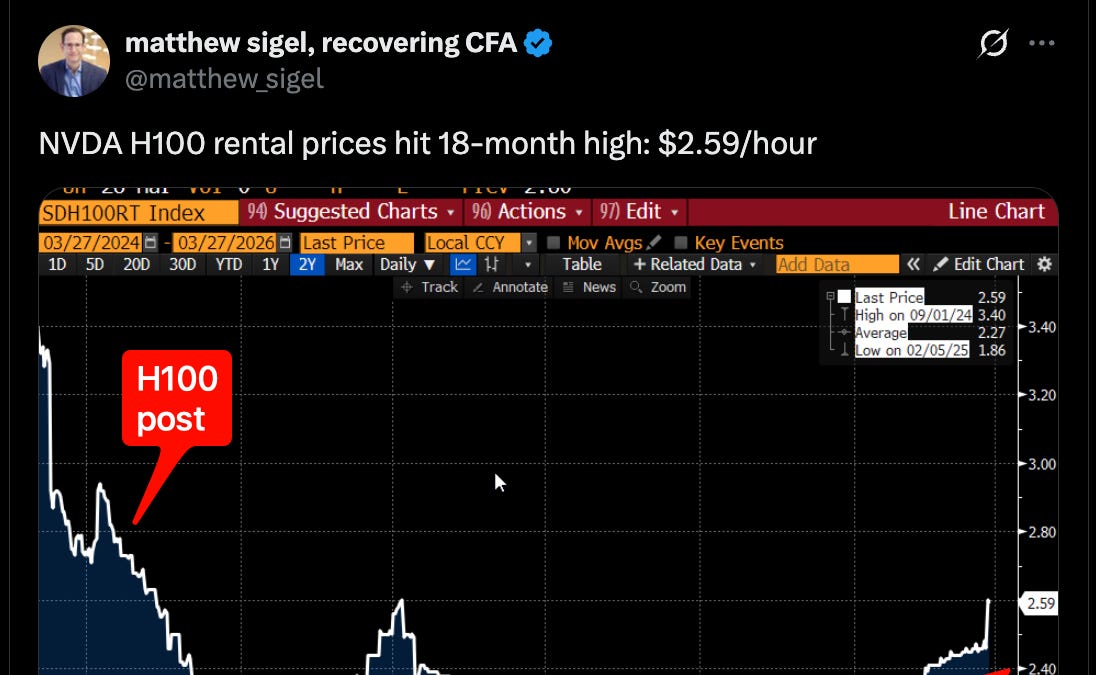
Look, two years post-launch—NVIDIA’s Hopper H100s dropped in October 2022—and you’d figure depreciation would kick in hard, right? Classic GPU cycle: announce, hype, flood the market, prices tank. But nope. After a quick dip we flagged back in October 2024 (blame DeepSeek’s R1 shock for that bubble-prick), rentals bottomed out… then rocketed since December 2025.
Data from rental trackers shows it clear as day. Spot rates on platforms like Vast.ai or Runpod jumped from sub-$2/hour lows to $3-4+ by early 2026. And it’s not isolated chatter—Dylan Patel nailed it on Dwarkesh’s podcast:
H100’s are worth more today than they were 3 years ago.
Chip shortages play a part, sure—global fab constraints biting everyone from TSMC to end-users. But the real driver? Reasoning models and agentic AI hitting prime time. Software leaps—better inference stacks like vLLM forks, optimized quantization—suddenly make these 4-year-old beasts punch way above their original weight. Who needs bleeding-edge Blackwell when an H100 crushes o1-preview evals at half the power draw?
Here’s the thing. Initial forecasts pegged 4-7 year depreciation. That’s out the window. Demand inflection from December’s model wave—think agent benchmarks exploding—has flipped the script.
Does This Break Data Center Economics?
Data center operators are sweating. They’ve modeled on razor-thin margins, banking on volume from depreciating Hopper stocks to undercut AWS or Azure. Now? Spot market volatility means they’re either hoarding for arbitrage or passing costs straight to you.
Take a mid-tier provider: buys H100s at $30k each last year, rents at $2.50/hour breakeven. Utilization dips to 60% during lulls, fine. But with rates spiking to $4/hour, they’re printing money—until customers balk and flock to local inference or Chinese open models like GLM-5.1.
And that’s the rub. This isn’t NVIDIA’s masterstroke alone; it’s ecosystem feedback. Anthropic’s leaked Capybara tier—bigger than Opus 4.6, crushing coding and reasoning evals—screams compute hunger. Fortune’s scoop, preserved in screenshots, hints at 10T-param scale, gated by power and capex. Google’s rumored funding for their data centers? Same story. Infra strain everywhere, from 529 errors plaguing Claude users to FT reports on funding crunches.
My take—and this is the insight headlines miss: it’s 2017 crypto winter redux, but inverted. Back then, ETH miners dumped GPUs en masse, crashing prices. Today, AI’s “reasoning winter” never came; instead, utility exploded. Bold call: H100 lifecycle stretches to 2028, delaying full Blackwell pivot and padding NVIDIA’s moat another 18 months.
Short operators win big. Long-term? Risky if open-source agents like Hermes eat hosted inference share.
Prices today.
One chart tells it: December 2025 trough at $1.80/hour. March 2026: $3.70 average. Corroborated across Reddit’s r/MachineLearning, Twitter threads from @scaling01, even Dwarkesh clips. It’s not noise.
Is Local Inference the Escape Hatch?
Smart money’s hedging local. Tweets buzz with wins: @TheGeorgePu ditches pricey TTS subs for Qwen 3.5 14B on a home rig. @LottoLabs clocks Qwen 27B + Hermes Agent economics crushing cloud. Quantization magic—TurboQuant forks, INT4 on RTX 6000—shoves 35B models into 24GB VRAM with 1% perf hit.
But drama brews. TurboQuant paper under fire for RaBitQ shade—Google’s ICLR claims disputed on benchmarks. Doesn’t kill the tech; just reminds us: engineering’s messy.
GLM-5.1 ramps pressure on closed coders. Zhipu’s rollout to all plans, agent docs—open gap narrowing fast per Arena leaderboards. Local’s viable for 80% workflows now.
Still, for frontier scale? H100s rule. Agents turning products—Nous’ Hermes with HF integration, 28 curated models—lean on clusters, not consumer cards.
NVIDIA grins. This uptick validates Hopper bets, juices Q4 earnings. Skeptics? Data centers might consolidate, birthing oligopoly pricing. Your LLM tab? Up 20-30% YoY.
Bet on sustained climb through Q2. Reasoning demand’s no fad.
The Bigger Picture: Compute as the New Oil
Frontier labs pivot to capex wars. Anthropic’s Mythos leak—Capybara above Opus, safety-constrained rollout—signals scale’s king. Production woes (those 529s) expose serving bottlenecks.
NVIDIA rides high. But here’s my editorial jab: their PR spins this as “ecosystem maturity.” Nah—it’s supply squeeze meeting demand tsunami. Don’t buy the spin; watch rental boards.
For real people—devs, founders—pivot now. Local for prototypes. Spot H100s for bursts. Lock long-term leases before Q3 fabs ramp.
Unique parallel: Bitcoin mining ASICs in 2021. Prices doubled post-halving on hash demand. Same dynamic—utility trumps age.
Prediction: H100s hit $5/hour peaks by summer if agent benchmarks keep soaring.
🧬 Related Insights
- Read more: D4RT: AI’s Leap to Seeing Time Itself
- Read more: KV Caches: The Hidden Speed Boost Powering Your Daily AI Chats
Frequently Asked Questions
Why are H100 GPU rental prices rising in 2026?
Reasoning model demand, inference software gains, and chip shortages revived a 4-year-old chip’s value—flipping expected depreciation.
Will H100 prices keep going up?
Likely through mid-2026, barring fab ramps; sustained agentic AI needs outweigh supply for now.
Should I buy H100s now or wait for Blackwell?
Rent spot if urgent; H100s viable 2+ more years at current perf/price.




