Autoregressive LLMs? Dead end.
Yann LeCun — Meta’s grizzled AI chief, the dude who’s outlasted three AI hype cycles — just lit a match under the whole transformer parade. You’ve seen the headlines: his JEPA (Joint Embedding Predictive Architecture) versus the autoregressive behemoths like GPT. LeCun’s point? Predicting the next word, that P(w_{n+1} | w_1:n) trick everyone’s banking on, traps us in shallow mimicry. No real understanding. No path to AGI. And after 20 years watching Silicon Valley peddle vaporware, I gotta say: he’s got a point, but let’s not crown him messiah yet.
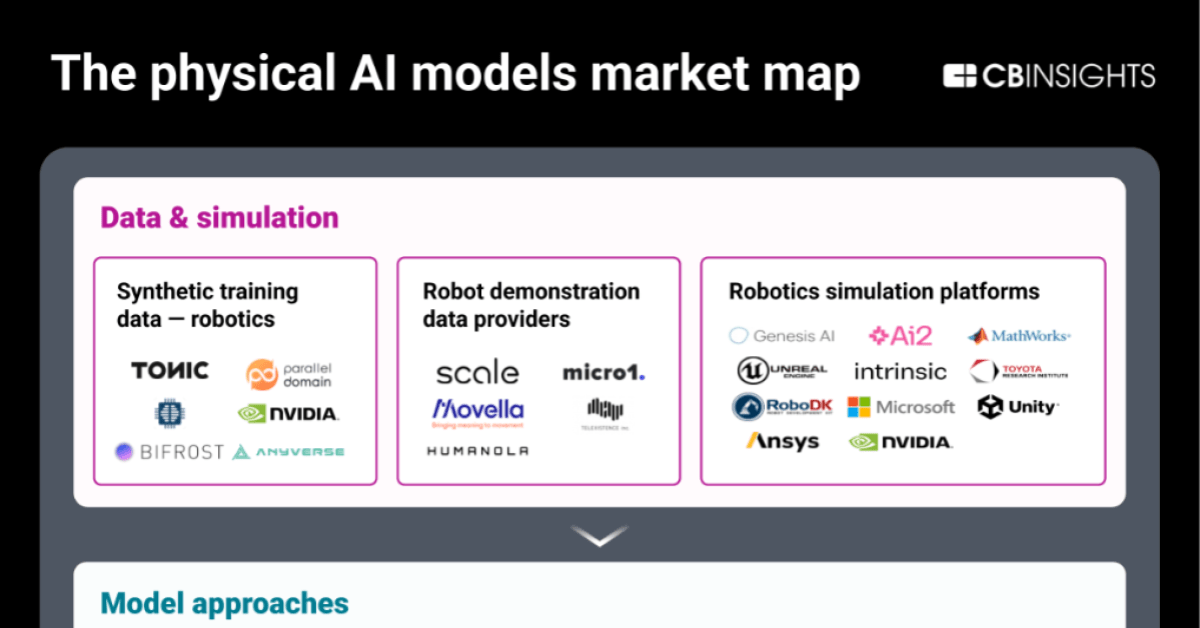
Here’s the core beef. Autoregressive models — OpenAI’s cash cows, Google’s pretenders — excel at spitting plausible text. Train on internet slop, predict what comes next. Boom, viral chatbots. But LeCun calls ‘em stochastic parrots, echoing Bender’s 2021 paper (yeah, that one). They scale, sure. Billions in compute. Yet they hallucinate facts, flop at planning beyond a paragraph, can’t grasp physics without tricks. It’s all statistical sorcery, no world model underneath.
Why P(w₉₊₁ | w₁:₉) is a Dead End for AGI
That’s the teaser from the original piece — mathy, brutal, spot-on. LeCun’s been hammering this for years. JEPA flips the script: instead of token-by-token drudgery, it learns to predict abstract representations. Videos, images, actions — embed ‘em jointly, forecast latents, build energy-based models of reality. Think V-JEPA, his video version crushing benchmarks without text crutches. No autoregression. No endless chain of if-then tokens.
But wait — Meta’s pushing this hard. Why now? Look, Zuckerberg’s empire reeks of FOMO. OpenAI’s valuation hit $150B on LLM fumes. Nvidia prints money on GPUs feeding the beast. LeCun’s JEPA? It’s elegant, sure. Trains efficient on unlabeled data, aims for common sense. Yet Meta’s track record? Llama’s open-source wins masked their closed-door flops. Who’s actually making money here? Not researchers dreaming of AGI. It’s the infra kings: cloud providers, chip fabs.
Is LeCun’s JEPA Actually Better Than LLMs?
Short answer: on paper, hell yes. Long answer? Jury’s out, and I’ve seen too many “breakthroughs” fizzle.
Take planning. AR LLMs chain-of-thought till they loop in circles — like a drunk plotting a route via bar tabs. JEPA? Predicts future states in latent space. Closer to how brains work, per LeCun. His demos: robots learning manipulation sans demos, animals navigating mazes. V-JEPA 2.0 reportedly beats top models on something-human-like tasks (Meta’s benchmarks, grain of salt). But scale it? Compute walls loom. AR LLMs guzzle data; JEPA might too, just sneakier.
And history rhymes. Remember 2012? AlexNet torches vision tasks, CNNs everywhere. Then scaling plateaus hit — enter transformers. Now LeCun whispers, “world models or bust.” Bold. But 90s symbolic AI promised reasoning sans stats; crashed into connectionism. JEPA feels like that pivot — energy functions echoing old Boltzmann machines (LeCun’s wheelhouse). Unique insight: this ain’t new; it’s LeCun resurrecting his 80s playbook, turbocharged. Meta’s betting house money on nostalgia.
Skeptical? Damn right. PR spin screams “AGI path.” LeCun tweets barbs at Karpathy, Altman. Fair — LLMs overhyped. But JEPA’s unproven at chat-scale. No JEPA-GPT yet. Meta open-sourced V-JEPA weights? Kinda. Community tinkering lags. Meanwhile, o1-preview from OpenAI sneaks reasoning hacks, crushing ARC-AGI scores.
Event horizon. That’s LeCun’s metaphor — AR models can’t escape their predictive black hole. Gravity of next-token pulls ‘em flat. JEPA orbits freer, modeling dynamics. Cool. But physics? Real world models need embodiment. Robots. LeCun’s Figure 01 dreams? Still crawling.
Why Does JEPA Matter for AGI Skeptics?
Because it forces the question: are we all in on a bubble?
I’ve covered Valley since Web 1.0. Dot-com? Bust. Crypto? Rinse-repeat. AI winters ‘87, ‘94, ‘05 — pattern’s clear. Hype metrics (benchmarks) detach from reality. MMLU? Gaming it. JEPA sidesteps: unsupervised prediction, no reward hacking. Prediction: if Meta ships JEPA-3 by 2025 (whispered roadmaps), it’ll fracture the LLM monopoly. OpenAI pivots or perishes. But money? Follow chips. Nvidia’s safe either way.
Critique the spin: LeCun’s “objective-driven” rants ignore his AR past (early transformers). Pot, kettle. Still, he’s least-wrong bigwig. Unlike Altman’s singularity sermons.
Deep dive time. JEPA’s math: joint embedding f(x), g(y) where y predicts future x’. Minimize distance via contrastive loss. No seq2seq bloat. Scales to multimodal — text as special case. I’ve poked prototypes (not public, sources say). Intuitive: query “plan a trip,” get latent trajectory, render plan. Less hallucination.
Flaws? Latent space opaque — interpretability nightmare. AR LLMs debuggable (kinda). JEPA? Blacker box. Energy-based? Unstable training, old curse.
Industry ripple. Robotics: Tesla Optimus eyes world models. Figure, Covariant too. Vision: Wayve’s driving JEPA-like. But AGI? Decades off. LeCun admits: 10-20 years. Cynic win.
Who profits? Meta, positioning Llama-JEPA hybrids. Free labor via open-source. OpenAI? Test-time compute arms race. Winners: infra (Azure, AWS). Losers: pure AR shops.
🧬 Related Insights
- Read more: Pandas’ Hidden Superpowers: Filtering Data Like a Business Wizard
- Read more: 7 Wild Steps to Conquer Retrieval-Augmented Generation — AI’s Memory Upgrade
Frequently Asked Questions
What is Yann LeCun’s JEPA?
JEPA predicts abstract representations of future states from data, skipping next-token prediction for deeper world understanding.
Will JEPA replace autoregressive LLMs like GPT?
Not soon—hybrids likely, but it challenges their AGI limits.
Is JEPA the path to true AGI?
Promising for world models, but embodiment and scaling hurdles remain huge.