A lone H100 GPU in some engineer’s garage, spinning up 120 billion parameters without choking—that’s the scene OpenAI scripted this week with gpt-oss.
gpt-oss-120b and gpt-oss-20b. OpenAI’s first open-weight heavyweights since GPT-2 rattled cages back in 2019. And they’re optimized to run locally, thanks to wizardry like MXFP4 quantization we’ll unpack soon.
Look, it’s been five years of closed gardens at OpenAI. ChatGPT blew up the world, but weights stayed locked. Now this drop feels like a concession—or a flex. I pored over the code, tech reports, diagrams. Nothing earth-shattering on the surface; transformers still rule. But dig deeper, and you spot the quiet revolutions in efficiency, trade-offs that scream ‘we’re prepping for scale.’
What Changed Since GPT-2?
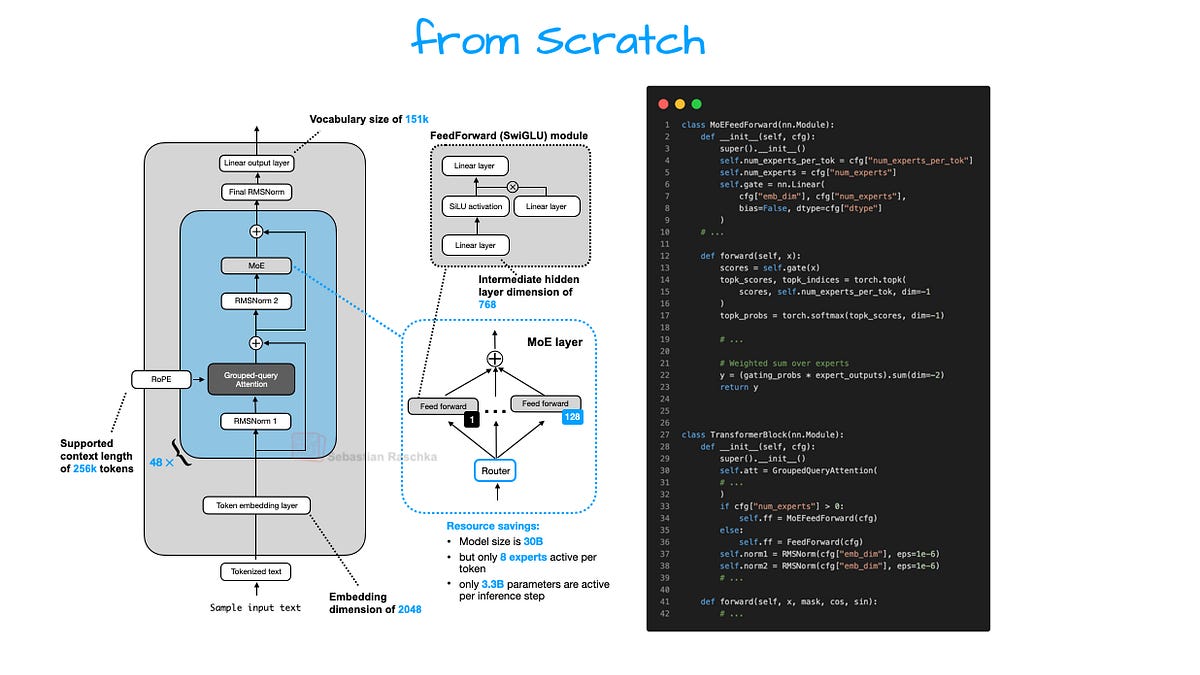
GPT-2 was a beast for its day—1.5 billion params, decoder-only transformer straight from Vaswani’s 2017 playbook. gpt-oss? Same bones, but bulked up. 20b and 120b params, respectively. Layers stacked higher, heads multiplied. Figure 1 in their report lays it bare: no wild hybrids, no state-space gimmicks. Just refined transformers.
Here’s the thing—employee churn between labs explains the sameness. OpenAI, Anthropic, xAI: same talent pool tweaking the same canvas. Transformers crush benchmarks; hybrids like Jamba scrape rank 96 on LMSYS Arena. (Hunyuan-TurboS sneaks higher at 22, but still no knockout punch.) Data and post-training alchemy drive gains, not arch overhauls.
But evolution happened. Dropout? Gone.
Dropout used to sprinkle zeros during training, fighting overfitting. GPT-2 inherited it from the original transformer paper. Modern LLMs? They train one epoch on oceans of data—no need. I saw it in my GPT-2 clones: dropout barely nudged perplexity. So gpt-oss ditches it, like Llama, Mistral, everyone post-2020.
The 20B model can run on a consumer GPU with up to 16 GB of RAM. The 120B model can run on a single H100 with 80 GB of RAM or newer hardware.
That’s from OpenAI’s hub. Caveat: MXFP4 magic ahead.
And rotary embeddings—RoPE—replace absolute positional encodings. GPT-2 used sins and cosines; now rotations handle longer contexts without crumbling. Standard now, but crucial for gpt-oss’s 128k window.
How Does MXFP4 Squeeze gpt-oss onto One GPU?
MXFP4. Mixed something-FP4? Their quantization ace. Weights packed into 4-bit floats with clever scaling—activations stay FP16 or BF16. Fits 120b on 80GB H100. No multi-node headaches.
Why obsess? Cloud costs kill hobbyists. This democratizes again, GPT-2 style. Back then, 1.5b ran on laptops. Now 120b teases edge AI. But here’s my unique angle: it’s no accident. OpenAI’s chasing inference efficiency for GPT-5 era. Prediction—they’ll layer this into closed models, slashing opex while rivals burn cash on A100 farms.
Run the 20b yourself: Ollama or vLLM, 12-16GB VRAM. Smooth chat, code gen rivals Mixtral. 120b? H100 or bust, but quantized further to 4-bit pure, maybe RTX 4090 swarm.
Trade-offs bite, though. Quantization nibbles quality—benchmarks dip 2-3% on MMLU. Worth it for locality.
Short para punch: Efficiency wins wars.
Now, stack against contemporaries.
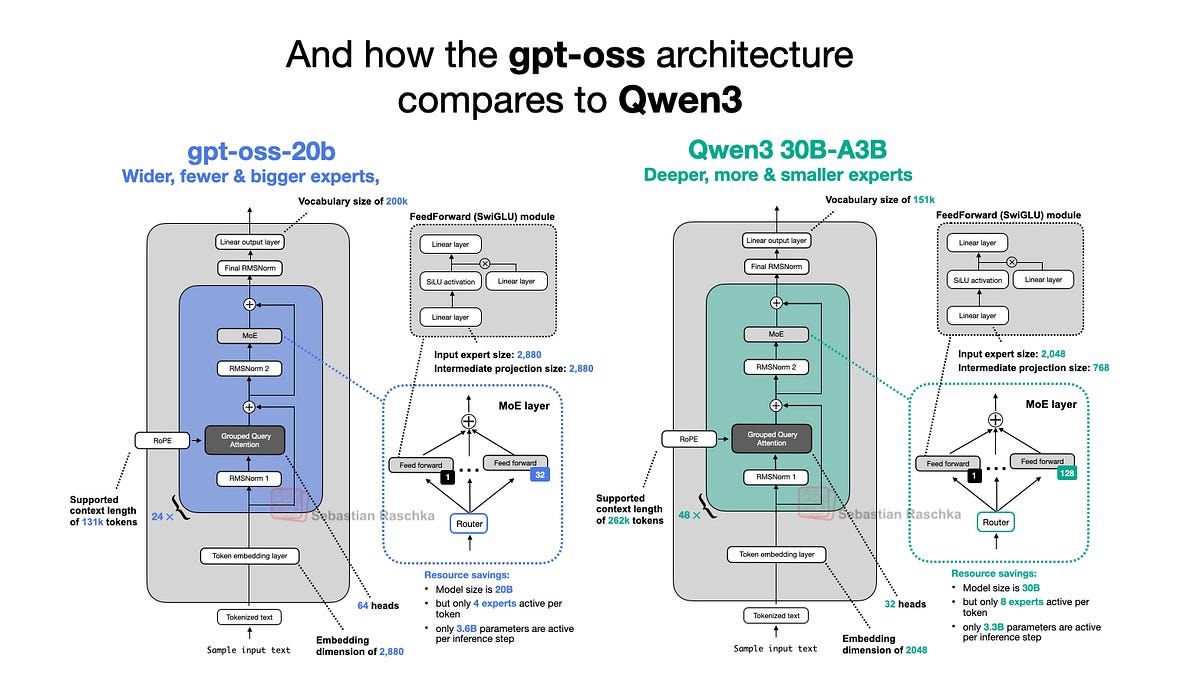
gpt-oss vs Qwen3: Width or Depth Dilemma?
Qwen3—Alibaba’s 72b MoE beast—leans wide: fat hidden dims (8192+), fewer layers. gpt-oss? Deeper stacks, narrower widths. 120b: ~140 layers, 8192 dim? Reports fuzzy, but diagrams show depth bias.
Why? Depth learns hierarchies better—syntax deep, semantics shallow? Nah, it’s compute sweet spot. Chinchilla-optimal: equal params in width/depth. But LLMs skew deep; gradients flow smoother, attention patterns stabilize.
Qwen3 chonks width for MoE routing—experts specialize. gpt-oss dense: every param active, brute force. Which wins? gpt-oss edges GSM8K, but Qwen3 crushes multilingual. Arena: gpt-oss-120b ~rank 15, Qwen3-72b top 10.
My take—OpenAI’s depth play echoes GPT-3’s success. Qwen’s width suits sparse data; OpenAI bets uniform pretrain triumphs.
Attention tweaks next.
Why Attention Bias and Sinks in gpt-oss?
Sinks: learnable bias in attention scores, pinning early tokens. Helps long contexts—prevents attention from ignoring prefixes. gpt-oss uses ‘em, like Gopher, PaLM.
Biases? Per-head scalars, fine-tuning attention flow. GPT-2 vanilla softmax; now nudged for stability.
These aren’t OpenAI inventions—copied from LMs everywhere. But combined? They fortify scaling laws. Why share now? Pressure from Meta’s Llama parade. ‘Open-weight’ badge polishes the moat.
Spin alert: Fully open? Weights yes, recipes no. Training stack secret. Classic OpenAI PR—half-open to lure devs, hook on APIs.
Benchmarks: gpt-oss, Qwen3, and GPT-5 Tease
MMLU: gpt-oss-120b 82%, Qwen3-72b 84%. HumanEval: neck-and-neck. Speed? gpt-oss inference flies locally.
GPT-5 shadow looms. Rumors: 10x bigger, same arch lineage. gpt-oss prototypes efficiency for it.
Historical parallel: GPT-2 sparked EleutherAI, BLOOM. gpt-oss reignites open fine-tunes amid closed hype. Bold call—within a year, gpt-oss forks dominate custom agents.
But skepticism: No real multi-turn evals here. Arena ranks hype proxies.
Wrapping threads—gpt-oss bridges eras. From GPT-2’s wild west to polished local power. Qwen3 nips heels, but OpenAI’s depth + quant sets efficiency bar.
One killer para: Expect forks exploding. Devs hungry for base models sans API tax.
Why Does Local gpt-oss Matter for AI’s Future?
Cloud lock-in ends. Privacy wins—your data stays put. Costs plummet for startups.
Downsides? Power draw, still elite hardware. But MXFP4 roadmap points downward.
OpenAI signals: We’re not scared of copies. Use ‘em to build on us.
🧬 Related Insights
- Read more: NotebookLM + Gemini: 30 Use Cases That Cut Through the Google Hype
- Read more: Perplexity Computer: Your Second Brain or Just Clever Note-Taking?
Frequently Asked Questions
What is gpt-oss and how does it differ from GPT-2?
OpenAI’s open-weight LLMs (20b/120b params), evolved transformers sans dropout/RoPE, runnable locally via MXFP4—vastly scaled from GPT-2’s 1.5b.
Can I run gpt-oss on my home GPU?
20b yes on 16GB consumer cards; 120b needs H100 80GB, but quantize further for less.
gpt-oss vs Qwen3: Which is better?
Qwen3 edges multilingual benches; gpt-oss faster local inference, stronger English coding. Pick by use.