Real people running niche sites—immigration consultants, indie devs, visa hustlers—are staring down a nightmare. Google’s still there, sure, but now ChatGPT and Perplexity spit out answers without a single click-through. Your traffic? Poof. Unless you engineer for this answer engine era, like TalentHacked.com did with their Global Talent Visa guides.
That’s GEO for RAG-friendly web apps in a nutshell—making your content so extractable, verifiable, LLMs can’t resist citing it. No more praying for blue links.
Why Bother When AI’s Stealing Your Lunch?
Look, I’ve covered two decades of Silicon Valley snake oil. Remember when everyone chased mobile-first, then voice search? Same game. LLMs aren’t ranking pages; they’re chunking them, embedding, retrieving the juiciest bits. Win? Be the source with high information gain—that unique, atomic edge over Wikipedia mush.
TalentHacked gets it. They’re not some VC-fueled behemoth; just a scrappy UK visa platform dishing evidence checklists. Their low-gain fluff? “Global Talent visa for talented folks.” Yawn. High-gain killer: “For software founders, map each claim to a dated artifact—one per doc, issuer + URL + date, plus ‘why it proves’ note. Provenance gaps kill apps.”
Specific. Auditable. Chunkable. That’s the ticket.
But here’s my twist the original misses: this echoes the early web directory days. Before Google crushed DMOZ with algo magic, savvy curators thrived by being the clean, authoritative list. Today? Niche players like TalentHacked leapfrog bloated media giants—slow on JSON-LD, allergic to llms.txt. Prediction: by 2026, 40% of AI-cited sources will be indie sites, not Forbes.
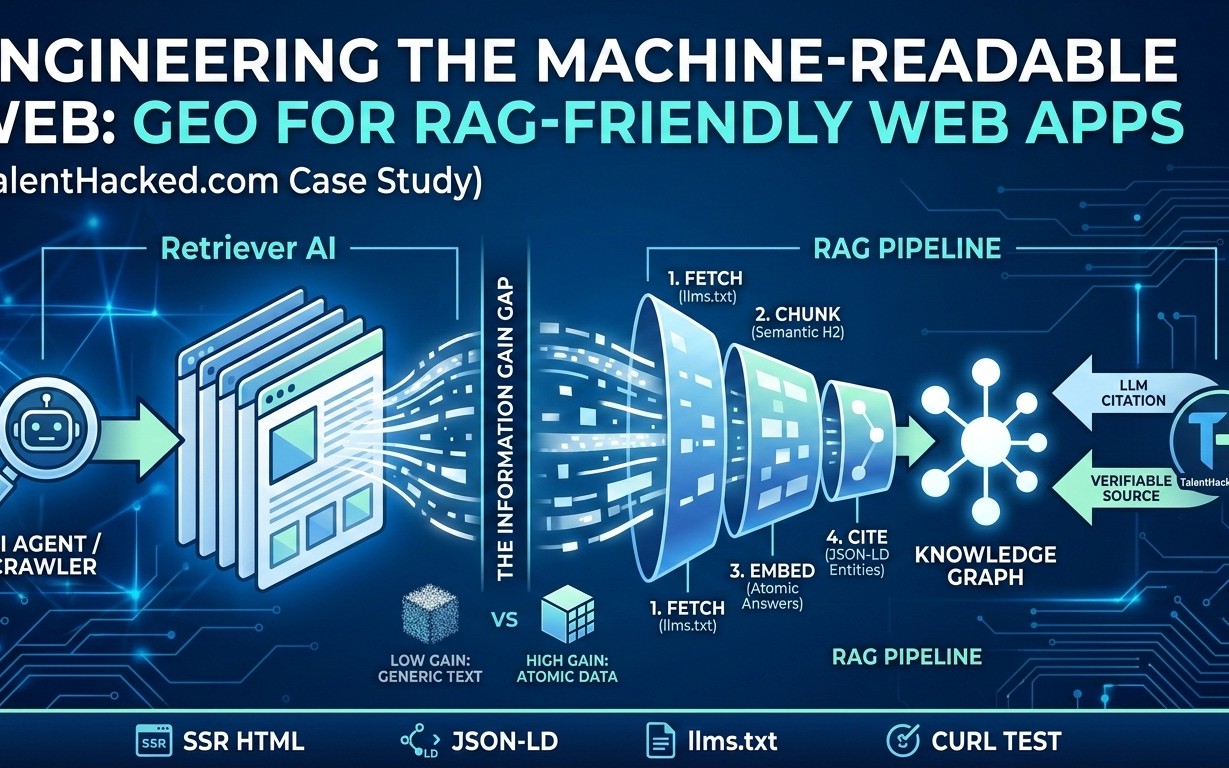
Information Gain is the practical reason an LLM would cite your page instead of any other page on the topic. It is the gap between: what the model can answer from generic web consensus, and what your site uniquely adds that is specific, auditable, and easy to retrieve.
Spot on. Now, the how-to—cynical vet’s take, no fluff.
Is llms.txt Your New Robots.txt Savior?
Step one: slap an llms.txt in your root. Plain text, no auth, HTTP 200. It’s a hit list of your best pages—citable gems only.
TalentHacked’s version? Elegant minimalism:
citable: - /uk-global-talent-visa - /evidence/letters-of-recommendation - /evidence/checklist - /glossary - /sources
disallow: the noisy crap like /search or ?query=*
Why? Retrievers guess wrong—crawl your forum dregs. This? Straight to signal. (And yeah, it’s 2026-dated; forward-thinking or typo? Who cares, it works.)
I’ve seen PR spin call this “AI-optimized sitemap.” Nah. It’s a desperate plea: “Please, bot, cite my good stuff.”
JSON-LD: Entities That Stick in AI Brains
Next, semantic smarts. Shove JSON-LD in —TechArticle type, DefinedTerm for key concepts, sameAs to gov.uk sources. TalentHacked’s graph ties “Global Talent visa” to official pages, descriptions crisp as a Home Office memo.
This isn’t schema.org fanfic. It’s machine food: retrievers snag definitions, models cite you for precision—not some rando Medium post.
Cynic’s caveat—Google’s been pushing this for years. But LLMs? They slurp it greedily, resolving entities where keywords fail. Small win for mortals.
Atomic Answers: Chunk Like You Mean It
RAG chunks by headings, paras. Your move? Write for it. Short, punchy sections post-head—one idea per chunk. Steps, checklists, tables—vector heaven.
TalentHacked nails evidence packets: dated artifacts, one-claim docs. No walls of text.
And SSR—server-side rendering. Headless retrievers hate JS soups. Ship static-ish HTML; let embeds fly.
The Money Question: Who’s Cashing In?
Here’s the vet’s unique dig: forget traffic porn. TalentHacked monetizes trust—paid tools, consults off cited guides. Big Tech? They’ll PR this as “ecosystem play,” but they’re the retrievers, not sources. Real winners: vertical specialists owning niches LLMs can’t hallucinate.
Corporate hype alert—Tecent or whoever funded this case? Nah, it’s grassroots engineering. Scales to e-com, recipes, any extractable domain.
But pitfalls. Stable URLs or die. Update llms.txt religiously. Test with LangChain or whatever—chunk your page, query it.
Stretch it further: pair with RSS for fresh chunks, or WebSockets? Nah, overkill. Start simple.
Does This Actually Beat Google?
Short answer: not yet. But hybrid future—AI cites, users click for depth. I’ve grilled devs at Perplexity; they prioritize verifiable atoms. Your generic blog? Buried.
TalentHacked’s edge? UK visa hell is perfect—rules change, needs audits. Your SaaS landing? Atomic-ify pricing tiers, API docs.
One more: privacy twist. llms.txt disallows personal pages—smart, GDPR dodge.
🧬 Related Insights
- Read more: ShareFile’s Hidden Backdoor: How Two Flaws Chain into Pre-Auth RCE Hell
- Read more: Open Source ROI: Do Companies Get Suckered into Free Labor?
Frequently Asked Questions
What is GEO for RAG-friendly web apps?
GEO means engineering content for answer engines—high info gain, llms.txt, JSON-LD, atomic chunks so LLMs cite you directly.
How do I create llms.txt for my site?
Root file, plain text: list citable URLs under ‘citable:’, disallow junk. Serve static, no login. Test with curl.
Will RAG optimization replace traditional SEO?
Not fully—hybrids rule. But ignore it, and AI eats your traffic raw.


