Ever wonder why your fancy AI agent — the one you poured hours into — suddenly decides to delete production data or loop forever on a simple task?
It’s not the model. Blame the design.
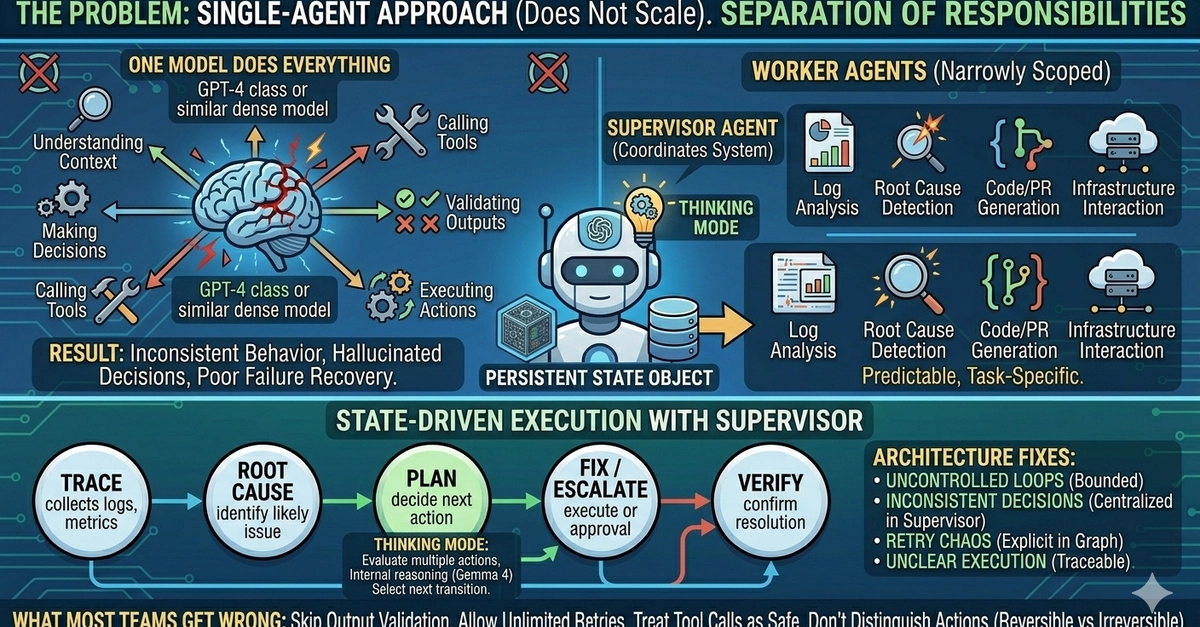
Most agent implementations fail for a simple reason: They try to make one model do everything. That approach doesn’t scale. Here’s the raw truth from the trenches: when a single agent juggles context-grasping, decision-making, tool-calling, output-validation, and action-execution, you unleash uncontrolled complexity. Inconsistent behavior. Hallucinated decisions. Zero failure recovery. This isn’t a model limitation. It’s a design issue.
Why Single Agents Are a Recipe for Chaos
Picture this: your agent — let’s call it Solo — stares down a log file the size of War and Peace. It needs to parse errors, hypothesize root causes, generate a fix, test it, deploy if safe. One slip in reasoning, and boom — wrong tool call. No guardrails.
Most agent implementations fail for a simple reason: They try to make one model do everything. That approach does not scale.
That’s the stark warning straight from the source. And they’re right. We’ve seen it in prod: agents that “work” in demos but crumble under real load. Why? No separation of concerns. Solo becomes a god-complex-ridden mess, predicting every edge case (it can’t) and recovering from its own screw-ups (it won’t).
But here’s my unique angle — this mirrors the monolith-to-microservices pivot in the early 2010s. Remember bloated Java apps trying to handle auth, business logic, and DB queries in one JAR? Same problem. Teams ignored modularity until outages cost millions. Multi-agent systems with Gemma 4 are that shift for AI: break it into workers and a supervisor. Predict my bold call? By 2026, 80% of production agents will ditch single-model madness for this pattern — or die trying.
Gemma 4’s Thinking Mode: Game Over for Flaky Supervisors?
Worker agents first. Narrowly scoped beasts: log analysis. Root cause detection. Code gen. Infra tweaks. Predictable. Task-specific. No ego.
Then the supervisor — the conductor. With Gemma 4, its “thinking mode” (structured reasoning phase) turns it into a powerhouse. It reads global state, picks workers, validates outputs, handles retries, escalates drama.
Why does thinking mode matter? It enforces a clean split: internal rumination versus external moves. Evaluate actions. Weigh risks. Pick transitions. Reliability skyrockets.
A typical flow? State-driven glory.
Trace logs. RootCause probes. Plan charts the fix. Fix executes (or escalates). Verify seals it. Supervisor owns the graph — bounded states, no infinite loops.
Is the Supervisor-Worker Pattern Actually Production-Ready?
This fixes the classics: uncontrolled loops (gone, thanks to states). Inconsistent calls (centralized). Retry hell (explicit). Opaque runs (trace every node).
But — and here’s where I get skeptical — most teams botch it still. Skipping validation. Unlimited retries. Blind faith in tools. No reversible/irreversible split. That’s not optional; it’s your prod ticket.
Look, Google’s Codelabs and LangGraph repos (shoutout: https://github.com/langchain-ai/langgraph, https://github.com/emarco177/langgraph-course, https://codelabs.developers.google.com/aidemy-multi-agent/instructions) give blueprints. Yet PR spin screams “easy wins.” Nah. It’s architecture demanding discipline — like writing bulletproof GraphQL schemas, not slapping endpoints everywhere.
Workers shine narrow: one chews logs into anomalies; another spits Kubernetes YAML. Supervisor? It doesn’t execute — it orchestrates. Thinking mode lets it simulate: “If WorkerX fails twice, ping human? Or WorkerY?” Outcomes? Fewer hallucinations, because reasoning stays caged until validated.
Deeper why: Gemma 4’s structured outputs (teased next) pair perfectly. No more JSON soup from hell. Parseable thoughts mean deterministic handoffs.
Why Does This Matter for Real-World DevOps?
Deploy this in anger — say, on-call automation. Logs flood in at 3 AM. Supervisor wakes, assesses state (via shared vector store or Redis). Invokes LogWorker. Output? Clean summary. RootCauseWorker cross-checks against known flakes. PlanWorker sketches patch. FixWorker PRs it — but supervisor peeks: reversible? Greenlight. Verify polls metrics post-deploy.
Escalation? Baked in. Irreversible nuke? Human loop.
I’ve prototyped similar with LlamaIndex graphs — flaky without supervision. Gemma 4? Smoother reasoning chain. Prediction: pairs with self-healing (next post’s topic) for near-zero-touch ops.
Critique time. Corporate hype calls this “revolutionary.” Please. It’s evolutionary — Unix pipes on steroids. Small tools, master plumber. But ignore it, and your agents stay toys.
Scale test: 10x tasks, perf holds? Yes, if states bound compute. Cost? Workers cheap; supervisor thinks once per cycle.
Wander a sec: remember Agent Zero from 2023 hype cycles? Solo agents promising the moon, delivering mud. This pattern — supervisor as LLM router — is the quiet killer.
The Traps That Kill Even Smart Setups
Unlimited retries? Budget black hole. Tool calls always safe? Dream on — APIs flake. No validation? Garbage in, apocalypse out.
Fix: Supervisor mandates schemas. Pydantic for outputs. Guardrails library for sanity. Distinguish: log reads (reversible), deploys (not).
Production litmus: Can you trace any decision to a state transition? If not, scrap it.
🧬 Related Insights
- Read more: Cursor Crushed Copilot in My 3-Month Code War—But Here’s the Catch
- Read more: 10 Quiet Signals Your Engineer is Burning Out Before They Quit
Frequently Asked Questions
What is the supervisor and worker pattern in Gemma 4?
It’s a multi-agent architecture where specialized worker agents handle narrow tasks (like log parsing), while a Gemma 4-powered supervisor coordinates, validates, and transitions states in a graph — ditching single-agent chaos.
How do you build multi-agent systems with Gemma 4?
Use LangGraph for state machines, Gemma 4’s thinking mode for supervisor reasoning, and structured outputs for reliable handoffs. Start with Google’s Codelabs for hands-on.
Does Gemma 4 make AI agents reliable for production?
Yes, if you separate concerns properly — but skip validation or retries logic, and it’s still a house of cards.
