LLMs exposed—build yours now.
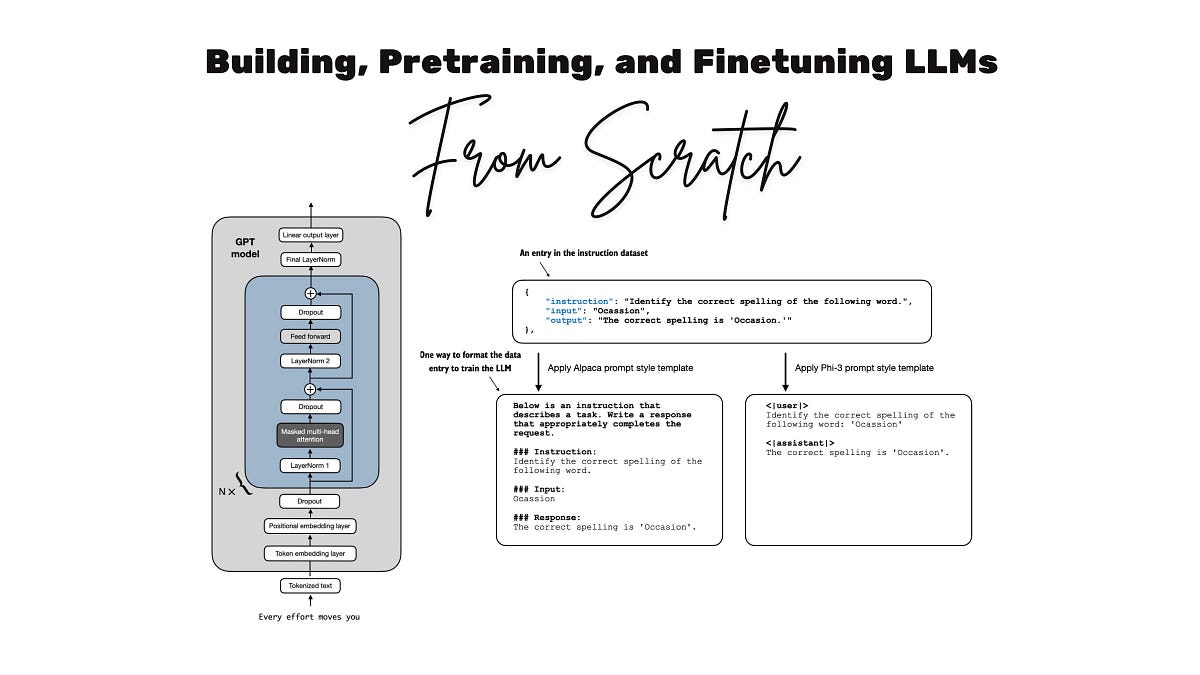
Coding LLMs from the Ground Up isn’t some fluffy intro. It’s a brutal, rewarding slog through the machinery that powers ChatGPT’s cousins, clocking in at 15 hours of pure code and explanation. Sebastian Raschka, the guy behind that seminal ‘Build a Large Language Model (From Scratch)’ book, drops this video series as recovery fodder from a neck injury—talk about turning lemons into LLM lemonades.
And here’s the thing: in a world drowning in pre-trained models you can fine-tune with a few lines, why bother coding from scratch? Raschka nails it with his go-kart analogy. Skip straight to a Formula 1 beast, and you’re lost in turbochargers and aerodynamics. But slap together a go-kart—steering, motor, the works—and suddenly, the pro car’s secrets click. Fun bonus: you can actually drive the damn thing.
Why Bother with Go-Kart LLMs?
Look, we’ve all API-called our way through demos. But that hides the architecture—the tokenizers gnawing text into bits, attention heads eyeballing contexts, transformers stacking like drunken Jenga. Raschka’s course forces you under the hood.
First video? Environment setup with uv pip—20 minutes of pip hell avoidance. Windows users, breathe: he even PyTorch-converted GPT-2 weights to dodge TensorFlow migraines. Smart.
Then, text wrangling. Tokenization. Byte-pair encoding. Data loaders churning Shakespeare or whatever into train-ready batches. It’s the unglamorous grind where 90% of real LLM work lives—not the shiny prompts.
“Building a go-kart still teaches you how the steering works, how the motor functions, and more. You can even take it to the track and practice (and have a lot of fun with it) before stepping into a professional race car.”
That’s Raschka, dead-on. His readers echo it: fun, intuitive, edge-giving. Echoes Ayrton Senna tinkering karts before F1 glory.
Attention: The Engine That Ate the World
Video three—pure gold. Coding self-attention, causal masks, multi-head madness from scratch. No libraries cheating. You feel the dot-products dance, the softmax squeeze relevance from noise.
Why does this matter? Attention’s the shift—from RNNs’ sequential plod to parallel context-guzzling. It’s why LLMs scale. Raschka builds it like assembling a V8: valves first (queries, keys), then camshaft (scaled dots), pistons firing (values).
By video four, you’ve got the full transformer stack. Embeddings. Positional encodings. Feed-forwards. It’s nano-GPT territory, runnable on your laptop.
Pretraining next—2.5 hours dumping unlabeled text through your beast. Watch loss plummet as it predicts next tokens. Magic? Nah, just backprop on steroids.
Fine-Tuning: From Dummy to Chatty
Classification first—spam detector via LoRA-ish tweaks (though he keeps it vanilla). Gentle ramp to instruction tuning, where you RLHF-lite your model into following orders.
Here’s my unique angle, absent from Raschka’s pitch: this mirrors 2017’s deep learning explosion. Back then, PyTorch was fresh; everyone coded nets from scratch because frameworks lagged. Fast-forward—no, screw that phrase—but today, amid agentic hype and 2025’s reasoning obsessions, we’re go-karting again. Why? Compute walls. OpenAI’s monsters guzzle datacenters; your from-scratch rig runs on a 3090. It democratizes the ‘how’ while Big Tech hogs the ‘scale.’ Bold prediction: this hands-on wave births indie innovators, tweaking architectures in garages like early GPU hackers did CNNs.
Raschka’s no hype machine. He admits it’s supplementary to his book, born from workshops folks devoured. Neck injury timing? Humanizes it—life’s curveballs over corporate gloss.
Can Your Laptop Handle Real LLM Training?
Short answer: for tiny models, yes. His GPT-2 clone sips resources. Scale to billions? Rent cloud, but you get the blueprint.
Bonus for subs: 2.5-hour retrospective, Llama 4 fresh off the press. 2018 GPT-2 to now—context length booms, multimodal creeps in, but core transformer’s unshaken.
Skepticism check: is this outdated amid o1-preview reasoners? Nope. Understanding foundations inoculates against trend-chasing. Agentic workflows? They lean on these blocks.
Raschka’s course shines because it’s code-first. No vaporware slides. Tinker, break, fix— that’s how pros learn.
One-paragraph rant: Corporate PR spins ‘frontier models’ as wizardry, but it’s iterative engineering. This course strips the spin, hands you wrenches. If you’re a dev eyeing AI jobs, or just hate black boxes, devour it.
Why Does Coding LLMs Matter in 2025?
Reasoning models dominate chatter. But agents? They chain these primitives. Code ‘em yourself, and you’re not just using—you’re architecting shifts.
Historical parallel: 1990s PC revolution. IBM mainframes ruled; hobbyists built clones, sparking netbooks-to-iPhones. LLMs next—scratch-builders erode OpenAI moats.
Practical wins. Debug tokenizers when Hugging Face hiccups. Tweak attention for domain data. Interview gold: “Walk me through causal self-attn”—nailed.
Drawbacks? Time sink. 15 hours plus coding marathons. But ROI? Immense.
Video timestamps guide you—supplementary drops like attention deep-dive slotted perfectly.
🧬 Related Insights
- Read more: Bedrock AgentCore’s Persistent Filesystems: AI Agents That Actually Remember
- Read more: Railway’s $100M Gambit: Custom Data Centers to Supercharge AI Devs
Frequently Asked Questions
What does coding LLMs from the ground up mean?
It means implementing every layer—tokenizers, attention, training loops—without libraries, using raw PyTorch to grok LLMs inside-out.
Do I need ML experience for Raschka’s course?
Basic Python and linear algebra help, but he explains from basics; ML newbies survive with grit.
Can I train this on my home PC?
Tiny models yes—GPT-2 small loads fine; bigger needs GPU cloud, but concepts transfer anywhere.


