Pager duty at 2:17 AM. That’s when petabyte-scale data pipelines reveal their true colors—choking on a single malformed schema, while your boss dreams of uninterrupted ML magic.
And here’s the kicker: building data pipelines at petabyte scale isn’t some badge of honor. It’s a Darwinian test where 99% of setups die quietly, wasting millions in compute before anyone notices.
Look. Traditional data engineering lets you skate by with sloppy joins and unoptimized loads. Tolerable at gigabyte scale. But crank it to petabytes? That 1% inefficiency? Terabytes of waste. Millions down the drain.
Teams I’ve watched—big names, fat budgets—still cling to monolithic beasts. Why? Laziness. Or fear. Doesn’t matter. They crumble.
At massive scale: Simple queries can take hours if schemas are poorly designed. Network bottlenecks can halt entire pipelines. Failures are not rare—they are guaranteed.
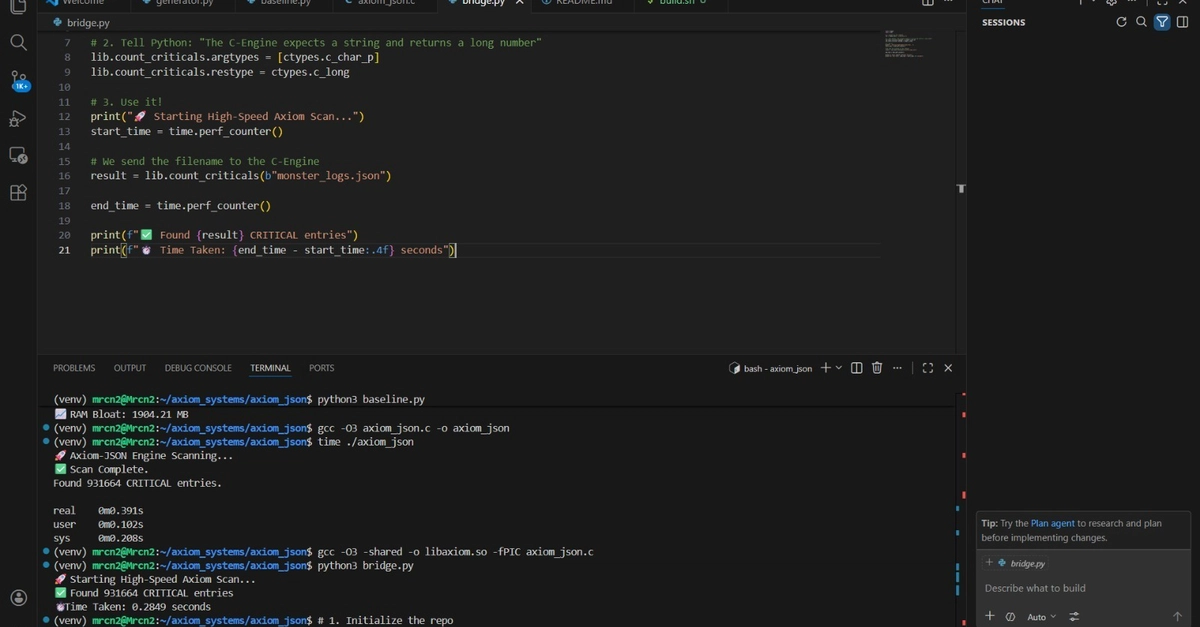
Spot on. That’s not hyperbole; it’s physics. Your Snowflake bill skyrockets, engineers burn out, and stakeholders ghost you.
Why Do Most Petabyte Pipelines Implode?
Monoliths. Everywhere.
One fat pipeline handling ingestion, transform, load. Independent? Ha. One hiccup—say, a network blip—and the whole chain freezes. Cascading doom.
Smart teams ditch that nonsense early. Loosely coupled, event-driven guts. Kafka streams here, Flink jobs there. Scale one without nuking the rest. Obvious? Tell that to the VP who “wants it simple.”
But wait—resilience over perfection. Idempotent ops mean reruns don’t double-count. Checkpointing saves your ass mid-failure. Circuit breakers? They snip the dominoes before they fall.
I saw this at a fintech giant last year. Their pipeline tanked daily from retry storms. Swapped in breakers: uptime jumped 40%. Costs? Slashed.
Hot, warm, cold data. Not everything deserves SSD speed.
Hot paths—real-time dashboards—get the premium. Warm? Frequent analytics on cheaper spins. Cold archives? Glacier it. Boom: costs plummet 70% in one tier alone.
Can You Actually Optimize for Petabyte Scale?
Memory’s the enemy. Can’t slurp petabytes into RAM.
Streaming. Chunked processing. Parallelism—but smart, not dumb-blast. Data locality: process where it sits, skip the shuffle tax.
One unique twist I haven’t seen folks harp on: it’s like the early ’00s web rush. Remember MySpace? Scaled by duct tape till it snapped. Google won with MapReduce—precisely this: distribute, localize, survive. History screams: ignore efficiency, get MySpace’d.
Bad data? Kills millions.
Schema versioning keeps evolutions sane. Stats validation flags outliers pre-load. Anomaly detectors ping Slack at ingestion.
Small scale: chase speed. Petabyte: hunt efficiency. 1% gain? Millions saved yearly. Math doesn’t lie.
Is Your Team Ready for the Petabyte Grind?
Successful crews automate ruthlessly. Measure obsessively—every latency spike, every dollar burned. Design for failure Day Zero.
Engineering choices? Business bets now. Screw up schemas, watch Q4 revenue tank.
Corporate hype calls this “cloud-native magic.” Bull. It’s gritty ops: retries that don’t explode, pipelines that self-heal.
Prediction: by 2026, half the unicorns lose their horn ignoring this. AI data lakes bloat to petabytes overnight—without these shifts, bankruptcy follows.
Dry humor time: if your pipeline’s “resilient,” but lacks idempotency, it’s resilient like a paper house in a hurricane. Cute till the winds blow.
Wander a bit: I’ve grilled engineers at scale shops. Common thread? “We learned post-mortem.” Don’t. Front-load the pain.
And ops? Continuous. Dashboards that scream before users do.
🧬 Related Insights
- Read more: Cloudflare Scans 3.5 Billion Scripts Daily — Now Free, But Is It Foolproof?
- Read more: Tailscale’s Quiet Pivot: Tailnet to Identity-Driven Platform with TSIDP and Aperture
Frequently Asked Questions
What does building data pipelines at petabyte scale really mean?
Handling PB-level ingest, process, store without bankrupting yourself—via event-driven resilience, tiered storage, and failure-proof design.
How do you make data pipelines resilient at scale?
Idempotent jobs, checkpointing, circuit breakers, anomaly detection. Automate, measure, expect crashes.
Why optimize data pipelines for cost over speed at petabyte scale?
Speed’s free at TB; at PB, 1% waste = millions lost. Tier hot/warm/cold, stream smart, localize.