Rain pelted the windows of my Menlo Park office as MiniMax 2.7’s benchmarks lit up my screen—another Chinese AI outfit claiming to rewrite the rules, just two months post-IPO.
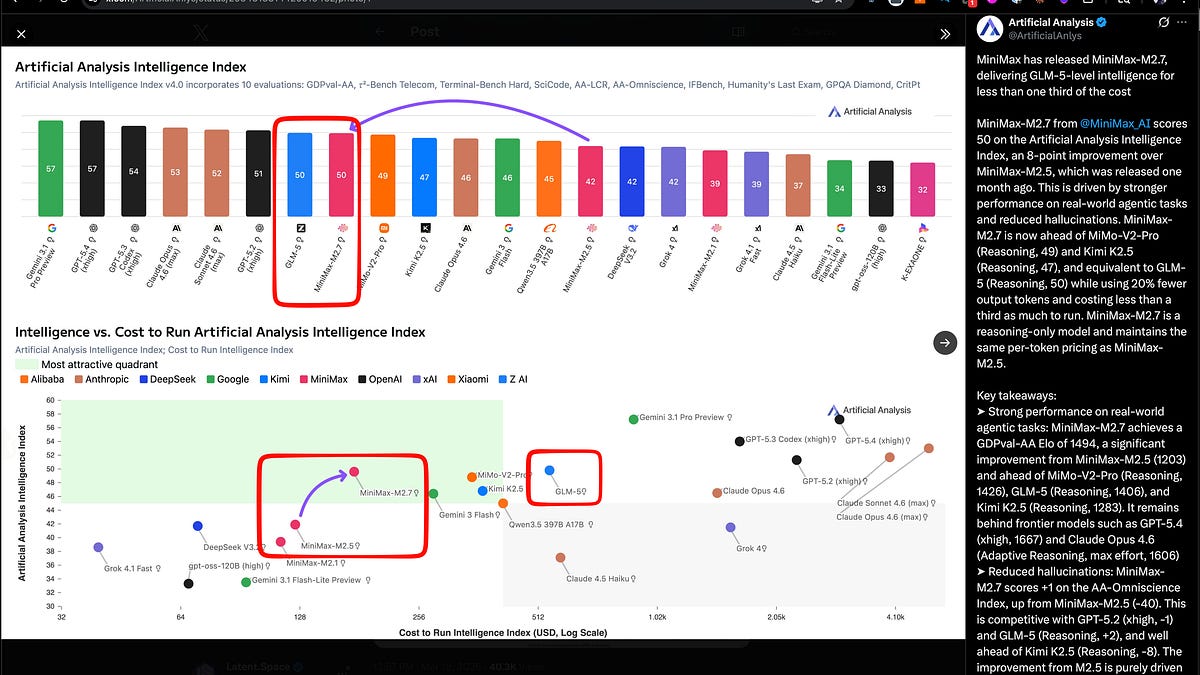
Look, I’ve chased these stories for two decades, from Baidu’s Ernie hype to Alibaba’s Tongyi dreams, and the pattern’s always the same: big numbers, bigger promises, then crickets on adoption. But MiniMax 2.7? It’s landing in the green quadrant of Artificial Analysis’ chart, matching Z.ai’s GLM-5 on intelligence while costing a third as much—$0.30 per million input tokens, $1.20 output. That’s $176 to run their full index, versus GLM-5’s steeper tab. Efficiency isn’t sexy, but it’s the quiet killer in AI wars.
Is MiniMax 2.7 Actually SOTA?
They boast 56.22% on SWE-Pro, 57% on Terminal Bench 2, 97% skill adherence across 40+ skills, parity with Sonnet 4.6 in OpenClaw. Third-parties like Artificial Analysis peg it at 50 on their Intelligence Index, Elo 1494 on GDPval-AA—beating GLM-5’s 1406, Xiaomi’s MiMo-V2-Pro at 1426. Hallucinations down big from 2.5. It’s live on Ollama, OpenRouter, Vercel—you name it.
But here’s my unique angle, one the press releases skip: this reeks of the 2010s mobile chip wars, where Chinese firms like HiSilicon crushed Qualcomm on cost per flop, forcing U.S. giants to offshore or eat losses. MiniMax isn’t just matching; they’re forcing a price war that Western labs can’t sustain forever. Who makes money? Not the hyperscalers burning billions on GPUs.
Skeptical? Damn right. “Early Echoes of Self-Evolution,” they trumpet, with M2.7 “deeply participating in its own evolution,” handling 30-50% of the workflow—like Karpathy’s Autoresearch, but tamer.
“M2.7 is capable of handling 30%-50% of the workflow.”
That’s not autonomy; that’s a fancy intern. Still, recursive feedback loops improving evals, skills, memory? It’s progress. Agent teams, finance tweaks, OpenRoom for entertainment demos—solid, if not earth-shattering.
Xiaomi’s MiMo-V2-Pro sneaks in too, API-only at $1/$3 per million, 1M context, Intelligence Index 49, strong on token efficiency and low hallucinations. Follows their open-weight Flash model. China’s stacking the deck.
Why Does Self-Evolution Hype Feel So Familiar?
Self-evolving agents. Agent harnesses. Skills as folders with scripts, triggers via MCP. Harrison Chase breaks it down: model + runtime + harness, like Claude Code or OpenClaw. LangSmith’s sandboxes, Polly for debugging—it’s all converging.
But let’s cut the buzz. The real shift? From prompting hacks to systems design. Michael Bolin’s interview nails it: tools, repo legibility, feedback loops. DSPy sticks because it’s reliable; cheap subagents like GPT-5.4 mini make delegation viable.
Skills? Progressive disclosure, session distillation, CI-triggers, self-improving ones. RhysSullivan pushes MCP for versioning. Anthropic clarifies: not snippets, full folders.
MCP’s hot—Google something-or-other—but pushback brews. It’s messy, versioning hell without standards.
And Mamba-3? Cartesia’s SSM for inference, but chatter’s all hybrids: plug into Qwen3.5, unlock Muon. Not standalone saviors.
I’ve seen this movie—DeepMind’s AlphaCode promised agent revolutions in 2022, delivered marginal gains. MiniMax claims “deep participation,” but 30-50%? That’s PR spin for “we automated the boring bits.” Bold prediction: by Q4, we’ll see copycats from xAI or Mistral, but costs stay the moat—China’s fabs and scale win there.
Who’s Actually Making Money Here?
MiniMax post-IPO, flashing quarterly wins. Distribution everywhere: Trae, Yupp, kilocode. Xiaomi eyes APIs for IoT dominance. But users? Devs get cheap SOTA; enterprises shave inference bills.
The cynic in me asks: post-Qwen changeover, is this a bright spot or desperation? Chinese models leapfrogging on evals, but U.S. leads deployment—Anthropic’s enterprise lock-in, OpenAI’s moat.
Harness engineering’s the differentiator now. Nickbaumann_ says subagents change delegation math. dbreunig on DSPy persistence. It’s not base models; it’s the plumbing.
Open agent stacks standardize: Nemotron 3 + OpenShell + DeepAgents. LangChain’s observability guide? Production matters.
Short version: impressive specs, efficiency edge. But self-evolution? Overhyped. Watch costs—they’ll force reckonings.
🧬 Related Insights
- Read more: 2026’s Open LLM Avalanche: 10 Architectures That Promise More Than They Deliver
- Read more: Cursor’s $2B ARR Blitz: From Code Editor to Enterprise AI Juggernaut
Frequently Asked Questions
What is MiniMax 2.7?
MiniMax 2.7 is a new open model matching GLM-5 benchmarks at one-third the cost, with claims of partial self-evolution in training workflows.
Does MiniMax 2.7 beat Claude Sonnet?
It ties Sonnet 4.6 on OpenClaw and leads some evals like GDPval-AA Elo, but trails on broader suites—cost is the real win.
Will self-evolving models replace developers?
Not yet—they handle 30-50% of workflows per MiniMax; harnesses and skills evolve the game, but humans design the systems.



