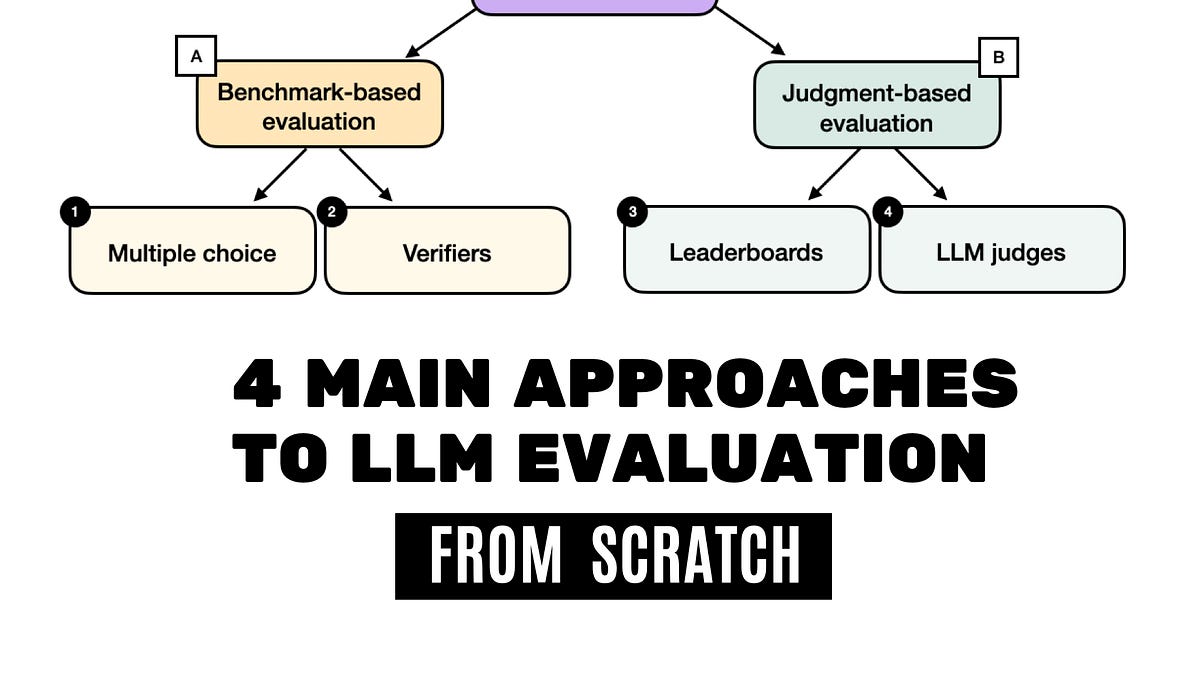
Large Language Models
LLM Evaluation's Dirty Secrets: Four Methods That Promise Smarts But Deliver Hype
Qwen2.5 just topped the leaderboard. Impressive? Or just another round of benchmark bingo? I've seen this game before.