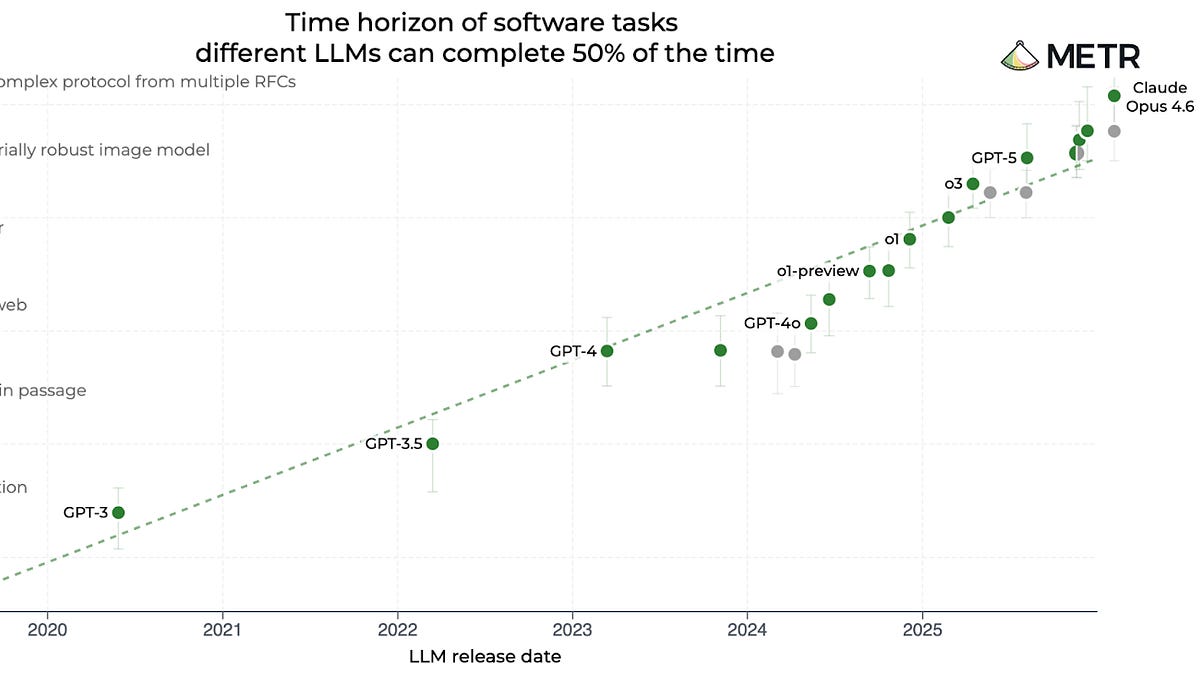
Claude Opus 4.6 just clocked in at 12 hours of human-equivalent coding prowess on METR’s benchmark. That’s double GPT-5’s mark from mere months ago.
Look. This chart—logarithmic, slicing through time like a laser—paints AI progress as an unstoppable freight train, barreling exponentially forward. GPT-3.5? A measly 30 seconds. GPT-4? Four minutes. o1? Forty. GPT-5? Three hours. And now Anthropic’s beast laps it all at 12 hours flat. Straight line on the log scale. Boom—acceleration confirmed, right?
But hover over that gleaming dot for Claude Opus 4.6. Confidence interval: 5 hours to 66. Wild swing. METR’s own David Rein hammered it home on Twitter:
“When we say the measurement is extremely noisy, we really mean it.”
Noisy? That’s putting it mildly. It’s like trying to weigh a black hole with a bathroom scale—the extremes warp everything.
The Chart That’s Got Everyone Hyped
METR, out of Berkeley, built this gem to gauge AI on software engineering tasks, pegged against human time. Simple, verifiable, bite-sized problems. Perfect for bracketing model smarts: easy ones they nail, hard ones they flop. Until now.
Claude Opus solved the suite’s toughest nuts. No upper bound. So the estimate floats, untethered. Better than before? Sure. How much? Shrug. That straight-line progress? Maybe artifact. Or real fire. We’re left guessing while hype cycles spin.
Here’s my take—the unique twist you’re not reading elsewhere. This echoes the 1970s microprocessor rush, when transistor counts soared per Moore’s Law, but real-world apps lagged because benchmarks couldn’t capture architecture shifts. AI’s hitting that wall now: raw task time ignores the messy alchemy of integration, iteration, human handoffs. Prediction? By 2027, we’ll ditch these isolated puzzles for agent arenas—virtual worlds where AIs build companies, negotiate deals, fail spectacularly. True platform shift, measured in simulated GDP, not seconds.
Why Are AI Benchmarks Suddenly So Unreliable?
Blame the ceiling. METR needs unsolved puzzles for calibration. Claude smashed through. Add harder tasks? They’ll catch up fast—models are devouring data like cosmic vacuums.
Deeper issue. These evals? Sterile labs. Real work? Tangled webs. Tasks chain into projects. Goals morph mid-stream. Success? Debatable—boss says gold, team says meh. AI’s inching into weeks-long hauls, months even. How do you score that? We can’t reliably rate humans on it either—performance reviews are jokes half the time.
Divergence looms. Measurable gains plateau on charts; uncharted capabilities explode in wilds we crave. It’s exhilarating. Terrifying. Like watching a toddler with a jetpack—raw power, zero control metrics.
How Benchmarks Die (A Familiar Cycle)
Remember MMLU? 2020 darling, grilling models on everything from astronomy to law. GPT-3: 43.9%. Random guess: 25%. Progress!
Fast-forward—no, scratch that, by 2023, GPT-4 hit 86.4%. GPT-4o: 88.7%. GPT-4.1: 90.2%. Companies ghosted it last year. Saturated. Useless signal.
Classic lifecycle. New benchmark dazzles, separates wheat from chaff. Models train on it (or leaks). Scores converge. Dead. METR’s teetering. o1, GPT-5, Claude—climbing fast, but noise creeps in as peaks flatten.
And corporate spin? Anthropic touts Opus as leapfrogger. Fair—it’s crushing. But that PR glosses the fuzziness. Skepticism check: don’t swallow whole. Charts seduce; reality squirms.
So what’s next? METR iterates, sure. But philosophy shift needed. From puzzles to ecosystems. Think AI orchestras—agents collaborating, querying tools, adapting to chaos. Benchmarks? Live fire exercises in digital sandboxes.
Picture it: fleets of AIs launching startups in sims. One codes the app. Another markets. Third handles bugs from fake users. Measure revenue. Churn. Survival rate. That’s the futurity—AI as platform, not parlor trick.
We’re not losing progress signals. We’re outgrowing kindergarten tests. Exponential? Still. But metrics must evolve, or we’ll blind ourselves to the rocket launch.
Thrilling times. AI’s rewriting work itself. Hold tight.
What Does This Mean for AI’s Real Acceleration?
Apparent speed-up—Claude doubling GPT-5 in months—fuels investor frenzy, talent wars. But noisy? It mutes the signal. Is scaling laws bending, or just eval limits?
My bold call: real. Under noise, trend holds. Reasoning models like o1 previewed it—chain-of-thought unlocking depths. Opus scales that. Expect Claude 5 to bracket at days, not hours. Then? Multi-agent swarms.
Challenge for labs: dynamic benchmarks. Procedural tasks, regenerating post-saturation. Human-AI teams as gold standard. Messy, yes. Essential.
🧬 Related Insights
- Read more: What If You Could Talk an AI Out of Its Deepest Convictions?
- Read more: FrostArmada’s Fall: How Cops Crushed Russia’s Router Spy Network Targeting Microsoft Logins
Frequently Asked Questions
Why is it getting harder to measure AI performance?
Models like Claude Opus 4.6 solve entire test suites, leaving no hard upper bounds for calibration—confidence intervals explode from hours to days.
What is the METR chart in AI?
METR’s logarithmic plot tracks AI coding task complexity vs. human time, from GPT-3.5’s 30 seconds to Opus’s 12 hours, signaling (noisy) exponential gains.
Will AI benchmarks keep up with progress?
Not static ones—they saturate fast. Expect shift to agent sims and real-world proxies for weeks-long tasks.