DeepSeek R1 spits out step-by-step logic on puzzles that’d stump your average GPT. Boom — there it is, cracking math proofs like a grad student on deadline.
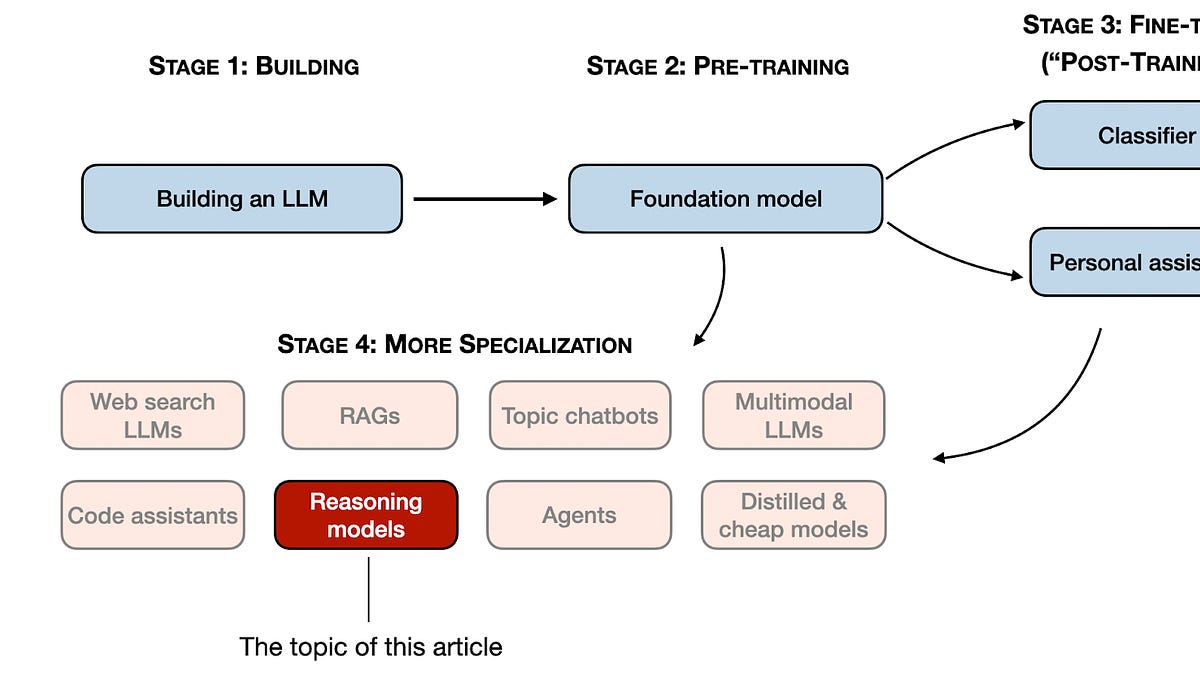
Zoom out. We’re knee-deep in 2024’s LLM frenzy, where raw scale isn’t enough anymore. Specialization rules: code wizards, RAG masters, now reasoning LLMs elbowing in. These aren’t your chatty generalists. They’re tuned for multi-step brainteasers — think riddles, theorems, code marathons. And DeepSeek’s blueprint? It’s the map everyone’s stealing.
But here’s the rub. Defining “reasoning” is a mess. Everyone’s got a take.
In this article, I define “reasoning” as the process of answering questions that require complex, multi-step generation with intermediate steps.
Spot on — skip trivia like France’s capital. We’re talking train speeds multiplying hours for distance. Modern LLMs handle basics, sure. Reasoning LLMs? They crush olympiad-level stuff, often flashing their “thoughts” en route.
Why Chase Reasoning LLMs When Base Models Work Fine?
Simple tasks? Stick to vanilla LLMs — cheaper, snappier. Summaries, translations: no overkill needed. Reasoning shines on thorns like advanced math or debugging spaghetti code.
Yet drawbacks lurk. They’re pricier (more tokens), wordier, and yeah, they overthink into blunders. Use the right hammer, folks.
DeepSeek didn’t birth one model. Three flavors: R1-Zero (raw RL from scratch — risky), R1 (polished with supervision), R1-Distill (lite version for mortals). Their pipeline? Pretrain behemoth V3, then layer on reasoning smarts.
First pass: cold-start RL on math/code datasets. No human labels — pure trial-error. Results? Uneven, but gritty.
Then supervised fine-tune (SFT) on clean chains-of-thought. Humans (or synthetic data) provide gold-standard steps.
Reinforcement learning kicks in — reward models score trajectories. PPO or whatever flavor hones the edge.
Distill shrinks it for inference speed. Clever.
That’s the hook. Now, the meat: four battle-tested paths to forge these thinkers.
Path 1: Stuff ‘Em with Supervised Data
Easiest entry. Curate datasets of problems-plus-solutions. Think GSM8K math, LiveCodeBench.
SFT an LLM on these chains. It learns to mimic step-by-step. Boom — instant reasoner.
But garbage in, garbage out. Data quality’s king. Synthetic chains from stronger models help, yet hallucinations creep.
DeepSeek leaned here post-RL. Smart layering.
Short para: Works fast. Scales poorly without curation.
How Does Reinforcement Learning Turbocharge Reasoning?
RL’s the secret sauce — and DeepSeek R1-Zero’s wild card.
Train a reward model on human-ranked trajectories. Then RLHF (or DPO, cheaper cousin) pushes the policy to maximize rewards.
Why? SFT plateaus; RL explores wilder paths, self-improves.
Catch: Instability. R1-Zero bombed on some benchmarks initially — reward hacking galore. Needed SFT rescue.
My take? Echoes 80s expert systems: rule-chaining for narrow brilliance. Back then, brittle. Now? Compute floods fix it — but expect task silos. No unified AGI here; just puzzle-crushers.
Path 3: Test-Time Compute — o1’s Sneaky Trick
No training tweaks. Just inference hacks.
OpenAI’s o1 hides internal chains, runs search-like trees. Beam search on steroids: explore branches, prune duds.
Verifiers score mids — math checkers, code executors. Pick winners.
Pros: Zero params changed. Bolt-on any LLM.
Cons: Latency explodes. o1’s slow; scale that, costs soar.
DeepSeek flirts here too, but training-first rules their roost.
And yeah — corporate spin alert. OpenAI hypes “reasoning from first principles.” Nah, it’s glorified search with LLM oracles.
Path 4: Retrieval and Tooling Hybrids
Not pure LLM. RAG for facts, but amp with reasoning.
Agent loops: think, act (call calculator/API), observe, repeat.
Tools ground hallucinations. Math? Wolfram. Code? Run it live.
Why underrated? Handles open-ended real-world. Pure reasoning LLMs choke sans tools.
Combine: Train on tool-augmented traces. Best of both.
DeepSeek’s Wake-Up Call — And Budget Hacks
Post-R1/V3, landscape shifts. Open-source catches premium — DeepSeek’s cheap base crushes GPT-4o on some boards.
Prediction: 2025 fragments LLMs into zoos. Reasoning for STEM, creative for prose. Pick-n-mix APIs.
Tight budget? Start small.
Hack 1: Synthetic data via stronger OSS like Llama3.1 — self-play chains.
Hack 2: DPO over PPO — no RL headaches.
Hack 3: Distill early. 7B reasoner from 70B teacher.
Hack 4: Focus narrow — math only, not all.
Don’t chase rainbows. Measure on held-out evals: AIME, GPQA.
Skeptical? Good. Hype screams “AGI soon.” Reality: incremental. Reasoning LLMs excel niches, falter elsewhere. Tradeoffs rule.
But damn — when they click, it’s magic. Train leaves station; model nails distance in seconds flat.
🧬 Related Insights
- Read more: AWS Frontier Agents: Autonomous Saviors or Expensive Hype?
- Read more: LLM Evaluation’s Dirty Secrets: Four Methods That Promise Smarts But Deliver Hype
Frequently Asked Questions
What are reasoning LLMs good for?
Complex multi-step problems like math olympiads, coding contests, logic puzzles — not chit-chat.
How to build a reasoning LLM on a budget?
Use synthetic data from OSS giants, DPO for RL, distill to smaller sizes, and eval ruthlessly on benchmarks.
Will reasoning models replace general LLMs?
Nope — they’ll specialize alongside them. Right tool per task.


