Folks grinding through math homework or debugging code late at night — that’s who cares about the state of LLMs 2025. Not the VCs high-fiving over billion-parameter behemoths, but you, wondering if these ‘reasoning’ models will actually save time or just spit fancier errors.
And here’s the kicker: they got cheaper. Way cheaper.
DeepSeek’s R1: The Budget Reasoning Revolution?
DeepSeek dropped their R1 paper in January 2025, and suddenly everyone’s rethinking the math on AI costs. No more $500 million fairy tales for top-tier models. Their estimate? Closer to $5 million, with post-training on R1 itself clocking in at a laughable $294,000 in compute credits.
But — and it’s a big but — that’s just the GPUs humming, not the army of PhDs tweaking hyperparameters or the office leases in San Francisco. Still, it lit a fire. Open-weight models matching proprietary giants like ChatGPT? Investors perked up. Journalists (guilty) rewrote their ‘AI is unaffordable’ scripts.
The DeepSeek R1 supplementary materials estimate that training the DeepSeek R1 model on top of DeepSeek V3 costs another $294,000, which is again much lower than everyone believed.
That’s the quote that broke the internet — or at least the AI Twitter bubble.
Look, I’ve covered enough hype cycles to smell the spin. Remember 2012’s deep learning revival? Everyone screamed ‘end of摩尔定律,’ but costs plummeted anyway. DeepSeek R1 feels like that: a commoditization wake-up call. My unique bet? By 2027, indie devs will train custom reasoners on AWS spot instances for beer money, gutting the moat around OpenAI’s moat.
Short para for punch: Open-source just ate Big AI’s lunch.
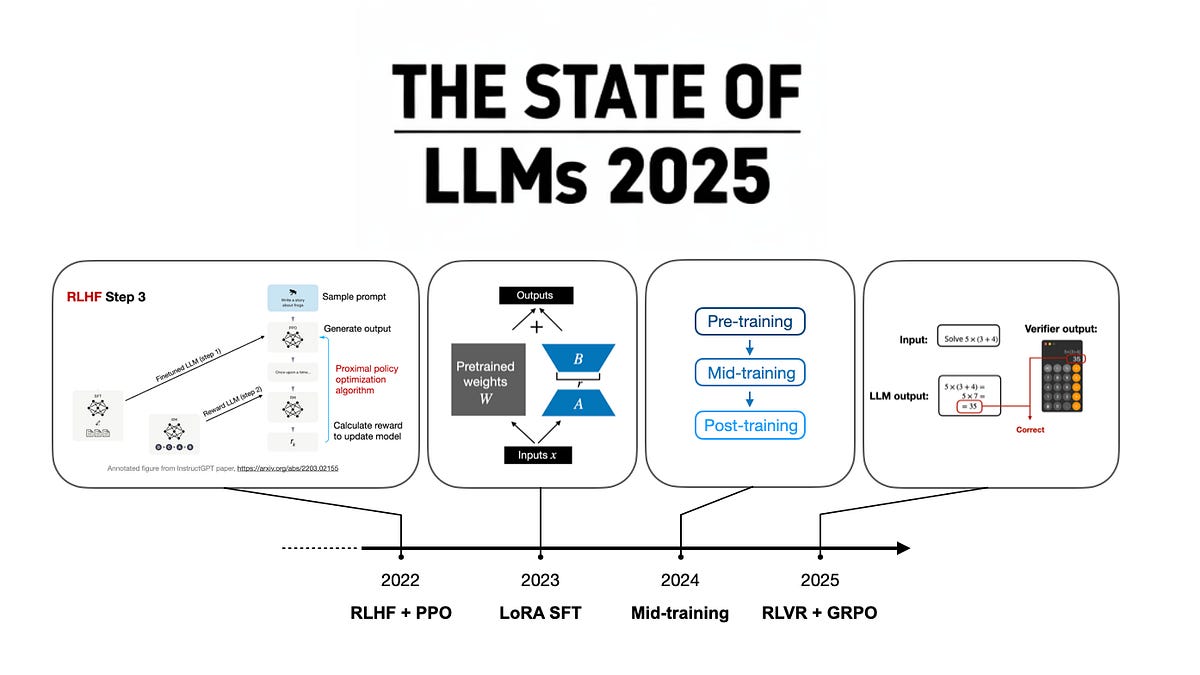
Now, the tech meat — RLVR and GRPO. Reinforcement Learning with Verifiable Rewards. Fancy talk for ‘use math problems where right answers are black-and-white, no squishy human prefs needed.’ Ditch pricey RLHF labels; auto-grade code and equations. GRPO’s the optimizer making it sing.
Everyone piled on. OpenAI, Anthropic, xAI — all shipped ‘thinking’ variants. 2025’s focus point: RLVR + GRPO, after 2024’s mid-training data hacks.
It’s progress. Models now chain thoughts, explain steps, crush benchmarks. But real people? That student still googles syntax errors because LLMs hallucinate on edge cases. Who’s making bank? Nvidia. Cloud giants. Not you.
Will RLVR Kill the AI Cost Explosion?
Costs dropping an order of magnitude — sounds bullish. DeepSeek V3 from late ‘24 already hinted at it, but R1 sealed the deal. Pre-training foundation stays king, sure. But post-training? Scale compute there now, unlock capabilities without begging Sam Altman for access.
Verifiable rewards expand beyond math/code — imagine physics sims or legal docs with clear ‘correct’ flags. Labs are trying. Yet caveats stack up. Synthetic data chicken-egg? Still there. Researcher salaries? Ignored in those rosy estimates.
Cynical me asks: why’d it take a Chinese open-source outfit to burst the bubble? US labs too busy with NDAs and NDAs-within-NDAs?
And scaling? Still works, but o1’s reasoning traces were the only pre-R1 vibe shift. Rest felt same-old, just bigger.
The Hype Trap: Reasoning Ain’t General Intelligence
Every year, a new king: 2022’s RLHF+PPO birthed ChatGPT. ‘23 LoRA for cheap fine-tunes. ‘24 mid-training data wizardry. ‘25? RLVR everywhere.
But problems linger. Hallucinations. Context limits (despite long-context claims). Energy guzzlers frying the planet — who’s paying that carbon bill?
Real insight: this mirrors the PC revolution. IBM thought mainframes forever; micros democratized compute. LLMs now? Open reasoning models turn AI into utilities, not luxuries. Prediction: 2026 sees ‘reasoning-as-a-service’ from Hugging Face, undercutting APIs by 80%. Big players pivot to enterprise lock-in.
Skeptical pause. Benchmarks soar, but deploy one in production — boom, it fails on your proprietary data. PR spin calls it ‘emergent’; I call it unreliable.
For creators, though? Game-changer. Code with explanations. Tutors that show work. If you’re not all-in on closed-source, that is.
Open Problems That Won’t Die
State of LLMs 2025 ain’t all roses. Multimodality? Meh progress. True agency? Vaporware. Safety? RLVR helps verifiables, but jailbreaks evolve faster.
Money question: who profits? Not users. Compute providers, yes. Model hosts, sure. But that $5M train? Still locks out garages without VC.
One para wander: I’ve seen Valley promises since Web 1.0 — remember blockchain curing world hunger? Reasoning LLMs promise thinking machines. Deliver explanations, sure. But souls? Nah.
What Scares Me About 2026 Predictions
Next year? More RLVR scale, hybrid pre/post-training. Open models close gap — DeepSeek 2.0 anyone? But watch regulation creep; EU already sniffing.
Bold call: reasoning commoditizes, sparks AI app explosion like iPhone SDK did. Real people win — apps for everything, dirt cheap.
But cynical core: without profit rethink, it’s hype treadmill.
**
🧬 Related Insights
- Read more: Simulating Stubborn Users: The Secret to Unbreakable Multi-Turn AI Agents
- Read more: TGS Crushes Seismic AI Training: 6 Months to 5 Days on AWS HyperPod
Frequently Asked Questions**
What is RLVR in LLMs?
RLVR — Reinforcement Learning with Verifiable Rewards — lets models learn from auto-checked tasks like math or code, slashing need for human labels.
Will reasoning LLMs replace programmers in 2025?
Nah, they assist — explain bugs, suggest fixes — but can’t grok your messy codebase or business logic yet.
How much does it cost to train an LLM like DeepSeek R1?
Around $5M total per their estimates, with post-training at $300k compute — but add salaries, it’s more like startup budget, not garage project.