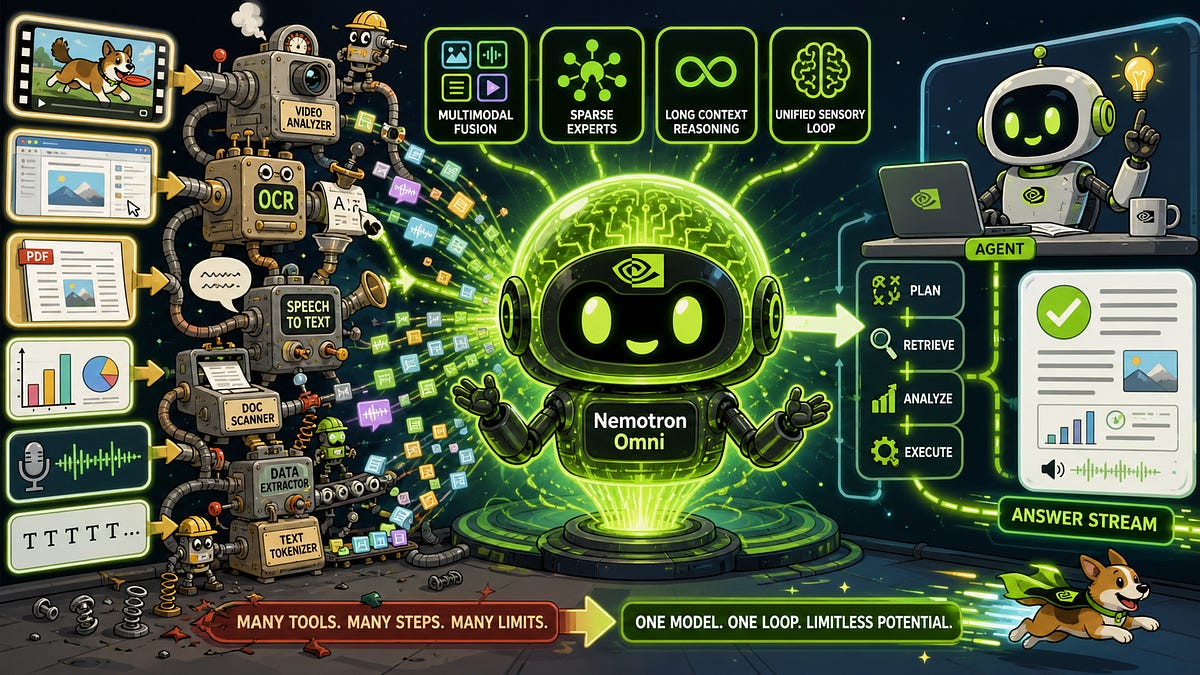
Everyone expected NVIDIA to keep pushing the boundaries of AI hardware, and they have. But the real story brewing from the Nemotron family, specifically the Nemotron 3 Nano Omni, isn’t just about raw power; it’s about architectural simplification. For months, the AI development community has grappled with stitching together disparate models—one for speech, another for vision, a third for text—creating a fragile, inefficient pipeline where information gets lost at every handoff. Nemotron Omni’s grander ambition is to make that zoo of single-purpose models behave like a unified organism.
This new open omni-modal reasoning model, announced April 28, 2026, is NVIDIA’s direct assault on the current multimodal agent stack’s inherent fragmentation. The typical agent today operates through a series of interpretive leaps. Audio data gets fed into an Automatic Speech Recognition (ASR) model, visual data into a Vision-Language Model (VLM), and documents are either OCR’d or rendered as images. The agent’s central language model then attempts to synthesize these fragmented outputs into a coherent understanding. This process is rife with issues: an ASR model might accurately transcribe speech but miss the visual context on screen at that exact moment; a VLM might identify an object but lack the auditory cues that accompanied its appearance. The result? A planner that receives a jumbled mess of summaries instead of a fluid, integrated sensory stream.
Nemotron Omni, conversely, is engineered to act as the integrated “eyes and ears” of an AI agent. Its design prioritizes a single, efficient perception-and-reasoning model. Think video, audio, image, and text going in, with a unified text output that represents a holistic understanding. This is crucial for agentic workflows that require nuanced interaction with complex environments, whether that’s navigating a graphical user interface, performing deep document analysis, or comprehending lengthy audio-visual content.
A Unified Perception Layer: The Core Innovation
What’s truly compelling here is the strategic shift NVIDIA is advocating. Instead of building ever-more sophisticated individual modal models and then trying to force them to interoperate, Nemotron Omni suggests consolidating the perception and initial reasoning layers. This is not just a technical tweak; it’s a philosophical alignment that acknowledges the inherent interdependence of sensory inputs in real-world intelligence. Imagine an agent that doesn’t just “see” a button but understands why it’s being asked to click it, drawing context from spoken instructions and accompanying visual cues simultaneously.
NVIDIA positions Nemotron Omni as an open model, a key indicator of their strategy to foster an ecosystem around this unified approach. By making the core architecture accessible, they are likely aiming to accelerate adoption and, critically, gather feedback that will refine the model further. This open-source play is less about altruism and more about establishing a de facto standard for how multimodal agents should be built, much like they did with CUDA for GPU computing.
The Market Implications: Beyond the Hype
So, does Nemotron Omni actually live up to its ambitious promise? The initial announcement suggests a significant step forward. By centralizing multimodal understanding, NVIDIA could dramatically reduce latency and computational overhead for AI agents. This is not merely an academic exercise; for businesses looking to deploy sophisticated AI agents for tasks like customer service, data analysis, or even creative assistance, efficiency and accuracy are paramount. A single, powerful model that handles multiple modalities with less error is a direct path to lower operational costs and improved user experience.
However, the devil, as always, is in the execution and real-world performance. While the architecture is sound, the actual effectiveness of Nemotron Omni will depend on its ability to generalize across a wide array of complex scenarios and its resilience to noisy or ambiguous inputs. NVIDIA’s track record in hardware is undeniable, but the nuance of multimodal reasoning is a battlefield where many have stumbled. The true test will be how well this unified model performs compared to meticulously engineered, albeit fragmented, agentic systems already in the market.
This move also puts pressure on other AI labs and hardware providers. If Nemotron Omni proves to be a reliable and efficient platform, it could dictate the future architecture of AI agents, forcing competitors to either adapt or risk being left behind with legacy, siloed approaches. It’s a bold play for market leadership, not just in silicon, but in the foundational software stack that will power the next generation of intelligent agents.
Can Nemotron Omni Truly Deliver on its ‘Omni-Modal’ Promise?
Early indications are strong. NVIDIA’s commitment to this unified approach suggests a deep understanding of the limitations inherent in current agent designs. The claim is that Nemotron Omni can process video, audio, images, and text simultaneously, synthesizing them into a single, coherent textual output. This integrated perception could be a significant leap over systems that rely on sequential processing and separate model outputs. For complex tasks like understanding user intent from a video call that includes spoken dialogue and on-screen action, a truly omni-modal model is the holy grail.
The Nemotron 3 Nano Omni is designed to make that zoo feel like a single animal. Today’s multimodal agent stack often looks like a Rube Goldberg machine: audio goes to an ASR model, screenshots go to a VLM, PDFs are rendered into images or OCR’d into text, video gets sampled into frames, and then a language model tries to stitch the outputs together. Every boundary between models is a lossy compression step.
This quote perfectly encapsulates the problem NVIDIA is trying to solve. The “lossy compression” at each model boundary is precisely where intelligence gets diluted and errors compound. By aiming for a single, integrated model, Nemotron Omni seeks to maintain a richer, more contiguous understanding of the data. This could have profound implications for AI agents operating in dynamic, multi-sensory environments, from robotics to advanced desktop assistants.
The Future of Agentic AI: One Brain, Many Senses
NVIDIA’s strategy with Nemotron Omni echoes historical shifts in computing. Just as the CPU consolidated many discrete computational tasks, and the GPU unified parallel processing, this model aims to unify multimodal perception. It’s a top-down approach, using NVIDIA’s considerable AI research and development firepower to define a new paradigm. Whether developers embrace this unified approach or continue to cobble together best-of-breed components remains to be seen, but the potential for simplification and enhanced performance is undeniable. If Nemotron Omni fulfills its promise, the era of the fragmented AI agent may soon be over, replaced by more cohesive, intelligent, and smoothly interacting systems.
What’s fascinating is how this intersects with NVIDIA’s hardware strategy. A unified multimodal model like Nemotron Omni is likely optimized to run on NVIDIA’s specialized AI accelerators, creating a synergistic ecosystem. This isn’t just about software; it’s about creating a tightly integrated stack where hardware and software are co-designed for peak performance. This could further entrench NVIDIA’s dominance in the AI landscape.