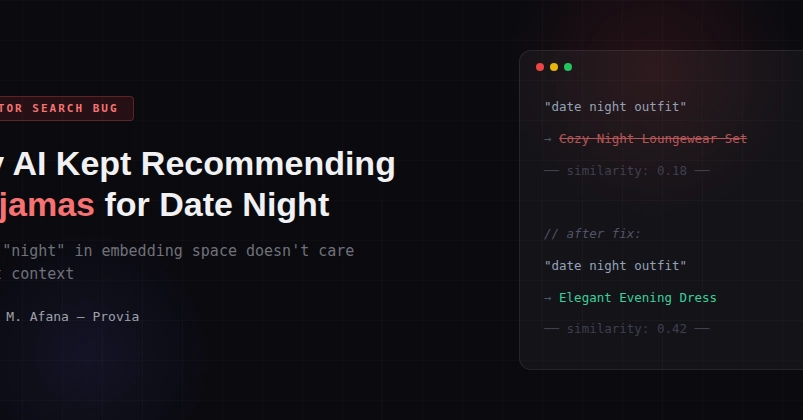
You’re staring at a blank screen, typing “fluffy kitten sleeping.” Boom—the AI spits back perfect matches from a million docs. No keywords hunted. No regex nightmares. Just… magic?
Zoom out. That’s embedding models at work, the unsung heroes plotting language on a multidimensional map. Like GPS for thoughts, they crunch words into vectors—those endless number lists—that capture vibe, context, essence. And here’s the kicker: this isn’t some lab toy. It’s the backbone of search, RAG, every smart recommendation you’ve ever clicked.
Think of the universe’s biggest library. Not sorted by Dewey decimals, but by feel—moody poetry huddled in one nebula, tech manuals orbiting nearby, quantum rants flung to the galaxy’s edge. Embedding models build that cosmos from billions of sentences, noting how “cat” and “kitten” dance together, while “cat” and “refrigerator” repel like oil and water.
Ever Wondered Why AI ‘Gets’ Your Vibe?
Coordinates. Pure, mathematical sorcery. Train the model on internet-scale text. It spots patterns: synonyms cluster, antonyms drift apart, relatives form constellations. “Dog”? Near “puppy,” a stone’s throw from “wolf,” light-years from “spaceship.”
Give it a sentence—“The fluffy kitten is sleeping.”—and it doesn’t parse letters. Nope. Grabs each word’s vector, averages them into a single fingerprint. Pins it on the map. Scans for neighbors. Those close ones? Your matches. Even if they swap “kitten” for “fuzzy feline.”
At its heart, an embedding model is a neural network trained to map like words or sentences into a continuous vector space, with the goal of approximating mathematically those objects that are contextually or conceptually similar.
That’s the original spark—straight from the blueprint. But let’s crank it up.
And my hot take? This mirrors the periodic table’s birth. Mendeleev didn’t just list elements; he mapped their hidden geometries, predicting undiscovered ones. Embeddings do the same for meaning—foretelling nuances we haven’t named. Bold prediction: in five years, they’ll spawn ‘meaning engines,’ querying not words, but emotions, intents, buried truths.
Short para punch: Vectors aren’t static. BERT’s attention mechanism shifts them based on neighbors—like a word’s mood swings in context.
How Do Embedding Models Work Step by Step?
Input hits. Tokenizer chops text into tokens—word bits with punch. “Embedding” might split into “em” + “bedding,” each getting IDs.
Chunk it—512 tokens max, or the model chokes.
Embed: Transformer magic spits vectors, say 768 floats long. Dense as a black hole.
Query time? Vectorize your ask. Compute cosine similarity (angle between arrows, not distance—genius). Top neighbors win.
RAG kicks in: Feed winners to an LLM. It weaves answers grounded in reality, no hallucinations.
But wait—coding it. Fire up Python, snag BERT. Here’s the raw thrill:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
text = "Embedding models are so cool!"
tokens = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
Tokens emerge: IDs like [101, 7861…]. That [CLS]? Sentence soul, pooling the whole vibe for LLMs.
Play with it—swap texts, watch vectors morph. It’s alive.
Why Does This Matter for Developers Right Now?
Forget brittle keyword search. Embeddings scale to petabytes, fuzzy-match across languages, evolve with fine-tuning.
Corporate hype alert: OpenAI’s text-embedding-3-large brags ‘state-of-the-art.’ Sure, but it’s yesterday’s news if you’re tweaking open-source like Sentence Transformers. Don’t drink the API Kool-Aid—roll your own for control.
Historical parallel: Like maps replacing flat Earth myths, embeddings shatter linear text. We’re in a platform shift—AI as coordinate navigator for knowledge oceans.
Energy surging? Imagine drug discovery: Plot molecules as vectors, find kin never synthesized. Or law: Cluster case law by ‘justice vibe.’ Wonderment.
One-word para: Transformative.
Pitfalls, though. Dimensional curse—curse of dimensionality, vectors sprawl, distances lie. Fix with PCA or clever indexing like FAISS.
Chunking wars: Too big, lose context; too small, fragment meaning. Goldilocks it.
And bias? Train data’s poison seeps in—“doctor” vectors male-skewed unless debiased.
Yet the pace! Models shrink—mobile embeddings incoming. Edge AI, plotting your fridge notes locally.
The Map’s Dark Corners
Not perfect. Antonyms sometimes cluster (hot-cold extremes, but related). Rare events? Vectors ignore tails.
But iterate. New kings like ColBERT mix late interactions for precision. Future: Multimodal maps, folding images, audio into the same space.
Enthralled yet? This is AI’s hippocampus—memory’s geometry.
🧬 Related Insights
- Read more: 2024’s AI Papers: Llama 3 Hype Train Derails into Iteration Hell
- Read more: Dinosaur Eats: Chrome Extension Turns Webpages into Prehistoric Snacks
Frequently Asked Questions
What are embedding models used for?
They’re the search engine under RAG, recommendations, semantic similarity—powering ChatGPT’s smarts without melting servers.
How do I get started with BERT embeddings?
Install transformers, tokenize text, grab [CLS] pool—code above. Scale with Hugging Face hubs.
Will embedding models replace traditional search?
They’re augmenting it now, but yeah—give ‘em time, keyword era ends.