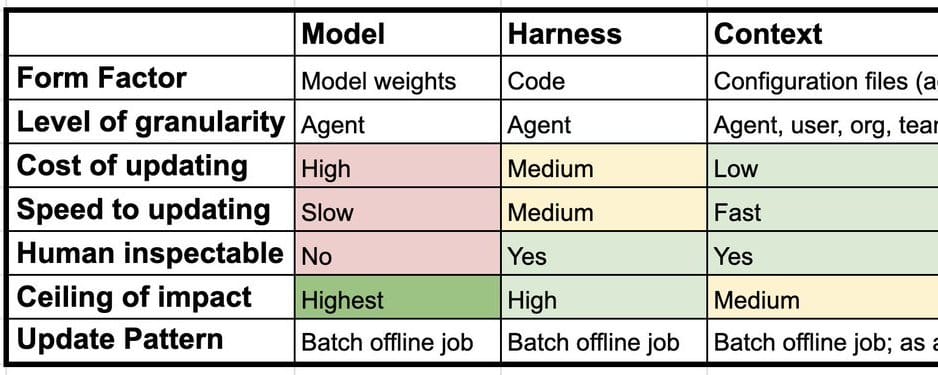
Hard tasks in AppWorld? Baseline success: 19.1%. With ALTK-Evolve: 33.3%. A 14.2% leap that sounds impressive — until you clock the pathetic starting line.
Look, AI agents are like that intern who nails the script but panics when the coffee machine jams. They re-read yesterday’s chat logs, sure. But principles? Forget it. ALTK-Evolve wants to change that, distilling raw trajectories — user chats, tool calls, screw-ups — into snappy guidelines. No more bloating prompts with endless transcripts.
Why Your AI Agent Is Still a Moron
Most agents treat experience like a bad Tinder date: swipe left, repeat. They don’t learn ‘hey, this API flakes on weekends’ or ‘users hate verbose errors.’ Instead, they parrot history. Pathetic.
ALTK-Evolve flips the script. Downward flow grabs traces via tools like Langfuse. Extractors sniff out patterns — boom, candidate rules. Upward? Background jobs merge dupes, score winners, prune junk. Retrieval? Just-in-time, relevant only. Lean. Mean. Supposedly.
Reliable agents should distill principles from experience and apply them to new tasks, not just near duplicates of old ones.
That’s from the original pitch. Spot on — in theory. But theory’s cheap.
And that MIT stat? 95% of pilots fail because agents don’t adapt. Oof. ALTK-Evolve targets this with episodic memory, evolving a library of SOPs and policies. Agents reason better over time. Or so they claim.
Does ALTK-Evolve Actually Generalize — Or Just Memoize Better?
Benchmarks on AppWorld: multi-step API romps, 9.5 calls across 1.8 apps. Hard ones? Twisted control flows. Baseline ReAct agent gets task plus top-5 guidelines from prior runs. Tested unseen.
Easy: 79% to 84.2%. Meh.
Medium: 56.2% to 62.5%. Yawn.
Hard: 19.1% to 33.3%. Now we’re talking — 74% relative gain.
Aggregate: 50% to 58.9%. Scenario Goal Completion jumps, meaning less flakiness across variants. Guidelines teach judgment, they say. Noise controlled. Progressive disclosure avoids context stuffing.
But here’s my unique beef — and it’s one the paper glosses over: this reeks of 1980s expert systems. Remember those? Hand-crafted rules that worked in labs, crumbled in the wild. ALTK-Evolve automates rule-mining with LLMs, sure. Bold prediction: it’ll scale until guidelines ossify into dogma. Agents reject fresh data because ‘the library says so.’ We’ve traded brittle prompts for brittle principles. Progress? Or same trap, shinier packaging?
Corporate hype calls it a ‘memory system that evolves.’ Please. It’s a fancier RAG for agent fails. Still, that hard-task lift? Real. Generalization to unseen tasks? Evident. Consistency? Improved. Paper’s here: https://arxiv.org/abs/2603.10600.
Plug-and-Play — Or Plug-and-Pray?
Integration? Claude Code plugin: one command. Extracts to files, hooks retrieval. Lite mode for noobs — watch the video demo. Limits? No cross-session smarts, no garbage collection.
Pro versions for Codex, IBM. Low-code walkthroughs abound. Easy entry. But scaling? Background jobs need infra. What if your agent’s a firehose of traces? Junk drawer awaits.
Skeptical take: benchmarks are toy worlds. AppWorld’s cute — APIs, tasks. Real agents? Customer support hellscapes, adversarial users, shifting APIs. Will guidelines hold? Or mutate into hallucinated nonsense?
It’s better than stuffing logs, I’ll grant. Teaches transfer: vinaigrette principles for duck. But don’t drink the Kool-Aid. Agents need principles, yeah — but LLMs distill them reliably? That’s the rub.
And the PR spin? ‘Turns raw trajectories into reusable guidelines.’ Sounds magical. Reality: extractors are pluggable, but who tunes ‘em? You. More dev work.
The Real Test: Beyond Benchmarks
Complexity scales with need — harder tasks love guidelines most. Flakiness drops. Good signs.
Yet, no free lunch. Storage balloons. Scoring heuristics? Black magic. Retrieval relevance? LLM-dependent roulette.
My verdict: incremental win. Not the agent messiah. But in a sea of re-readers, a distiller stands out. Try Lite. See if your bot stops repeating dumb mistakes.
🧬 Related Insights
- Read more: Claude Hits iOS #1: Anthropic’s Bold Stand Shakes Pentagon AI Dreams
- Read more: Australia’s AI Environmental Approvals Gambit: Robodebt Redux or Biodiversity Savior?
Frequently Asked Questions
What is ALTK-Evolve?
It’s a memory loop for AI agents: captures traces, extracts guidelines, refines library, retrieves smartly. Boosts on-the-job learning without prompt bloat.
Does ALTK-Evolve work on hard tasks?
Yes — 14.2% absolute gain (74% relative) on AppWorld hards. Generalizes to unseen scenarios, cuts flakiness.
How to install ALTK-Evolve in Claude?
claude plugin marketplace add AgentToolkit/altk-evolve or similar. Lite mode stores files, auto-retrieves. Pro for full power.