Why do AI agents keep screwing up on Day 2, even after acing the demo?
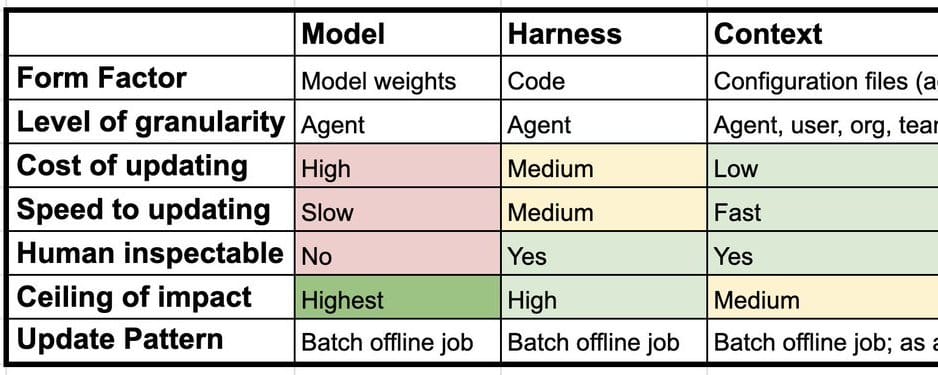
Continual learning for AI agents isn’t the weight-tweaking trick most folks obsess over. It’s a three-layered beast: model, harness, context. Nail this architecture, and your agent doesn’t just survive—it thrives, adapting without the dreaded catastrophic forgetting. Ignore it? You’re building yesterday’s tech.
Look, we’ve seen this before. Back in the ’90s, software giants like Microsoft treated OS updates as nuclear events—reboot everything, pray. Then Linux showed up, modular as hell, letting devs patch kernels live. AI agents are pulling the same pivot. Continual learning spreads the load across layers, mimicking that shift from monoliths to ecosystems.
What Makes the Model Layer So Tricky?
Model layer? That’s the LLM core—Claude Sonnet, whatever beast you’re running. Updating weights here means SFT, RLHF, or fancy GRPO. But here’s the killer: catastrophic forgetting. Train on new code tasks, and poof—your agent’s poetry skills evaporate.
It’s an open wound in research. Big labs like OpenAI train Codex-style models for whole agents, not per-user. Granular LoRAs? Theory’s hot; practice lags. Why? Compute costs skyrocket, and deployment’s a nightmare.
A central challenge here is catastrophic forgetting — when a model is updated on new data or tasks, it tends to degrade on things it previously knew. This is an open research problem.
Short para: Brutal truth.
And yet, we’re not there yet. My bet? Model updates stay rare, agent-wide events. Too brittle for daily grind.
But wait—don’t stop here. That’s amateur hour.
Why Ignore the Harness—And Regret It?
Harnesses. The unsung glue: code loops, fixed prompts, tools always-on. Think Claude Code’s scaffolding or OpenClaw’s Pi setup. Continual learning here? Fresh papers like Meta-Harness nail it.
Run agents on tasks. Log traces. Feed ‘em to a coding agent. Boom—auto-suggests harness tweaks. We did this at LangSmith, juicing Deep Agents on Terminal Bench. Traces are gold; CLI tools make it dead simple.
This layer’s sneaky power: it’s code, so versionable, testable. No forgetting— just git commits. But companies hype it less. Why? Flashier to brag about ‘fine-tuned models.’ PR spin detected.
Here’s my unique take: harness evolution mirrors browser engines. Chrome didn’t retrain Chromium daily; it iterated the renderer loop. Agents will follow—harnesses becoming living codebases, updated weekly via trace-mining.
Users get custom harnesses? Possible, but org-level first. Scalable wins.
So. Context. The wildcard.
How Does Context Layer Learning Actually Work?
Context lives outside: CLAUDE.md, skills folders, mcp.json. Configures the harness on-the-fly. Memory, basically—but smart.
Agent-level: OpenClaw’s SOUL.md self-updates. Tenant-level: Hex’s Context Studio, Sierra’s Explorer. Mix ‘em—org memory + user tweaks.
Two paths: offline ‘dreaming’ (chew traces post-run), or hot-path (agent reflects mid-task). Explicit? User says ‘remember this.’ Implicit? Harness instructs it.
“Context” sits outside the harness and can be used to configure it. Context consists of things like instructions, skills, even tools. This is also commonly referred to as memory.
Dense dive: This layer scales cheapest—no retraining, just appends. But risks bloat; agents drown in their own history. Solution? Hierarchical memory—core facts pinned, ephemera pruned. We’re seeing prototypes in Decagon’s Duet.
Traces power it all. LangSmith collects ‘em; Prime Intellect trains models off ‘em. Harness tweaks? Skills CLI. Context? Dream jobs.
Prediction time: In 3 years, 80% of agent gains come from context. Models? Legacy. Harnesses? Elite tool.
But here’s the rub—what’s the glue?
Traces: The Unsung Hero of Agent Evolution
Every layer feasts on traces—full execution logs. No traces, no learning. Period.
Collect via LangSmith. Analyze. Iterate. It’s the flywheel.
Critique: Too many builders chase model hype, skipping traces. Dumb. Start here.
One sentence: Architectural shift incoming.
Wander a bit—remember Auto-GPT’s early days? Blind loops, no memory. Now? Layered learners. We’ve come far.
Why Does This Matter for AI Builders?
You’re smart; you get it. Single-layer thinking? Dead end. Multi-layer? Exponential gains.
OpenClaw dreams context. Meta-Harness evolves code. Models? When needed.
Callout: Corporate spin says ‘one model rules.’ Bull. Layers democratize learning—indies compete with labs.
Historical parallel: PC revolution. IBM mainframes monolithic; PCs modular. Agents go same way.
Build layered. Or fade.
🧬 Related Insights
- Read more: Intel’s Raccoon-Evicted Fab 9 Fuels Billion-Dollar Packaging Gambit
- Read more: AWS Frontier Agents: Autonomous Saviors or Expensive Hype?
Frequently Asked Questions
What is continual learning for AI agents?
It’s updating across model weights, harness code/tools, and external context/memory—avoiding forgetting while adapting.
How do you implement harness continual learning?
Log traces, feed to coding agent (e.g., via LangSmith), apply suggested code changes iteratively.
Why is context layer learning fastest to deploy?
No retraining needed—just append insights to configs like SOUL.md, offline or live.



