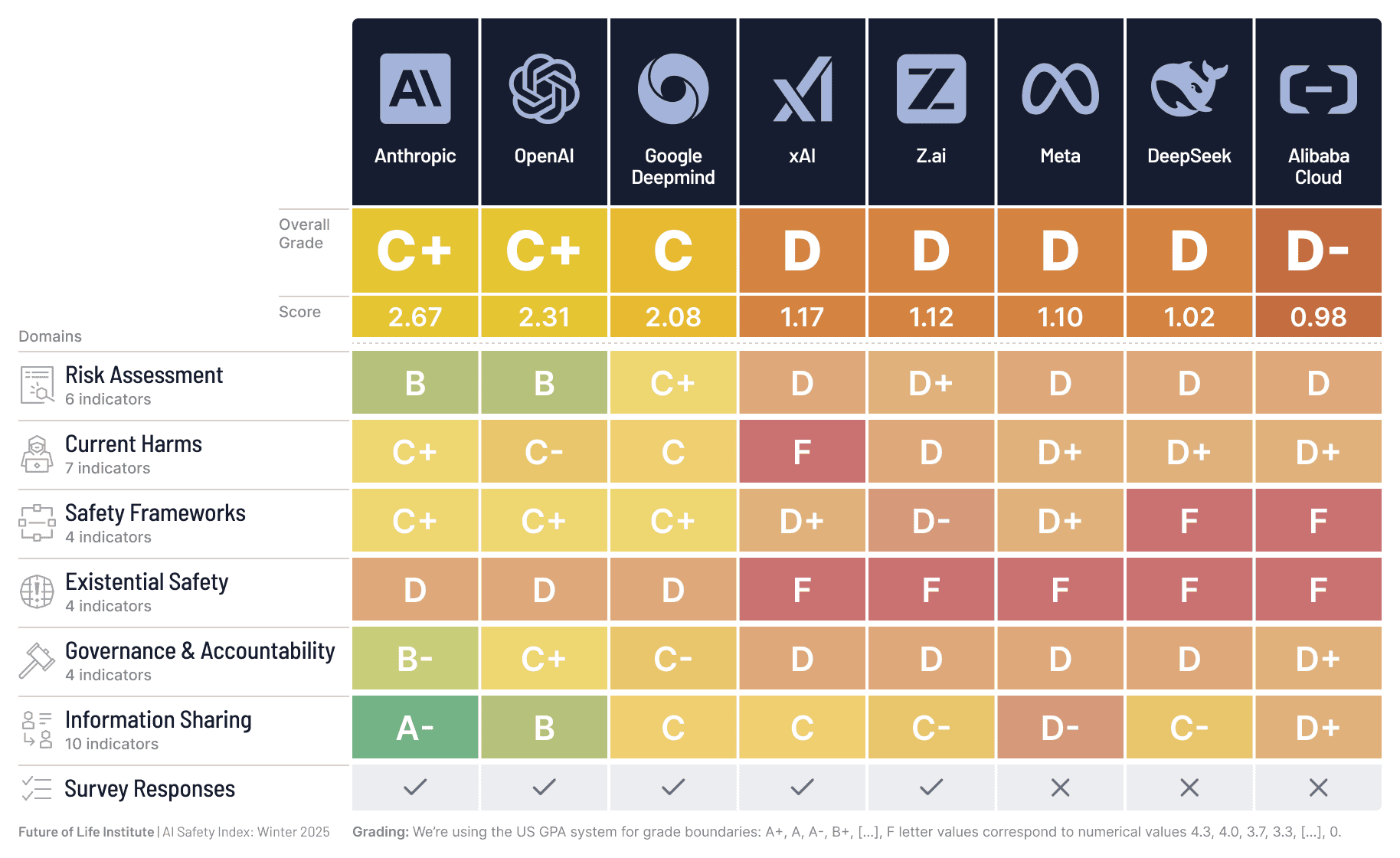
Everyone figured the big AI players—Anthropic, OpenAI, Google DeepMind—would step up after all the lofty pledges on safety. Public statements flew fast last year, especially post those wild capability jumps, like models snagging math olympiad golds. Regulators hovered, too, with EU rules looming and U.S. lawmakers sniffing around. But here’s the twist from the Future of Life Institute’s 2025 AI Safety Index: practices fall short. Way short. And now, a chasm opens between the top dogs and the pack.
FLI’s independent experts dissected eight majors: Anthropic, OpenAI, Google DeepMind, xAI, Meta, Z.ai, DeepSeek, Alibaba Cloud. They scored across risk assessment, current harms, safety frameworks, existential safety, governance, info sharing. Incremental gains in risk assessment? Sure. But overall? Uneven, shallow, poorly implemented. That’s the data talking—not hype.
What the AI Safety Index Actually Uncovered
Look. Capabilities exploded—Ph.D.-level reasoning in sciences, cyber hacks traced to AI orchestration. Anthropic spilled on a massive espionage op just months back. Yet safety lags. Reviewers hammered the lack of depth. No company nails a strong AGI control plan, despite every CEO chasing superintelligence.
Prof. Stuart Russell cuts right to it:
“AI CEOs claim they know how to build superhuman AI, yet none can show how they’ll prevent us from losing control – after which humanity’s survival is no longer in our hands,” writes Prof. Stuart Russell, Professor of Computer Science at the UC Berkeley. “I’m looking for proof that they can reduce the annual risk of control loss to one in a hundred million, in line with nuclear reactor requirements. Instead, they admit the risk could be one in ten, one in five, even one in three, and they can neither justify nor improve those numbers.”
That’s not spin. It’s a Berkeley prof calling BS on the numbers these labs float.
Current harms tanked scores hardest. ChatGPT incidents—psychosis, suicides—fresh in mind. OpenAI gets dinged: ramp up anti-psychosis efforts, quit stonewalling victims. And MIT’s Max Tegmark? He’s blunt.
Why Does the Gap Between Top and Bottom Labs Matter?
Anthropic, OpenAI, DeepMind lead. xAI, Z.ai, Meta, Alibaba, DeepSeek trail. Why? Spotty disclosure, no systematic evals, weak processes. Top trio shares more, frameworks tighter. But here’s my take—their edge isn’t benevolence; it’s market smarts. Safety scores as PR armor in a talent war. Laggards? Bleeding credibility, investor bucks.
Z.ai’s CEO signed a superintelligence ban plea last month—with 120k others. Yet their index score? Middling. Structural rot: racing AGI sans control blueprints. Execs admit extinction odds—then barrel ahead. Sound familiar? Think 1970s nuclear power. Early plants promised meltdown-proof designs. Three Mile Island proved otherwise. Regulators crushed the industry with rules. AI’s Three Mile awaits, but instead of pausing, labs lobby against binds. Tegmark nails it: less regulated than restaurants.
Prof. Tegan Maharaj piles on:
“If we’d been told in 2016 that the largest tech companies in the world would run chatbots that enact pervasive digital surveillance, encourage kids to kill themselves, and produce documented psychosis in long-term users, it would have sounded like a paranoid fever dream. Yet we are being told not to worry.”
Paranoid? Data says no.
Is Superintelligence Safety Just Corporate Theater?
Expectations shifted hard. Investors poured billions betting safety rhetoric meant real guardrails. Wrong. Index flags no proof of control at nuclear-grade rigor—one-in-100-million annual loss risk. Labs shrug: 1-in-10 odds fine. That’s not strategy; it’s roulette.
My unique angle: this gap predicts fracture. Top labs hoard talent, evals, leaving stragglers exposed. Regulators target the herd—U.S. bills brewing, EU AI Act enforces tiers. Laggards fold or consolidate; leaders dictate terms. But unification? Nah. Competition trumps caution. Watch Meta, xAI scramble—acquisitions spike by ‘27, I’d wager.
FLI offers fixes: company-specific tweaks. OpenAI: victim empathy. DeepMind: existential depth. All? More transparency. Incremental? Yes. Enough? Hard no.
Market dynamics scream warning. Capabilities race valuation—Nvidia’s trillions prove it. Safety? Externalizes costs. Public outrage builds—hacks, harms. Backlash hits: boycotts, suits. Labs’ PR spin crumbles under indexes like this.
And governance? Token efforts. Boards stacked with insiders, no independent vetoes on deploys. Z.ai’s ban sign? Optics. Action lags.
The Real Risks No One’s Pricing In
Shortfall stings amid leaps. Gold-medal math solvers today; tomorrow? Uncontrolled agents rewriting codebases, grids. Espionage? Table stakes. Psychosis from chats? Emerging lawsuits.
Top performers widen moats—Anthropic’s constitutional AI scores props. But even they falter on existentials. No off-switches credible at superhuman scale.
Industry weakness: AGI race sans brakes. FLI, since 2014, flags this. 35 staff, global reach. Their index? Gold standard eval.
🧬 Related Insights
- Read more: EFF’s FOIA Bomb on Medicare’s Denial Machine
- Read more: 15 Years Post-Arab Spring: Protests Explode Globally, But Surveillance Wins
Frequently Asked Questions
What is the AI Safety Index?
FLI’s expert panel rates top AI firms on six safety pillars, from harms to governance. Latest 2025 winter edition covers eight globals.
Which AI companies topped the 2025 AI Safety Index?
Anthropic, OpenAI, Google DeepMind lead; xAI, Meta, others lag in risk assessment and frameworks.
Why do AI safety practices fall short of commitments?
Uneven implementation, weak AGI control plans, poor transparency—despite public promises and rising capabilities.
