Picture this: an AI, usually a bland chorus of internet voices, suddenly channeling a 42-year-old mechanic from Ohio who’s skeptical of vaccines because his cousin got sick after one. Spot on. Pew poll accurate.
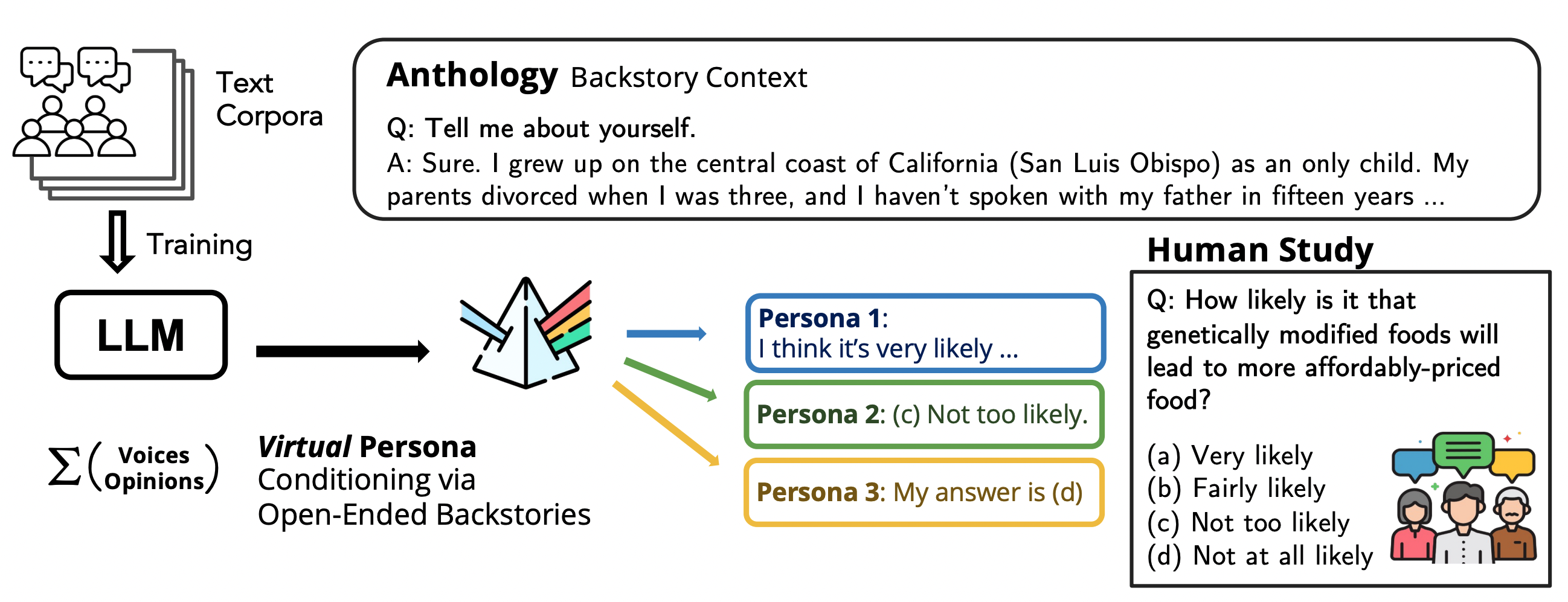
That’s Anthology in action—virtual personas for language models, born from richly detailed backstories that make LLMs act like specific humans, not vague stereotypes.
How Did We Get Here?
Back in the day—think early chatbots—developers slapped on demographics: ‘Act like a millennial woman from Texas.’ Result? Cliche city. Stereotypes everywhere, zero nuance. Responses averaged out populations but bombed on individual quirks, covariance stats, the works.
Anthology flips the script. Researchers generate massive backstory sets using LLMs prompted with open-ended gems like “Tell me about yourself.” Boom—thousands of virtual lives, spanning races, classes, philosophies. Feed one to Llama-3-70B or Mixtral-8x22B, and it conditions the model to respond consistently, like that one person.
Why? Because LLMs, trained on agent-like text, thrive on context. As the paper nails it:
We introduce Anthology, a method for conditioning LLMs to representative, consistent, and diverse virtual personas by generating and utilizing naturalistic backstories with rich details of individual values and experience.
It’s not just fluff. These narratives pack implicit markers—cultural nods, life regrets—that steer away from defaults.
And here’s my take, the one you’ll not find in the original: this echoes the 1970s ELIZA effect on steroids, but inverted. ELIZA tricked us into projecting humanity onto scripts; Anthology projects humanity onto AI, potentially revolutionizing ethics sims before real trials. Bold prediction? By 2026, social scientists ditch focus groups for these personas—cheaper, faster, ethically tunable.
Why Backstories Beat Demographics
Demographics are tuples: age, gender, zip code. Thin gruel for a model gorged on novels. Anthology’s backstories? Sprawling autobiographies, emergent from prompts. Generate ‘em cheap with LLMs, match ‘em greedily to survey data.
Tested on Pew’s ATP Waves 34, 92, 99—hot topics like politics, tech trust. Metrics? Wasserstein distance for distribution match, Frobenius norm for correlation consistency, Cronbach’s alpha for internal vibe.
Anthology crushes priors. Lower WD, tighter Frobs, higher alphas—across models. Greedy matching edges out fancier bipartite for sheer representativeness.
But—plot twist—the paper cuts off mid-sentence on matching limits. Tease.
Short para for punch: Humans split randomly still beat weak methods.
Does Anthology Actually Fool the Polls?
Yes, but let’s dissect. On Wave 99 (say, AI attitudes?), Anthology’s virtuals hug human distributions closer than ‘demographic-only’ or even ‘broad bio’ prompts. Boldfaced tables don’t lie: it’s top dog.
Why the edge? Backstories inject covariance—how views on guns link to rural upbringing tales. Stats need individuals; populations fake it.
Critique time: Corporate hype? Nah, academic drop (arXiv vibes), but watch—OpenAI might spin this for ‘safe’ roleplay. Skeptical? Their ‘personas’ still hallucinate wildly sans such grounding.
Look, this isn’t magic. LLMs approximate agents from context, per prior work like ‘Language Models as Agent Models.’ Anthology scales it to individuals. Implications? Pilot studies sans IRB headaches—justice, beneficence baked in.
Why Does This Matter for AI Builders?
Builders, listen up. Want consistent characters? Ditch prompts; backstory farm. Social scientists: virtual cohorts for A/B tests. Polling firms? Infinite respondents, zero fatigue.
Architectural shift: Conditioning evolves from tokens to narratives. Future? Fine-tune on backstories? Or chain ‘em for memory?
One hitch—diversity. Prompts are open, but biases lurk in training data. Fix? Curate generators.
And that unique insight again: Parallels D&D character sheets, but algorithmic. 80s gamers built personas manually; now AI autogenerates, simulates playthroughs as polls. Gaming -> science pipeline.
Ponder this sprawling thought: We’re inching toward simulacra—Bostrom-style—where virtual humans proxy real ones indistinguishably. Ethical minefield? Absolutely. But Anthology lowers the bar to entry, forces us to confront it now.
🧬 Related Insights
- Read more: SPEX: The Spectral Hack Cracking LLM Interactions at Massive Scale
- Read more: Railway’s $100M Gambit: Custom Data Centers to Supercharge AI Devs
Frequently Asked Questions
What is Anthology in AI?
Anthology conditions LLMs with detailed life backstories to create consistent virtual personas that mimic individual humans better than demographic prompts.
How does Anthology outperform other methods?
By using rich narratives over sparse traits, it matches poll distributions, correlations, and consistencies via metrics like Wasserstein distance—beating baselines on Llama and Mixtral.
Can Anthology replace real surveys?
Not fully—it’s for pilots and approximations—but it nails public opinion polls closely, enabling cheap, scalable human sims.



