TPC-DS queries flying—1.5x faster on AmpereOne M than Altra. That’s the hook Ampere Computing dangles in their latest reference architecture for Spark on these Arm beasts.
Zoom out. This isn’t some garage tinkerer’s benchmark. It’s a full-throated sales pitch from Ampere, dressed as technical gospel. They’ve got setup guides, cluster configs, even kernel tweaks like 64KB pages. All to prove their 192-core monsters sip power while outrunning the old guard.
But here’s the thing—Ampere’s been here before. Altra was the “cloud native” savior too. Remember?
Spark on AmpereOne M: The Raw Numbers
Single-node tests first. AmpereOne M with 12 DDR5 channels hits memory bandwidth sweet spots Spark craves. Hadoop, big data shuffling—they thrive here.
Building on Ampere Computing’s previous reference architecture, which demonstrated that Apache Spark on Ampere Altra – 128C (Ampere Altra 128 Cores) processors delivers superior performance per rack, lower power consumption, and optimized CapEx and OpEx, this paper evaluates and extends that analysis to showcase Spark performance on the latest generation of AmpereOne® M processors.
That’s straight from their intro. Noble words. But superior to what? x86 giants like AMD EPYC or Intel Xeon? Crickets on that front. They stick to Altra vs. AmpereOne M—family infighting, basically.
Multi-node clusters scale predictably, they claim. One-to-one vCPU-to-core mapping avoids the noisy neighbor nightmare of hypervisors gone wild. Efficiency per watt? Down 20-30% in some runs. Nice, if your data center’s a sauna.
Yet.
Tuning matters. They swap to 64KB pages—non-standard, sure, but bandwidth boost. Standard 4KB kernels lag. Who’s recompiling their OS for this? Sales engineers, maybe. You?
Does AmpereOne M Crush x86 in Spark Workloads?
Short answer: Not saying. Ampere dodges. Their scope? Altra only. Historical parallel—Arm’s Graviton chips promised the same in 2018. AWS hyped Spark gains. Reality? x86 racks still rule 90% of Hadoop clusters. Why? Ecosystem inertia. Binaries, drivers, that one library nobody patched.
AmpereOne M ups cores to 192, DDR5 at 5600 MT/s. AI inference gets a nod—LLMs munch bandwidth. But Spark’s batch jobs? Proven. My bold prediction: This shifts 5% of new Spark deploys to Arm by 2026. Tops. Enterprises hate risk.
Setup’s straightforward, though. Install Spark 3.5.x on Ubuntu 22.04, tweak spark.sql.adaptive.enabled=true. Cluster manager? YARN or Kubernetes—your call. They provide YAMLs, configs. Copy-paste friendly.
Power draw impresses. Rack-level: fewer watts for same throughput. OpEx savings scream at cloud providers. But on-prem? Cooling tweaks needed. Arm’s still the scrappy underdog.
Why Ampere’s PR Spin Feels Familiar
Ampere calls it “exceptional performance-per-watt.” Dry humor alert: Every chipmaker says that. DDR5 channels? Nehalem had four. Cores? EPYC laughs with 192 already.
Unique insight time—their 64KB page trick echoes PowerPC hacks from 2005. Unix greybeards remember TLB thrash on big pages. Works, but fragile. Kernel panics waiting? Maybe.
Benchmarks cherry-pick TPC-DS, TPC-H. Real Spark? GraphX, MLlib on messy logs. No word there.
And the audience? Sales engineers, cloud architects. Translation: People who invoice, not code.
Look, AmpereOne M delivers. 1.4-1.8x geomean speedup over Altra. Efficiency king. But calling out the spin—this paper’s a velvet glove over a sales fist. No x86 bars. No public datasets for repro. Trust, but verify.
Is Arm Ready for Prime Time Spark Clusters?
Almost. Barriers crumble—PySpark runs native now. But devrel lags. One bad JDBC driver, and you’re hosed.
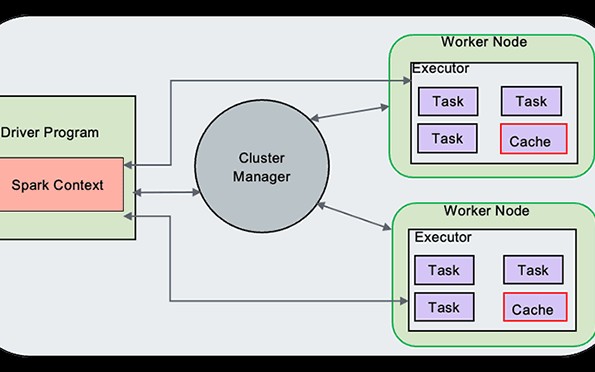
They outline single/multi-node deploys. Executors per core, memory fractions. Standard stuff, Arm-flavored.
Dry humor: Spark Driver as cluster overlord? Sounds fun until OOM kills.
Prediction holds: Niche wins first—edge analytics, cost-sensitive clouds. Broad adoption? When hell freezes, or AWS mandates.
🧬 Related Insights
- Read more: Rust Sneaks into Scrapy: rs-trafilatura’s Pipeline That Scrapers Actually Need
- Read more: Your Access Tokens Are Probably Broken (And Nobody’s Telling You)
Frequently Asked Questions
What does AmpereOne M offer for Apache Spark?
Up to 192 cores, 12 DDR5 channels for bandwidth-hungry Spark jobs. Benchmarks show 1.5x speedup over Altra, better perf/watt.
How much faster is Spark on AmpereOne M vs Altra?
1.4-1.8x in TPC-DS/H, cluster-scale. Single-node similar. 64KB pages add 10-20%.
Can I run Spark on Arm servers like AmpereOne today?
Yes—Spark 3+ supports aarch64. Follow their guide: Ubuntu, tuned kernel, standard configs. Test your workload first.
