It’s 2 AM, pager buzzing — another Spark job’s OOM’d out after four hours of loyal service.
Pinterest Spark OOM failures used to be that nightmare, the kind that turns data engineers into zombies. They’ve slashed them by 96% now, thanks to observability hacks, config tweaks, and — get this — auto memory retries. Sounds straightforward? It should’ve been years ago.
But here’s the thing. For years, these failures wrecked pipelines, spiked on-call hell, and stalled the recommendation magic powering Pinterest’s endless scroll. Jobs would crawl to 99%, then splat. Manual tweaks? Sure, if you like playing whack-a-mole at midnight.
Why Did Spark OOMs Plague Pinterest for So Long?
Lack of eyes on the problem. No granular metrics on executor memory, shuffles gobbling RAM, tasks dragging forever. Blind firefighting.
They built dashboards. Tracked hotspots, skew, greedy stages. Suddenly, problems had addresses. As Pinterest’s engineers put it:
understanding where memory is consumed within a job is critical to addressing failures effectively.
Spot on. No more guessing — just scalpels, not sledgehammers.
Tuning came next. Spark configs for memory fractions, shuffle partitions, broadcast joins — optimized for their workloads. Adaptive query execution? Dynamically resizing partitions mid-flight, easing memory squeezes. Preprocessing smoothed skew; checks caught fat datasets early. High-risk jobs? Still got human eyes. Smart.
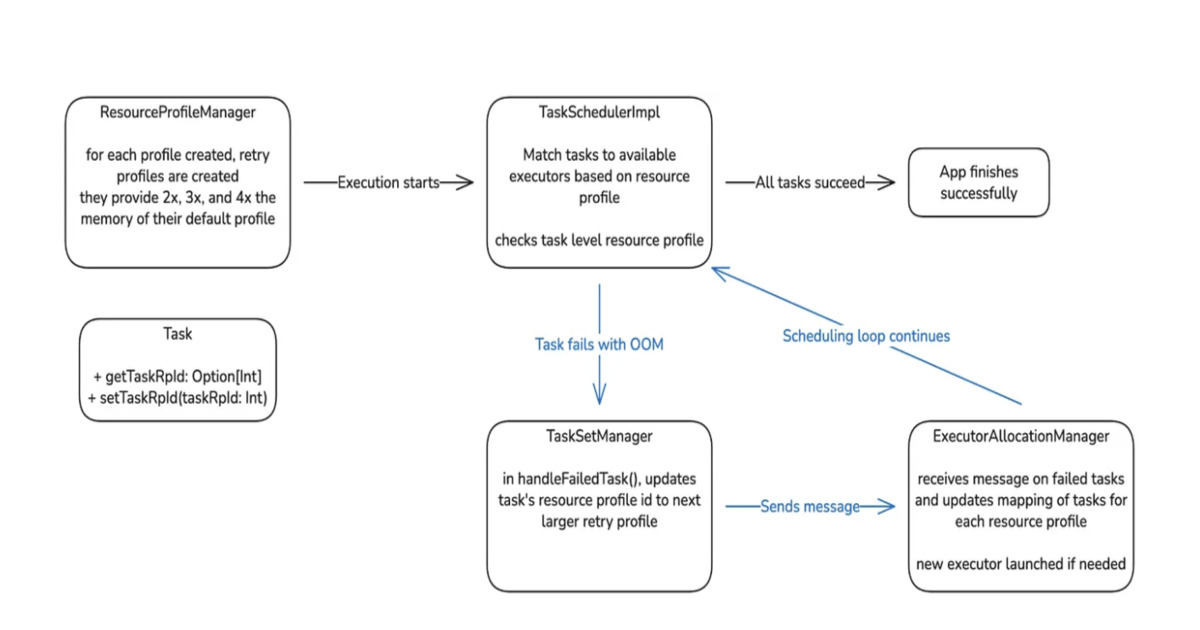
And the star: Auto Memory Retries. Fail on OOM? Restart with bumped memory, no code changes. Poof — manual toil vanishes. Pipelines chug on.
Rollout? Cautious geniuses. Ad-hoc jobs first, 0 to 100%. Then scheduled, low-priority up. Dashboards watched recoveries, savings in MB, vCores, post-retry bombs. Caught gremlins early.
Lessons? Scheduler choked on big TaskSets — fixed. Custom profiles for Apache Gluten? Handled. Host failures blocking retries? Nope, tuned out.
Can Auto Memory Retries Fix Your Spark Mess Too?
Don’t get starry-eyed. This isn’t magic; it’s engineering 101 done right. Pinterest’s scale — memory-heavy recsys, massive data — amplified the pain, but your jobs might hum already.
Still, unique insight: this echoes Hadoop’s early days, when YARN brought auto-scaling and retries, taming the wild west of batch jobs. Spark’s next? I predict auto retries land in core Spark 4.x, courtesy Pinterest’s push. Open source gonna open source.
Corporate spin? Minimal here — Pinterest’s blog is refreshingly geeky, metrics-first. No “revolutionary” fluff. Just numbers: 96% drop. On-call load crushed. Costs saved.
But — em-dash alert — is it enough? Future plans tease proactive memory bumps for risky stages. No more retries needed. Cluster efficiency skyrockets.
Skeptical me wonders: why’d it take this long? Spark’s been OOM-prone since 2014. Pinterest admits workflow shifts were key, not just tech. Humans hate change.
Look. If you’re running Spark at scale, steal this. Observability first — it’s free insight. Then tune. Automate retries — or build ‘em.
Pinterest proves it: reliability isn’t glamour; it’s blocking dumb failures so you build features. Dry humor: their on-call team’s probably throwing a party. Quietly.
One-paragraph rant: Big tech loves bragging post-fix, but small teams suffer silently. This blueprint’s gold — share it, don’t hoard.
Deeper dive. Skewed partitions? Preprocessing magic: salting keys, sampling. Validation gates: “This dataset’s a whale — abort.” Human review for critters? Yes, until trust builds.
Gluten nod — off-heap vectorized exec — shows they’re future-proofing. But custom profiles meant scheduler tweaks; don’t assume plug-and-play.
Cost angle. Recovered jobs mean vCore-hours saved, not wasted. At Pinterest scale? Millions. Your mileage? Positive.
Why Does This Matter for Spark Users Everywhere?
Scale hits everyone eventually. Recsys, ETL, analytics — memory hogs lurk.
Prediction bold: OSS community adopts. Spark contrib? Fork it. Pinterest’s staged rollout? Textbook — envy that discipline.
Humor break. Imagine Spark UI with “Retry with More RAM? Y/N”. One-click sanity.
Critique time. Past manual era? Lazy. Observability deficit? Criminal at scale. They’re owning it now.
Wrapping threads. This isn’t hype — it’s battle-tested. 96%. Believe it.
🧬 Related Insights
- Read more: How a Docker Engineer Built a Local News Bot That Doesn’t Drain Your AI Budget
- Read more: Freestyle Sandboxes: Taming Wild AI Coders Before They Wreck Your Repo
Frequently Asked Questions
How did Pinterest reduce Spark OOM failures by 96%?
Better metrics, config tuning, and auto memory retries that restart failed jobs with more RAM.
What are Spark auto memory retries?
Automatic restarts of OOM-killed jobs with increased memory settings, no code changes needed.
Will Pinterest’s Spark fixes work for my jobs?
Likely, if you’re hitting memory walls — start with observability and tuning.
