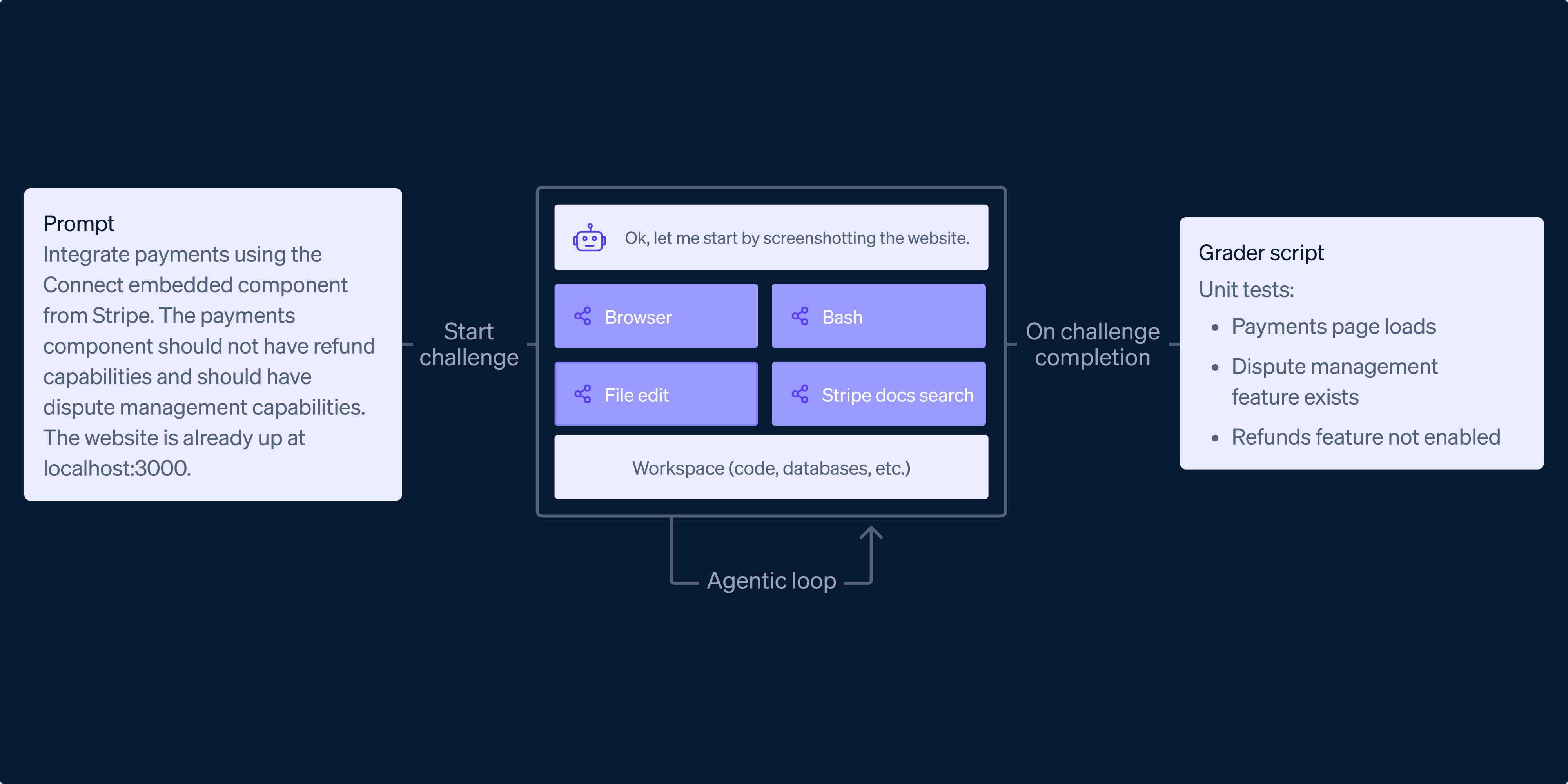
What happens when you sic an AI agent on a Stripe integration — and watch it fumble the ball right at the goal line?
That’s the dirty secret behind the latest Stripe integration benchmark. State-of-the-art LLMs crush toy coding problems, sure. But real Stripe work? Payments demand perfection, not “mostly right.” One glitch, and your business bleeds cash. Researchers built this beast to probe: can agents plan, code, test, and ship a full integration autonomously?
Spoiler for the optimists: nope.
Why Stripe? The Ultimate AI Reality Check
Stripe’s API is developer catnip — clean, documented, battle-tested. If AI can’t nail this, what hope for messier enterprise nightmares? The benchmark mirrors actual pain points: migrating checkouts, tweaking subscriptions, handling API版本 shifts. Eleven environments, each a mini-hellscape of codebases, databases, browsers.
They threw in graders — automated tests that poke the finished product via APIs, UI scripts, even Stripe dashboard artifacts. Agents get a harness: terminal, browser, Stripe search tools. Sounds fair. But here’s the rub: real engineering isn’t a sandbox. It’s debugging at 2 AM, state persistence across failures, glue code nobody writes about.
Real-world software engineering is a long-horizon activity that requires planning, persistent state management, and recovery from failure.
Nailed it. That’s from the benchmark creators themselves. And boy, do models trip over that horizon.
Backend tasks? Agents manage data migrations, API updates. Decent scores there — models grok Stripe docs, spit out correct server code. Full-stack? Disaster zone. Browser wrangling, frontend hooks, database syncs — agents navigate UIs (sometimes), debug live bugs (barely), but verification? They hallucinate success.
Gym sets push depth: custom shipping in Checkout, trial tweaks in Billing. Models flail on edge cases, assuming happy paths that never exist.
One short para: Hype busted.
But let’s unpack the construction — because building this benchmark took engineer sweat comparable to the tasks themselves. Full repos, test keys, MCP servers. They biased for hardness, stumping even mid-2025 SOTA models. Expected backend wins, full-stack losses. Got that. And more: agents excel at isolated code gen, crater on orchestration.
Here’s my unique twist, absent from their report: this echoes the 2016 AlphaGo hype. AI crushes Go — narrow, perfect info. But software engineering? It’s Go on a board that shifts mid-game, with fog of war and exploding pieces. Predictions? Agents won’t ship production integrations solo for years. They’ll augment — fetch docs, stub code — but the captain’s chair stays human.
Can AI Agents Actually Build Stripe Integrations?
Short answer: partially. Backend-only: 60-70% pass rates on basics, per their evals (cut off in the teaser, but trends clear). Full-stack: sub-30%, guessing from “struggle” vibes. Gyms expose shallowness — advanced configs demand nuanced API grasp models fake.
Why the gap? Planning horizons too long. Agents lose state over steps, can’t recover from test failures gracefully. Browser use? Clunky — they click wrong, misread DOM, bail. And PR spin alert: Stripe’s team calls it “production-realistic.” Cute. But any benchmark is artificial; real integrations tangle with auth, compliance, scale.
Look, corporate hype loves “agents will change dev forever.” This benchmark calls bullshit — politely. It’s glue work that kills: package updates, DB migrations, end-to-end browser validation. Models generate code. Humans verify reality.
And the harness? Goose-based, consistent. But tools like browser control lag human finesse. Agents search docs — great! — but misapply to context.
So. Progress, yes. Autonomy, no.
Why Does This Matter for Developers?
You’re a dev eyeing AI sidekicks. This benchmark screams: use ‘em for boilerplate, not black-box builds. Stripe integrations demand 100% — one failed payment session, and trust evaporates. Agents hallucinate passing tests; graders catch some, but not sneaky races or prod quirks.
Bold call: by 2027, hybrid workflows rule. Agent proposes integration skeleton; you audit, test, deploy. Full autonomy? Dream on — until models grok business logic, not just syntax.
Critique time. Stripe’s engineers built strong challenges — kudos. But fewer tasks mean noisy stats. Replicability? Envs are complex; drift happens. Still, first-of-kind for API agents. Pushes field forward, even if results sting.
Dry humor interlude: Imagine your AI agent submitting a payment flow that creates ghost subscriptions. Customers rage. You debug. Classic Monday.
Deeper dive — categories breakdown. Backend: agents shine on scripted tasks, falter on versions (API changes trip ‘em). Full-stack: UI tests expose fragility; one DOM fluke, cascade fails. Gyms: depth illusion shattered — Checkout basics ok, shipping rates? Nope.
Unique parallel: Remember GitHub Copilot’s 2021 launch? Hype as code revolution. Reality: autocomplete on steroids. This benchmark’s Devin 2.0 moment — agents hype, delivery gaps.
The Harsh Truth on Agentic Dev
Measurements trick us. Code gen metrics (pass@1) lie for long tasks. Execution matters — does it run, pay out, scale? Benchmark graders enforce that, via API probes and Stripe object checks. Smart.
But ambiguity kills: tasks “realistic” means fuzzy edges. Agents over- or under-engineer. Human rigor? Absent.
Wrapping the sarcasm — this isn’t doom. It’s calibration. AI accelerates, doesn’t replace. Stripe benchmark sets bar high; models climb slowly.
Frequently Asked Questions
What is the Stripe integration benchmark?
It’s 11 environments testing AI agents on full-stack Stripe tasks — backend, frontend, verification — with auto-graders for real-world rigor.
Can AI agents build complete Stripe integrations?
Not yet — they handle code but flop on glue work, browser testing, and failure recovery.
Will AI replace software engineers for payments?
No way. They’ll assist grunt work; humans own verification and orchestration.
Will this benchmark evolve?
Likely — as models improve, expect tougher tasks to keep exposing gaps.
